

Add fusion (#3)
Browse files* vectorize and optimized block reduce
* add benchmark test (w/o readme update)
* implemented fused_mul_poly_norm
Signed-off-by: taehyun <[email protected]>
* add_rms_norm added
* deleted backward pass on fused add rms norm, split test and benchmarks
Signed-off-by: taehyun <[email protected]>
* refactored benchmarks
* add readme
* fix readme
* add build
* fix readme
* fix readme2
* add mi250 results
* highlight used our kernel for baseline in fused performance
* applied yapf
---------
Signed-off-by: taehyun <[email protected]>
Co-authored-by: taehyun <[email protected]>
This view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +178 -7
- activation/block_reduce.h +0 -21
- activation/fused_add_rms_norm.cu +157 -0
- activation/fused_mul_poly_norm.cu +642 -0
- activation/poly_norm.cu +88 -61
- activation/rms_norm.cu +243 -51
- benchmarks/README.md +35 -0
- benchmarks/cases/__init__.py +1 -0
- benchmarks/cases/add_rms.py +55 -0
- benchmarks/cases/mul_poly.py +53 -0
- benchmarks/cases/poly.py +58 -0
- benchmarks/cases/rms.py +35 -0
- benchmarks/common/__init__.py +1 -0
- benchmarks/common/bench_framework.py +220 -0
- benchmarks/common/diff_engine.py +85 -0
- benchmarks/plots/h100/add_rms/plot_add_rms-bwd-perf.png +0 -0
- benchmarks/plots/h100/add_rms/plot_add_rms-fwd-perf.png +0 -0
- benchmarks/plots/h100/mul_poly/plot_mul_poly-bwd-perf.png +0 -0
- benchmarks/plots/h100/mul_poly/plot_mul_poly-fwd-perf.png +0 -0
- benchmarks/plots/h100/poly/plot_poly-bwd-perf.png +0 -0
- benchmarks/plots/h100/poly/plot_poly-fwd-perf.png +0 -0
- benchmarks/plots/h100/rms/plot_rms-bwd-perf.png +0 -0
- benchmarks/plots/h100/rms/plot_rms-fwd-perf.png +0 -0
- benchmarks/plots/mi250/add_rms/plot_add_rms-bwd-perf.png +0 -0
- benchmarks/plots/mi250/add_rms/plot_add_rms-fwd-perf.png +0 -0
- benchmarks/plots/mi250/mul_poly/plot_mul_poly-bwd-perf.png +0 -0
- benchmarks/plots/mi250/mul_poly/plot_mul_poly-fwd-perf.png +0 -0
- benchmarks/plots/mi250/poly/plot_poly-bwd-perf.png +0 -0
- benchmarks/plots/mi250/poly/plot_poly-fwd-perf.png +0 -0
- benchmarks/plots/mi250/rms/plot_rms-bwd-perf.png +0 -0
- benchmarks/plots/mi250/rms/plot_rms-fwd-perf.png +0 -0
- benchmarks/run_cases.py +143 -0
- build.toml +4 -2
- build/torch27-cxx11-cu118-x86_64-linux/activation/__init__.py +24 -2
- tests/perf.png → build/torch27-cxx11-cu118-x86_64-linux/activation/_activation_20250907180255.abi3.so +2 -2
- build/torch27-cxx11-cu118-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu118-x86_64-linux/activation/layers.py +48 -2
- build/torch27-cxx11-cu118-x86_64-linux/activation/poly_norm.py +37 -0
- build/torch27-cxx11-cu118-x86_64-linux/activation/rms_norm.py +47 -0
- build/torch27-cxx11-cu126-x86_64-linux/activation/__init__.py +24 -2
- build/torch27-cxx11-cu126-x86_64-linux/activation/_activation_20250907180255.abi3.so +3 -0
- build/torch27-cxx11-cu126-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu126-x86_64-linux/activation/layers.py +48 -2
- build/torch27-cxx11-cu126-x86_64-linux/activation/poly_norm.py +37 -0
- build/torch27-cxx11-cu126-x86_64-linux/activation/rms_norm.py +47 -0
- build/torch27-cxx11-cu128-x86_64-linux/activation/__init__.py +24 -2
- build/torch27-cxx11-cu128-x86_64-linux/activation/_activation_20250907180255.abi3.so +3 -0
- build/torch27-cxx11-cu128-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu128-x86_64-linux/activation/layers.py +48 -2
- build/torch27-cxx11-cu128-x86_64-linux/activation/poly_norm.py +37 -0
README.md
CHANGED
|
@@ -11,6 +11,37 @@ Activation is a python package that contains custom CUDA-based activation kernel
|
|
| 11 |
- Currently implemented
|
| 12 |
- [PolyNorm](https://arxiv.org/html/2411.03884v1)
|
| 13 |
- [RMSNorm](https://docs.pytorch.org/docs/stable/generated/torch.nn.RMSNorm.html)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
## Usage
|
| 16 |
|
|
@@ -28,18 +59,158 @@ print(poly_norm(x))
|
|
| 28 |
```
|
| 29 |
|
| 30 |
## Performance
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
### PolyNorm
|
| 33 |
|
| 34 |
-
|
| 35 |
-
- You can reproduce the results with:
|
| 36 |
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
|
| 42 |
-
|
| 43 |
|
| 44 |
## Pre-commit Hooks
|
| 45 |
|
|
|
|
| 11 |
- Currently implemented
|
| 12 |
- [PolyNorm](https://arxiv.org/html/2411.03884v1)
|
| 13 |
- [RMSNorm](https://docs.pytorch.org/docs/stable/generated/torch.nn.RMSNorm.html)
|
| 14 |
+
- **FusedAddRMSNorm**
|
| 15 |
+
|
| 16 |
+
A fused operator that combines **residual addition** (`x + residual`) with **RMSNorm** in a single kernel.
|
| 17 |
+
- Instead of:
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
y = x + residual
|
| 21 |
+
out = rms_norm(y, weight, eps)
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
- Fused as:
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
out = fused_add_rms_norm(x, residual, weight, eps)
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
- **FusedMulPolyNorm**
|
| 31 |
+
|
| 32 |
+
A fused operator that combines **PolyNorm** with an **element-wise multiplication** by a Tensor.
|
| 33 |
+
- Instead of:
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
y = poly_norm(x, weight, bias, eps)
|
| 37 |
+
out = y * a
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
- Fused as:
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
out = fused_mul_poly_norm(x, a, weight, bias, eps)
|
| 44 |
+
```
|
| 45 |
|
| 46 |
## Usage
|
| 47 |
|
|
|
|
| 59 |
```
|
| 60 |
|
| 61 |
## Performance
|
| 62 |
+
- Test cases are from the Motif LLM
|
| 63 |
+
- The results can be reproduced using the provided benchmarking tools.
|
| 64 |
+
- For details on how to use the benchmarking tools, please refer to the [benchmarks README](./benchmarks/README.md).
|
| 65 |
+
- The benchmark results may show fluctuations, especially in the backward pass and when the dimension size is small.
|
| 66 |
+
|
| 67 |
+
### RMSNorm
|
| 68 |
+
|
| 69 |
+
#### H100 Results
|
| 70 |
+
|
| 71 |
+
<details>
|
| 72 |
+
<summary>Forward Performance</summary>
|
| 73 |
+
|
| 74 |
+

|
| 75 |
+
|
| 76 |
+
</details>
|
| 77 |
+
|
| 78 |
+
<details>
|
| 79 |
+
<summary>Backward Performance</summary>
|
| 80 |
+
|
| 81 |
+

|
| 82 |
+
|
| 83 |
+
</details>
|
| 84 |
+
|
| 85 |
+
#### MI250 Results
|
| 86 |
+
|
| 87 |
+
<details>
|
| 88 |
+
<summary>Forward Performance</summary>
|
| 89 |
+
|
| 90 |
+

|
| 91 |
+
|
| 92 |
+
</details>
|
| 93 |
+
|
| 94 |
+
<details>
|
| 95 |
+
<summary>Backward Performance</summary>
|
| 96 |
+
|
| 97 |
+

|
| 98 |
+
|
| 99 |
+
</details>
|
| 100 |
+
|
| 101 |
+
---
|
| 102 |
+
|
| 103 |
+
### FusedAddRMSNorm
|
| 104 |
+
|
| 105 |
+
> [!NOTE]
|
| 106 |
+
> For fusion case performance, the **non-fused baseline** was implemented with our **custom kernels**.
|
| 107 |
+
|
| 108 |
+
#### H100 Results
|
| 109 |
+
|
| 110 |
+
<details>
|
| 111 |
+
<summary>Forward Performance</summary>
|
| 112 |
+
|
| 113 |
+

|
| 114 |
+
|
| 115 |
+
</details>
|
| 116 |
+
|
| 117 |
+
<details>
|
| 118 |
+
<summary>Backward Performance</summary>
|
| 119 |
+
|
| 120 |
+

|
| 121 |
+
|
| 122 |
+
</details>
|
| 123 |
+
|
| 124 |
+
#### MI250 Results
|
| 125 |
+
|
| 126 |
+
<details>
|
| 127 |
+
<summary>Forward Performance</summary>
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
</details>
|
| 132 |
+
|
| 133 |
+
<details>
|
| 134 |
+
<summary>Backward Performance</summary>
|
| 135 |
+
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
</details>
|
| 139 |
+
|
| 140 |
+
---
|
| 141 |
|
| 142 |
### PolyNorm
|
| 143 |
|
| 144 |
+
#### H100 Results
|
|
|
|
| 145 |
|
| 146 |
+
<details>
|
| 147 |
+
<summary>Forward Performance</summary>
|
| 148 |
+
|
| 149 |
+

|
| 150 |
+
|
| 151 |
+
</details>
|
| 152 |
+
|
| 153 |
+
<details>
|
| 154 |
+
<summary>Backward Performance</summary>
|
| 155 |
+
|
| 156 |
+

|
| 157 |
+
|
| 158 |
+
</details>
|
| 159 |
+
|
| 160 |
+
#### MI250 Results
|
| 161 |
+
|
| 162 |
+
<details>
|
| 163 |
+
<summary>Forward Performance</summary>
|
| 164 |
+
|
| 165 |
+

|
| 166 |
+
|
| 167 |
+
</details>
|
| 168 |
+
|
| 169 |
+
<details>
|
| 170 |
+
<summary>Backward Performance</summary>
|
| 171 |
+
|
| 172 |
+

|
| 173 |
+
|
| 174 |
+
</details>
|
| 175 |
+
|
| 176 |
+
---
|
| 177 |
+
|
| 178 |
+
### FusedMulPolyNorm
|
| 179 |
+
|
| 180 |
+
> [!NOTE]
|
| 181 |
+
> For fusion case performance, the **non-fused baseline** was implemented with our **custom kernels**.
|
| 182 |
+
|
| 183 |
+
#### H100 Results
|
| 184 |
+
|
| 185 |
+
<details>
|
| 186 |
+
<summary>Forward Performance</summary>
|
| 187 |
+
|
| 188 |
+

|
| 189 |
+
|
| 190 |
+
</details>
|
| 191 |
+
|
| 192 |
+
<details>
|
| 193 |
+
<summary>Backward Performance</summary>
|
| 194 |
+
|
| 195 |
+

|
| 196 |
+
|
| 197 |
+
</details>
|
| 198 |
+
|
| 199 |
+
#### MI250 Results
|
| 200 |
+
|
| 201 |
+
<details>
|
| 202 |
+
<summary>Forward Performance</summary>
|
| 203 |
+
|
| 204 |
+

|
| 205 |
+
|
| 206 |
+
</details>
|
| 207 |
+
|
| 208 |
+
<details>
|
| 209 |
+
<summary>Backward Performance</summary>
|
| 210 |
+
|
| 211 |
+

|
| 212 |
|
| 213 |
+
</details>
|
| 214 |
|
| 215 |
## Pre-commit Hooks
|
| 216 |
|
activation/block_reduce.h
DELETED
|
@@ -1,21 +0,0 @@
|
|
| 1 |
-
namespace motif {
|
| 2 |
-
|
| 3 |
-
template <typename acc_t, int BLOCK_SIZE>
|
| 4 |
-
__device__ acc_t _block_reduce_sum(acc_t *shared, const float val,
|
| 5 |
-
const int d) {
|
| 6 |
-
// TODO: Optimize with warp-level primitives
|
| 7 |
-
__syncthreads();
|
| 8 |
-
|
| 9 |
-
shared[threadIdx.x] = threadIdx.x < d ? val : 0.0f;
|
| 10 |
-
__syncthreads();
|
| 11 |
-
for (int stride = BLOCK_SIZE / 2; stride > 0; stride /= 2) {
|
| 12 |
-
if (threadIdx.x < stride) {
|
| 13 |
-
shared[threadIdx.x] += shared[threadIdx.x + stride];
|
| 14 |
-
}
|
| 15 |
-
__syncthreads();
|
| 16 |
-
}
|
| 17 |
-
|
| 18 |
-
return shared[0];
|
| 19 |
-
}
|
| 20 |
-
|
| 21 |
-
} // namespace motif
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
activation/fused_add_rms_norm.cu
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <ATen/Functions.h>
|
| 2 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 3 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 4 |
+
#include <torch/all.h>
|
| 5 |
+
|
| 6 |
+
#include <cmath>
|
| 7 |
+
|
| 8 |
+
#include "assert_utils.h"
|
| 9 |
+
#include "atomic_utils.h"
|
| 10 |
+
#include "cuda_compat.h"
|
| 11 |
+
#include "dispatch_utils.h"
|
| 12 |
+
|
| 13 |
+
namespace motif {
|
| 14 |
+
|
| 15 |
+
template <typename type, int N> struct alignas(sizeof(type) * N) type_vec_t {
|
| 16 |
+
type data[N];
|
| 17 |
+
};
|
| 18 |
+
|
| 19 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 20 |
+
__global__ std::enable_if_t<(width > 0)>
|
| 21 |
+
fused_add_rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 22 |
+
scalar_t *__restrict__ add_out, // [..., d]
|
| 23 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 24 |
+
const scalar_t *__restrict__ residual, // [..., d]
|
| 25 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 26 |
+
const float eps, const int d) {
|
| 27 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 28 |
+
|
| 29 |
+
const int vec_d = d / width;
|
| 30 |
+
const int64_t vec_offset = blockIdx.x * vec_d;
|
| 31 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 32 |
+
const vec_t *__restrict__ residual_vec =
|
| 33 |
+
reinterpret_cast<const vec_t *>(residual);
|
| 34 |
+
vec_t *__restrict__ add_out_vec = reinterpret_cast<vec_t *>(add_out);
|
| 35 |
+
acc_t sum_square = 0.0f;
|
| 36 |
+
|
| 37 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 38 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 39 |
+
vec_t res_vec = residual_vec[vec_offset + idx];
|
| 40 |
+
vec_t add_vec;
|
| 41 |
+
|
| 42 |
+
#pragma unroll
|
| 43 |
+
for (int i = 0; i < width; ++i) {
|
| 44 |
+
acc_t x = x_vec.data[i] + res_vec.data[i];
|
| 45 |
+
sum_square += x * x;
|
| 46 |
+
add_vec.data[i] = x;
|
| 47 |
+
}
|
| 48 |
+
add_out_vec[vec_offset + idx] = add_vec;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
using BlockReduce = cub::BlockReduce<float, 1024>;
|
| 52 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 53 |
+
|
| 54 |
+
sum_square = BlockReduce(reduceStore).Sum(sum_square, blockDim.x);
|
| 55 |
+
|
| 56 |
+
__shared__ acc_t s_scale;
|
| 57 |
+
|
| 58 |
+
if (threadIdx.x == 0) {
|
| 59 |
+
s_scale = rsqrtf(sum_square / d + eps);
|
| 60 |
+
}
|
| 61 |
+
__syncthreads();
|
| 62 |
+
|
| 63 |
+
const vec_t *__restrict__ weight_vec =
|
| 64 |
+
reinterpret_cast<const vec_t *>(weight);
|
| 65 |
+
vec_t *__restrict__ output_vec = reinterpret_cast<vec_t *>(out);
|
| 66 |
+
|
| 67 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 68 |
+
vec_t x_vec = add_out_vec[vec_offset + idx];
|
| 69 |
+
vec_t w_vec = weight_vec[idx];
|
| 70 |
+
vec_t y_vec;
|
| 71 |
+
|
| 72 |
+
#pragma unroll
|
| 73 |
+
for (int i = 0; i < width; ++i) {
|
| 74 |
+
acc_t x = x_vec.data[i];
|
| 75 |
+
acc_t w = w_vec.data[i];
|
| 76 |
+
|
| 77 |
+
y_vec.data[i] = w * x * s_scale;
|
| 78 |
+
}
|
| 79 |
+
output_vec[vec_offset + idx] = y_vec;
|
| 80 |
+
}
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 84 |
+
__global__ std::enable_if_t<(width == 0)>
|
| 85 |
+
fused_add_rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 86 |
+
scalar_t *__restrict__ add_out, // [..., d]
|
| 87 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 88 |
+
const scalar_t *__restrict__ residual, // [..., d]
|
| 89 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 90 |
+
const float eps, const int d) {
|
| 91 |
+
const int64_t token_idx = blockIdx.x;
|
| 92 |
+
const int64_t vec_idx = threadIdx.x;
|
| 93 |
+
acc_t sum_square = 0.0f;
|
| 94 |
+
|
| 95 |
+
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 96 |
+
acc_t x = input[token_idx * d + idx] + residual[token_idx * d + idx];
|
| 97 |
+
sum_square += x * x;
|
| 98 |
+
add_out[token_idx * d + idx] = x;
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
using BlockReduce = cub::BlockReduce<float, 1024>;
|
| 102 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 103 |
+
|
| 104 |
+
sum_square = BlockReduce(reduceStore).Sum(sum_square, blockDim.x);
|
| 105 |
+
|
| 106 |
+
__shared__ acc_t s_scale;
|
| 107 |
+
|
| 108 |
+
if (vec_idx == 0) {
|
| 109 |
+
s_scale = rsqrtf(sum_square / d + eps);
|
| 110 |
+
}
|
| 111 |
+
__syncthreads();
|
| 112 |
+
|
| 113 |
+
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 114 |
+
acc_t x = add_out[token_idx * d + idx];
|
| 115 |
+
acc_t w = weight[idx];
|
| 116 |
+
out[token_idx * d + idx] = w * x * s_scale;
|
| 117 |
+
}
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
} // namespace motif
|
| 121 |
+
|
| 122 |
+
#define LAUNCH_RMS_NORM(width) \
|
| 123 |
+
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 124 |
+
input.scalar_type(), "fused_add_rms_norm_kernel", [&] { \
|
| 125 |
+
motif::fused_add_rms_norm_kernel<scalar_t, float, width> \
|
| 126 |
+
<<<grid, block, 0, stream>>>( \
|
| 127 |
+
out.data_ptr<scalar_t>(), add_out.data_ptr<scalar_t>(), \
|
| 128 |
+
input.data_ptr<scalar_t>(), residual.data_ptr<scalar_t>(), \
|
| 129 |
+
weight.data_ptr<scalar_t>(), eps, d); \
|
| 130 |
+
});
|
| 131 |
+
|
| 132 |
+
void fused_add_rms_norm(torch::Tensor &out, // [..., d]
|
| 133 |
+
torch::Tensor &add_out, // [..., d]
|
| 134 |
+
const torch::Tensor &input, // [..., d]
|
| 135 |
+
const torch::Tensor &residual, // [..., d]
|
| 136 |
+
const torch::Tensor &weight, // [d]
|
| 137 |
+
double eps) {
|
| 138 |
+
AssertTensorShapeEqual(input, residual, "input", "residual");
|
| 139 |
+
AssertTensorShapeEqual(input, out, "input", "out");
|
| 140 |
+
AssertTensorShapeEqual(input, add_out, "input", "result");
|
| 141 |
+
AssertTensorNotNull(weight, "weight");
|
| 142 |
+
// TODO shape check
|
| 143 |
+
|
| 144 |
+
int d = input.size(-1);
|
| 145 |
+
int64_t num_tokens = input.numel() / input.size(-1);
|
| 146 |
+
dim3 grid(num_tokens);
|
| 147 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 148 |
+
dim3 block(std::min(d, max_block_size));
|
| 149 |
+
|
| 150 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 151 |
+
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 152 |
+
if (d % 8 == 0) {
|
| 153 |
+
LAUNCH_RMS_NORM(8);
|
| 154 |
+
} else {
|
| 155 |
+
LAUNCH_RMS_NORM(0);
|
| 156 |
+
}
|
| 157 |
+
}
|
activation/fused_mul_poly_norm.cu
ADDED
|
@@ -0,0 +1,642 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include <ATen/Functions.h>
|
| 2 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 3 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 4 |
+
#include <torch/all.h>
|
| 5 |
+
|
| 6 |
+
#include <cmath>
|
| 7 |
+
|
| 8 |
+
#include "assert_utils.h"
|
| 9 |
+
#include "atomic_utils.h"
|
| 10 |
+
#include "cuda_compat.h"
|
| 11 |
+
#include "dispatch_utils.h"
|
| 12 |
+
|
| 13 |
+
namespace motif {
|
| 14 |
+
|
| 15 |
+
template <typename type, int N> struct alignas(sizeof(type) * N) type_vec_t {
|
| 16 |
+
type data[N];
|
| 17 |
+
};
|
| 18 |
+
|
| 19 |
+
struct SumOp {
|
| 20 |
+
__device__ float3 operator()(const float3 &a, const float3 &b) const {
|
| 21 |
+
return make_float3(a.x + b.x, a.y + b.y, a.z + b.z);
|
| 22 |
+
}
|
| 23 |
+
};
|
| 24 |
+
|
| 25 |
+
struct SumOp4 {
|
| 26 |
+
__device__ float4 operator()(const float4 &a, const float4 &b) const {
|
| 27 |
+
return make_float4(a.x + b.x, a.y + b.y, a.z + b.z, a.w + b.w);
|
| 28 |
+
}
|
| 29 |
+
};
|
| 30 |
+
|
| 31 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 32 |
+
__global__ std::enable_if_t<(width > 0)>
|
| 33 |
+
fused_mul_poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 34 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 35 |
+
const scalar_t *__restrict__ mul, // [..., d]
|
| 36 |
+
const scalar_t *__restrict__ weight, // [3]
|
| 37 |
+
const scalar_t *__restrict__ bias, // [1]
|
| 38 |
+
const float eps, const int d) {
|
| 39 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 40 |
+
|
| 41 |
+
const int vec_d = d / width;
|
| 42 |
+
const int64_t vec_offset = blockIdx.x * vec_d;
|
| 43 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 44 |
+
|
| 45 |
+
acc_t sum2 = 0.0f;
|
| 46 |
+
acc_t sum4 = 0.0f;
|
| 47 |
+
acc_t sum6 = 0.0f;
|
| 48 |
+
|
| 49 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 50 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 51 |
+
|
| 52 |
+
#pragma unroll
|
| 53 |
+
for (int i = 0; i < width; ++i) {
|
| 54 |
+
acc_t x1 = x_vec.data[i];
|
| 55 |
+
acc_t x2 = x1 * x1;
|
| 56 |
+
acc_t x4 = x2 * x2;
|
| 57 |
+
acc_t x6 = x4 * x2;
|
| 58 |
+
|
| 59 |
+
sum2 += x2;
|
| 60 |
+
sum4 += x4;
|
| 61 |
+
sum6 += x6;
|
| 62 |
+
}
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 66 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 67 |
+
|
| 68 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 69 |
+
float3 block_sums =
|
| 70 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 71 |
+
|
| 72 |
+
sum2 = block_sums.x;
|
| 73 |
+
sum4 = block_sums.y;
|
| 74 |
+
sum6 = block_sums.z;
|
| 75 |
+
|
| 76 |
+
__shared__ acc_t s_bias;
|
| 77 |
+
|
| 78 |
+
__shared__ acc_t s_w2_inv_std1;
|
| 79 |
+
__shared__ acc_t s_w1_inv_std2;
|
| 80 |
+
__shared__ acc_t s_w0_inv_std3;
|
| 81 |
+
|
| 82 |
+
if (threadIdx.x == 0) {
|
| 83 |
+
acc_t w0 = weight[0];
|
| 84 |
+
acc_t w1 = weight[1];
|
| 85 |
+
acc_t w2 = weight[2];
|
| 86 |
+
s_bias = bias[0];
|
| 87 |
+
|
| 88 |
+
s_w2_inv_std1 = rsqrtf(sum2 / d + eps) * w2;
|
| 89 |
+
s_w1_inv_std2 = rsqrtf(sum4 / d + eps) * w1;
|
| 90 |
+
s_w0_inv_std3 = rsqrtf(sum6 / d + eps) * w0;
|
| 91 |
+
}
|
| 92 |
+
__syncthreads();
|
| 93 |
+
|
| 94 |
+
acc_t w2_inv_std1 = s_w2_inv_std1;
|
| 95 |
+
acc_t w1_inv_std2 = s_w1_inv_std2;
|
| 96 |
+
acc_t w0_inv_std3 = s_w0_inv_std3;
|
| 97 |
+
acc_t bias_reg = s_bias;
|
| 98 |
+
|
| 99 |
+
vec_t *__restrict__ output_vec = reinterpret_cast<vec_t *>(out);
|
| 100 |
+
const vec_t *__restrict__ mul_vec = reinterpret_cast<const vec_t *>(mul);
|
| 101 |
+
|
| 102 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 103 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 104 |
+
vec_t m_vec = mul_vec[vec_offset + idx];
|
| 105 |
+
vec_t y_vec;
|
| 106 |
+
|
| 107 |
+
#pragma unroll
|
| 108 |
+
for (int i = 0; i < width; ++i) {
|
| 109 |
+
acc_t x1 = x_vec.data[i];
|
| 110 |
+
scalar_t m = m_vec.data[i];
|
| 111 |
+
acc_t x2 = x1 * x1;
|
| 112 |
+
acc_t x3 = x2 * x1;
|
| 113 |
+
scalar_t poly_norm_result =
|
| 114 |
+
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
| 115 |
+
y_vec.data[i] = poly_norm_result * m;
|
| 116 |
+
}
|
| 117 |
+
output_vec[vec_offset + idx] = y_vec;
|
| 118 |
+
}
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 122 |
+
__global__ std::enable_if_t<(width == 0)>
|
| 123 |
+
fused_mul_poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 124 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 125 |
+
const scalar_t *__restrict__ mul, // [..., d]
|
| 126 |
+
const scalar_t *__restrict__ weight, // [3]
|
| 127 |
+
const scalar_t *__restrict__ bias, // [1]
|
| 128 |
+
const float eps, const int d) {
|
| 129 |
+
const int64_t token_idx = blockIdx.x;
|
| 130 |
+
|
| 131 |
+
acc_t sum2 = 0.0f;
|
| 132 |
+
acc_t sum4 = 0.0f;
|
| 133 |
+
acc_t sum6 = 0.0f;
|
| 134 |
+
|
| 135 |
+
for (int64_t idx = threadIdx.x; idx < d; idx += blockDim.x) {
|
| 136 |
+
acc_t x1 = input[token_idx * d + idx];
|
| 137 |
+
acc_t x2 = x1 * x1;
|
| 138 |
+
acc_t x4 = x2 * x2;
|
| 139 |
+
acc_t x6 = x4 * x2;
|
| 140 |
+
|
| 141 |
+
sum2 += x2;
|
| 142 |
+
sum4 += x4;
|
| 143 |
+
sum6 += x6;
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 147 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 148 |
+
|
| 149 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 150 |
+
float3 block_sums =
|
| 151 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 152 |
+
|
| 153 |
+
sum2 = block_sums.x;
|
| 154 |
+
sum4 = block_sums.y;
|
| 155 |
+
sum6 = block_sums.z;
|
| 156 |
+
|
| 157 |
+
__shared__ acc_t s_bias;
|
| 158 |
+
|
| 159 |
+
__shared__ acc_t s_w2_inv_std1;
|
| 160 |
+
__shared__ acc_t s_w1_inv_std2;
|
| 161 |
+
__shared__ acc_t s_w0_inv_std3;
|
| 162 |
+
|
| 163 |
+
if (threadIdx.x == 0) {
|
| 164 |
+
acc_t w0 = weight[0];
|
| 165 |
+
acc_t w1 = weight[1];
|
| 166 |
+
acc_t w2 = weight[2];
|
| 167 |
+
s_bias = bias[0];
|
| 168 |
+
|
| 169 |
+
s_w2_inv_std1 = rsqrtf(sum2 / d + eps) * w2;
|
| 170 |
+
s_w1_inv_std2 = rsqrtf(sum4 / d + eps) * w1;
|
| 171 |
+
s_w0_inv_std3 = rsqrtf(sum6 / d + eps) * w0;
|
| 172 |
+
}
|
| 173 |
+
__syncthreads();
|
| 174 |
+
|
| 175 |
+
acc_t w2_inv_std1 = s_w2_inv_std1;
|
| 176 |
+
acc_t w1_inv_std2 = s_w1_inv_std2;
|
| 177 |
+
acc_t w0_inv_std3 = s_w0_inv_std3;
|
| 178 |
+
acc_t bias_reg = s_bias;
|
| 179 |
+
|
| 180 |
+
for (int64_t idx = threadIdx.x; idx < d; idx += blockDim.x) {
|
| 181 |
+
acc_t x1 = input[token_idx * d + idx];
|
| 182 |
+
scalar_t m = mul[token_idx * d + idx];
|
| 183 |
+
acc_t x2 = x1 * x1;
|
| 184 |
+
acc_t x3 = x2 * x1;
|
| 185 |
+
scalar_t poly_norm_result =
|
| 186 |
+
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
| 187 |
+
out[token_idx * d + idx] = poly_norm_result * m;
|
| 188 |
+
}
|
| 189 |
+
}
|
| 190 |
+
|
| 191 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 192 |
+
__global__ std::enable_if_t<(width > 0)> fused_mul_poly_norm_backward_kernel(
|
| 193 |
+
scalar_t *__restrict__ input_grad, // [..., d]
|
| 194 |
+
scalar_t *__restrict__ mul_grad, // [..., d]
|
| 195 |
+
acc_t *__restrict__ temp_weight_grad, // [..., 3]
|
| 196 |
+
acc_t *__restrict__ temp_bias_grad, // [..., 1]
|
| 197 |
+
const scalar_t *__restrict__ output_grad, // [..., d]
|
| 198 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 199 |
+
const scalar_t *__restrict__ mul, // [..., d]
|
| 200 |
+
const scalar_t *__restrict__ weight, // [3]
|
| 201 |
+
const scalar_t *__restrict__ bias, // [1]
|
| 202 |
+
const float eps, const int d) {
|
| 203 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 204 |
+
|
| 205 |
+
const int vec_d = d / width;
|
| 206 |
+
const int64_t vec_offset = blockIdx.x * vec_d;
|
| 207 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 208 |
+
const vec_t *__restrict__ mul_vec = reinterpret_cast<const vec_t *>(mul);
|
| 209 |
+
const vec_t *__restrict__ output_grad_vec =
|
| 210 |
+
reinterpret_cast<const vec_t *>(output_grad);
|
| 211 |
+
|
| 212 |
+
acc_t sum2 = 0.0f;
|
| 213 |
+
acc_t sum4 = 0.0f;
|
| 214 |
+
acc_t sum6 = 0.0f;
|
| 215 |
+
|
| 216 |
+
acc_t sum_dx1 = 0.0f;
|
| 217 |
+
acc_t sum_dx2 = 0.0f;
|
| 218 |
+
acc_t sum_dx3 = 0.0f;
|
| 219 |
+
|
| 220 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 221 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 222 |
+
vec_t dy_fused_vec = output_grad_vec[vec_offset + idx];
|
| 223 |
+
vec_t m_vec = mul_vec[vec_offset + idx];
|
| 224 |
+
|
| 225 |
+
#pragma unroll
|
| 226 |
+
for (int i = 0; i < width; ++i) {
|
| 227 |
+
acc_t x1 = x_vec.data[i];
|
| 228 |
+
acc_t x2 = x1 * x1;
|
| 229 |
+
acc_t x3 = x2 * x1;
|
| 230 |
+
acc_t x4 = x2 * x2;
|
| 231 |
+
acc_t x6 = x3 * x3;
|
| 232 |
+
|
| 233 |
+
sum2 += x2;
|
| 234 |
+
sum4 += x4;
|
| 235 |
+
sum6 += x6;
|
| 236 |
+
|
| 237 |
+
acc_t dy = dy_fused_vec.data[i] * m_vec.data[i];
|
| 238 |
+
|
| 239 |
+
sum_dx1 += dy * x1;
|
| 240 |
+
sum_dx2 += dy * x2;
|
| 241 |
+
sum_dx3 += dy * x3;
|
| 242 |
+
}
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 246 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 247 |
+
|
| 248 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 249 |
+
float3 block_sums =
|
| 250 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 251 |
+
|
| 252 |
+
sum2 = block_sums.x;
|
| 253 |
+
sum4 = block_sums.y;
|
| 254 |
+
sum6 = block_sums.z;
|
| 255 |
+
|
| 256 |
+
float3 thread_dxs = make_float3(sum_dx1, sum_dx2, sum_dx3);
|
| 257 |
+
__syncthreads();
|
| 258 |
+
float3 block_sum_dxs =
|
| 259 |
+
BlockReduce(reduceStore).Reduce(thread_dxs, SumOp{}, blockDim.x);
|
| 260 |
+
|
| 261 |
+
sum_dx1 = block_sum_dxs.x;
|
| 262 |
+
sum_dx2 = block_sum_dxs.y;
|
| 263 |
+
sum_dx3 = block_sum_dxs.z;
|
| 264 |
+
|
| 265 |
+
__shared__ acc_t s_mean2;
|
| 266 |
+
__shared__ acc_t s_mean4;
|
| 267 |
+
__shared__ acc_t s_mean6;
|
| 268 |
+
__shared__ acc_t s_sdx1;
|
| 269 |
+
__shared__ acc_t s_sdx2;
|
| 270 |
+
__shared__ acc_t s_sdx3;
|
| 271 |
+
|
| 272 |
+
const acc_t inv_d = acc_t(1) / d;
|
| 273 |
+
|
| 274 |
+
if (threadIdx.x == 0) {
|
| 275 |
+
s_mean2 = sum2 * inv_d + eps;
|
| 276 |
+
s_mean4 = sum4 * inv_d + eps;
|
| 277 |
+
s_mean6 = sum6 * inv_d + eps;
|
| 278 |
+
|
| 279 |
+
s_sdx1 = sum_dx1 * inv_d;
|
| 280 |
+
s_sdx2 = sum_dx2 * inv_d;
|
| 281 |
+
s_sdx3 = sum_dx3 * inv_d;
|
| 282 |
+
}
|
| 283 |
+
__syncthreads();
|
| 284 |
+
|
| 285 |
+
acc_t w0 = weight[0];
|
| 286 |
+
acc_t w1 = weight[1];
|
| 287 |
+
acc_t w2 = weight[2];
|
| 288 |
+
acc_t bias_reg = bias[0];
|
| 289 |
+
|
| 290 |
+
acc_t mean2 = s_mean2;
|
| 291 |
+
acc_t mean4 = s_mean4;
|
| 292 |
+
acc_t mean6 = s_mean6;
|
| 293 |
+
acc_t sdx1 = s_sdx1;
|
| 294 |
+
acc_t sdx2 = s_sdx2;
|
| 295 |
+
acc_t sdx3 = s_sdx3;
|
| 296 |
+
|
| 297 |
+
acc_t inv_std1 = rsqrtf(mean2);
|
| 298 |
+
acc_t inv_std2 = rsqrtf(mean4);
|
| 299 |
+
acc_t inv_std3 = rsqrtf(mean6);
|
| 300 |
+
|
| 301 |
+
acc_t w2_inv_std1 = inv_std1 * w2;
|
| 302 |
+
acc_t w1_inv_std2 = inv_std2 * w1;
|
| 303 |
+
acc_t w0_inv_std3 = inv_std3 * w0;
|
| 304 |
+
|
| 305 |
+
// inv_std / mean == powf(mean, -1.5)
|
| 306 |
+
acc_t c1 = w2_inv_std1 / mean2;
|
| 307 |
+
acc_t c2 = acc_t(2) * w1_inv_std2 / mean4;
|
| 308 |
+
acc_t c3 = acc_t(3) * w0_inv_std3 / mean6;
|
| 309 |
+
|
| 310 |
+
acc_t sum_dy = 0;
|
| 311 |
+
acc_t sum_dw0 = 0;
|
| 312 |
+
acc_t sum_dw1 = 0;
|
| 313 |
+
acc_t sum_dw2 = 0;
|
| 314 |
+
|
| 315 |
+
vec_t *__restrict__ input_grad_vec = reinterpret_cast<vec_t *>(input_grad);
|
| 316 |
+
vec_t *__restrict__ mul_grad_vec = reinterpret_cast<vec_t *>(mul_grad);
|
| 317 |
+
|
| 318 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 319 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 320 |
+
vec_t dy_fused_vec = output_grad_vec[vec_offset + idx];
|
| 321 |
+
vec_t m_vec = mul_vec[vec_offset + idx];
|
| 322 |
+
vec_t dx_vec;
|
| 323 |
+
vec_t dm_vec;
|
| 324 |
+
|
| 325 |
+
#pragma unroll
|
| 326 |
+
for (int i = 0; i < width; ++i) {
|
| 327 |
+
acc_t x1 = x_vec.data[i];
|
| 328 |
+
acc_t x2 = x1 * x1;
|
| 329 |
+
acc_t x3 = x2 * x1;
|
| 330 |
+
acc_t dy = dy_fused_vec.data[i] * m_vec.data[i];
|
| 331 |
+
|
| 332 |
+
// For register optimization, the order of the following logic matters.
|
| 333 |
+
// The input_grad related logic must be placed at the very end.
|
| 334 |
+
sum_dy += dy;
|
| 335 |
+
sum_dw0 += dy * (x3 * inv_std3);
|
| 336 |
+
sum_dw1 += dy * (x2 * inv_std2);
|
| 337 |
+
sum_dw2 += dy * (x1 * inv_std1);
|
| 338 |
+
|
| 339 |
+
if (mul_grad) {
|
| 340 |
+
scalar_t poly_norm_result =
|
| 341 |
+
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
| 342 |
+
dm_vec.data[i] = poly_norm_result * dy_fused_vec.data[i];
|
| 343 |
+
}
|
| 344 |
+
|
| 345 |
+
if (input_grad) {
|
| 346 |
+
acc_t dx3 = c3 * x2 * (dy * mean6 - x3 * sdx3);
|
| 347 |
+
acc_t dx2 = c2 * x1 * (dy * mean4 - x2 * sdx2);
|
| 348 |
+
acc_t dx1 = c1 * (dy * mean2 - x1 * sdx1);
|
| 349 |
+
dx_vec.data[i] = dx1 + dx2 + dx3;
|
| 350 |
+
}
|
| 351 |
+
}
|
| 352 |
+
|
| 353 |
+
if (input_grad) {
|
| 354 |
+
input_grad_vec[vec_offset + idx] = dx_vec;
|
| 355 |
+
}
|
| 356 |
+
if (mul_grad) {
|
| 357 |
+
mul_grad_vec[vec_offset + idx] = dm_vec;
|
| 358 |
+
}
|
| 359 |
+
}
|
| 360 |
+
|
| 361 |
+
using BlockReduce4 = cub::BlockReduce<float4, 1024>;
|
| 362 |
+
__shared__ typename BlockReduce4::TempStorage reduceStore4;
|
| 363 |
+
|
| 364 |
+
float4 thread_sum_ds = make_float4(sum_dy, sum_dw0, sum_dw1, sum_dw2);
|
| 365 |
+
float4 block_sum_ds =
|
| 366 |
+
BlockReduce4(reduceStore4).Reduce(thread_sum_ds, SumOp4{}, blockDim.x);
|
| 367 |
+
|
| 368 |
+
sum_dy = block_sum_ds.x;
|
| 369 |
+
sum_dw0 = block_sum_ds.y;
|
| 370 |
+
sum_dw1 = block_sum_ds.z;
|
| 371 |
+
sum_dw2 = block_sum_ds.w;
|
| 372 |
+
|
| 373 |
+
if (threadIdx.x == 0) {
|
| 374 |
+
temp_bias_grad[blockIdx.x] = sum_dy;
|
| 375 |
+
temp_weight_grad[blockIdx.x * 3 + 0] = sum_dw0;
|
| 376 |
+
temp_weight_grad[blockIdx.x * 3 + 1] = sum_dw1;
|
| 377 |
+
temp_weight_grad[blockIdx.x * 3 + 2] = sum_dw2;
|
| 378 |
+
}
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 382 |
+
__global__ std::enable_if_t<(width == 0)> fused_mul_poly_norm_backward_kernel(
|
| 383 |
+
scalar_t *__restrict__ input_grad, // [..., d]
|
| 384 |
+
scalar_t *__restrict__ mul_grad, // [..., d]
|
| 385 |
+
acc_t *__restrict__ temp_weight_grad, // [..., 3]
|
| 386 |
+
acc_t *__restrict__ temp_bias_grad, // [..., 1]
|
| 387 |
+
const scalar_t *__restrict__ output_grad, // [..., d]
|
| 388 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 389 |
+
const scalar_t *__restrict__ mul, // [..., d]
|
| 390 |
+
const scalar_t *__restrict__ weight, // [3]
|
| 391 |
+
const scalar_t *__restrict__ bias, // [1]
|
| 392 |
+
const float eps, const int d) {
|
| 393 |
+
const int64_t token_idx = blockIdx.x;
|
| 394 |
+
|
| 395 |
+
acc_t sum2 = 0.0f;
|
| 396 |
+
acc_t sum4 = 0.0f;
|
| 397 |
+
acc_t sum6 = 0.0f;
|
| 398 |
+
|
| 399 |
+
acc_t sum_dx1 = 0.0f;
|
| 400 |
+
acc_t sum_dx2 = 0.0f;
|
| 401 |
+
acc_t sum_dx3 = 0.0f;
|
| 402 |
+
|
| 403 |
+
for (int64_t idx = threadIdx.x; idx < d; idx += blockDim.x) {
|
| 404 |
+
acc_t dy = output_grad[token_idx * d + idx] * mul[token_idx * d + idx];
|
| 405 |
+
|
| 406 |
+
acc_t x1 = input[token_idx * d + idx];
|
| 407 |
+
acc_t x2 = x1 * x1;
|
| 408 |
+
acc_t x3 = x2 * x1;
|
| 409 |
+
acc_t x4 = x2 * x2;
|
| 410 |
+
acc_t x6 = x3 * x3;
|
| 411 |
+
|
| 412 |
+
sum2 += x2;
|
| 413 |
+
sum4 += x4;
|
| 414 |
+
sum6 += x6;
|
| 415 |
+
|
| 416 |
+
sum_dx1 += dy * x1;
|
| 417 |
+
sum_dx2 += dy * x2;
|
| 418 |
+
sum_dx3 += dy * x3;
|
| 419 |
+
}
|
| 420 |
+
|
| 421 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 422 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 423 |
+
|
| 424 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 425 |
+
float3 block_sums =
|
| 426 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 427 |
+
|
| 428 |
+
sum2 = block_sums.x;
|
| 429 |
+
sum4 = block_sums.y;
|
| 430 |
+
sum6 = block_sums.z;
|
| 431 |
+
|
| 432 |
+
float3 thread_dxs = make_float3(sum_dx1, sum_dx2, sum_dx3);
|
| 433 |
+
__syncthreads();
|
| 434 |
+
float3 block_sum_dxs =
|
| 435 |
+
BlockReduce(reduceStore).Reduce(thread_dxs, SumOp{}, blockDim.x);
|
| 436 |
+
|
| 437 |
+
sum_dx1 = block_sum_dxs.x;
|
| 438 |
+
sum_dx2 = block_sum_dxs.y;
|
| 439 |
+
sum_dx3 = block_sum_dxs.z;
|
| 440 |
+
|
| 441 |
+
__shared__ acc_t s_mean2;
|
| 442 |
+
__shared__ acc_t s_mean4;
|
| 443 |
+
__shared__ acc_t s_mean6;
|
| 444 |
+
__shared__ acc_t s_sdx1;
|
| 445 |
+
__shared__ acc_t s_sdx2;
|
| 446 |
+
__shared__ acc_t s_sdx3;
|
| 447 |
+
|
| 448 |
+
const acc_t inv_d = acc_t(1) / d;
|
| 449 |
+
|
| 450 |
+
if (threadIdx.x == 0) {
|
| 451 |
+
s_mean2 = sum2 * inv_d + eps;
|
| 452 |
+
s_mean4 = sum4 * inv_d + eps;
|
| 453 |
+
s_mean6 = sum6 * inv_d + eps;
|
| 454 |
+
|
| 455 |
+
s_sdx1 = sum_dx1 * inv_d;
|
| 456 |
+
s_sdx2 = sum_dx2 * inv_d;
|
| 457 |
+
s_sdx3 = sum_dx3 * inv_d;
|
| 458 |
+
}
|
| 459 |
+
__syncthreads();
|
| 460 |
+
|
| 461 |
+
acc_t w0 = weight[0];
|
| 462 |
+
acc_t w1 = weight[1];
|
| 463 |
+
acc_t w2 = weight[2];
|
| 464 |
+
acc_t bias_reg = bias[0];
|
| 465 |
+
|
| 466 |
+
acc_t mean2 = s_mean2;
|
| 467 |
+
acc_t mean4 = s_mean4;
|
| 468 |
+
acc_t mean6 = s_mean6;
|
| 469 |
+
acc_t sdx1 = s_sdx1;
|
| 470 |
+
acc_t sdx2 = s_sdx2;
|
| 471 |
+
acc_t sdx3 = s_sdx3;
|
| 472 |
+
|
| 473 |
+
acc_t inv_std1 = rsqrtf(mean2);
|
| 474 |
+
acc_t inv_std2 = rsqrtf(mean4);
|
| 475 |
+
acc_t inv_std3 = rsqrtf(mean6);
|
| 476 |
+
|
| 477 |
+
acc_t w2_inv_std1 = inv_std1 * w2;
|
| 478 |
+
acc_t w1_inv_std2 = inv_std2 * w1;
|
| 479 |
+
acc_t w0_inv_std3 = inv_std3 * w0;
|
| 480 |
+
|
| 481 |
+
// inv_std / mean == powf(mean, -1.5)
|
| 482 |
+
acc_t c1 = w2_inv_std1 / mean2;
|
| 483 |
+
acc_t c2 = acc_t(2) * w1_inv_std2 / mean4;
|
| 484 |
+
acc_t c3 = acc_t(3) * w0_inv_std3 / mean6;
|
| 485 |
+
|
| 486 |
+
acc_t sum_dy = 0;
|
| 487 |
+
acc_t sum_dw0 = 0;
|
| 488 |
+
acc_t sum_dw1 = 0;
|
| 489 |
+
acc_t sum_dw2 = 0;
|
| 490 |
+
|
| 491 |
+
for (int64_t idx = threadIdx.x; idx < d; idx += blockDim.x) {
|
| 492 |
+
scalar_t dy_fused = output_grad[token_idx * d + idx];
|
| 493 |
+
acc_t dy = dy_fused * mul[token_idx * d + idx];
|
| 494 |
+
acc_t x1 = input[token_idx * d + idx];
|
| 495 |
+
acc_t x2 = x1 * x1;
|
| 496 |
+
acc_t x3 = x2 * x1;
|
| 497 |
+
|
| 498 |
+
if (input_grad) {
|
| 499 |
+
acc_t dx3 = c3 * x2 * (dy * mean6 - x3 * sdx3);
|
| 500 |
+
acc_t dx2 = c2 * x1 * (dy * mean4 - x2 * sdx2);
|
| 501 |
+
acc_t dx1 = c1 * (dy * mean2 - x1 * sdx1);
|
| 502 |
+
input_grad[token_idx * d + idx] = dx1 + dx2 + dx3;
|
| 503 |
+
}
|
| 504 |
+
|
| 505 |
+
if (mul_grad) {
|
| 506 |
+
scalar_t poly_norm_result =
|
| 507 |
+
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
| 508 |
+
mul_grad[token_idx * d + idx] = poly_norm_result * dy_fused;
|
| 509 |
+
}
|
| 510 |
+
|
| 511 |
+
sum_dy += dy;
|
| 512 |
+
sum_dw0 += dy * (x3 * inv_std3);
|
| 513 |
+
sum_dw1 += dy * (x2 * inv_std2);
|
| 514 |
+
sum_dw2 += dy * (x1 * inv_std1);
|
| 515 |
+
}
|
| 516 |
+
|
| 517 |
+
using BlockReduce4 = cub::BlockReduce<float4, 1024>;
|
| 518 |
+
__shared__ typename BlockReduce4::TempStorage reduceStore4;
|
| 519 |
+
|
| 520 |
+
float4 thread_sum_ds = make_float4(sum_dy, sum_dw0, sum_dw1, sum_dw2);
|
| 521 |
+
float4 block_sum_ds =
|
| 522 |
+
BlockReduce4(reduceStore4).Reduce(thread_sum_ds, SumOp4{}, blockDim.x);
|
| 523 |
+
|
| 524 |
+
sum_dy = block_sum_ds.x;
|
| 525 |
+
sum_dw0 = block_sum_ds.y;
|
| 526 |
+
sum_dw1 = block_sum_ds.z;
|
| 527 |
+
sum_dw2 = block_sum_ds.w;
|
| 528 |
+
|
| 529 |
+
if (threadIdx.x == 0) {
|
| 530 |
+
temp_bias_grad[token_idx] = sum_dy;
|
| 531 |
+
temp_weight_grad[token_idx * 3 + 0] = sum_dw0;
|
| 532 |
+
temp_weight_grad[token_idx * 3 + 1] = sum_dw1;
|
| 533 |
+
temp_weight_grad[token_idx * 3 + 2] = sum_dw2;
|
| 534 |
+
}
|
| 535 |
+
}
|
| 536 |
+
|
| 537 |
+
} // namespace motif
|
| 538 |
+
|
| 539 |
+
#define LAUNCH_FUSED_MUL_POLY_NORM(width) \
|
| 540 |
+
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 541 |
+
input.scalar_type(), "fused_mul_poly_norm_kernel", [&] { \
|
| 542 |
+
motif::fused_mul_poly_norm_kernel<scalar_t, float, width> \
|
| 543 |
+
<<<grid, block, 0, stream>>>( \
|
| 544 |
+
out.data_ptr<scalar_t>(), input.data_ptr<scalar_t>(), \
|
| 545 |
+
mul.data_ptr<scalar_t>(), weight.data_ptr<scalar_t>(), \
|
| 546 |
+
bias.data_ptr<scalar_t>(), eps, d); \
|
| 547 |
+
});
|
| 548 |
+
|
| 549 |
+
void fused_mul_poly_norm(torch::Tensor &out, // [..., d]
|
| 550 |
+
const torch::Tensor &input, // [..., d]
|
| 551 |
+
const torch::Tensor &mul, // [..., d]
|
| 552 |
+
const torch::Tensor &weight, // [3]
|
| 553 |
+
const torch::Tensor &bias, // [1]
|
| 554 |
+
double eps) {
|
| 555 |
+
AssertTensorShapeEqual(input, out, "input", "out");
|
| 556 |
+
AssertTensorShapeEqual(input, mul, "input", "mul");
|
| 557 |
+
AssertTensorNotNull(weight, "weight");
|
| 558 |
+
AssertTensorNotNull(bias, "bias");
|
| 559 |
+
// TODO shape check
|
| 560 |
+
|
| 561 |
+
int d = input.size(-1);
|
| 562 |
+
int64_t num_tokens = input.numel() / d;
|
| 563 |
+
dim3 grid(num_tokens);
|
| 564 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 565 |
+
dim3 block(std::min(d, max_block_size));
|
| 566 |
+
|
| 567 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 568 |
+
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 569 |
+
if (d % 8 == 0) {
|
| 570 |
+
LAUNCH_FUSED_MUL_POLY_NORM(8);
|
| 571 |
+
} else {
|
| 572 |
+
LAUNCH_FUSED_MUL_POLY_NORM(0);
|
| 573 |
+
}
|
| 574 |
+
}
|
| 575 |
+
|
| 576 |
+
#define LAUNCH_POLY_NORM_BACKWARD(width) \
|
| 577 |
+
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 578 |
+
input.scalar_type(), "fused_mul_poly_norm_backward_kernel", [&] { \
|
| 579 |
+
motif::fused_mul_poly_norm_backward_kernel<scalar_t, float, width> \
|
| 580 |
+
<<<grid, block, 0, stream>>>( \
|
| 581 |
+
input_grad.data_ptr<scalar_t>(), \
|
| 582 |
+
mul_grad.data_ptr<scalar_t>(), \
|
| 583 |
+
temp_weight_grad.data_ptr<float>(), \
|
| 584 |
+
temp_bias_grad.data_ptr<float>(), \
|
| 585 |
+
output_grad.data_ptr<scalar_t>(), input.data_ptr<scalar_t>(), \
|
| 586 |
+
mul.data_ptr<scalar_t>(), weight.data_ptr<scalar_t>(), \
|
| 587 |
+
bias.data_ptr<scalar_t>(), eps, d); \
|
| 588 |
+
});
|
| 589 |
+
|
| 590 |
+
void fused_mul_poly_norm_backward(torch::Tensor &input_grad, // [..., d]
|
| 591 |
+
torch::Tensor &mul_grad, // [..., d]
|
| 592 |
+
torch::Tensor &weight_grad, // [3]
|
| 593 |
+
torch::Tensor &bias_grad, // [1]
|
| 594 |
+
const torch::Tensor &output_grad, // [..., d]
|
| 595 |
+
const torch::Tensor &input, // [..., d]
|
| 596 |
+
const torch::Tensor &mul, // [..., d]
|
| 597 |
+
const torch::Tensor &weight, // [3]
|
| 598 |
+
const torch::Tensor &bias, // [1]
|
| 599 |
+
double eps) {
|
| 600 |
+
AssertTensorShapeEqual(input, input_grad, "input", "input_grad");
|
| 601 |
+
AssertTensorShapeEqual(input, output_grad, "input", "output_grad");
|
| 602 |
+
AssertTensorShapeEqual(input, mul_grad, "input", "mul_grad");
|
| 603 |
+
AssertTensorShapeEqual(input, mul, "input", "mul");
|
| 604 |
+
AssertTensorNotNull(weight, "weight");
|
| 605 |
+
// TODO shape check
|
| 606 |
+
// weight_grad, bias_grad, mul_grad and input_grad can be nullable
|
| 607 |
+
|
| 608 |
+
int d = input.size(-1);
|
| 609 |
+
int64_t num_tokens = input.numel() / d;
|
| 610 |
+
dim3 grid(num_tokens);
|
| 611 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 612 |
+
dim3 block(std::min(d, max_block_size));
|
| 613 |
+
|
| 614 |
+
torch::Tensor temp_weight_grad =
|
| 615 |
+
torch::empty({num_tokens, 3}, input.options().dtype(torch::kFloat));
|
| 616 |
+
torch::Tensor temp_bias_grad =
|
| 617 |
+
torch::empty({num_tokens, 1}, output_grad.options().dtype(torch::kFloat));
|
| 618 |
+
|
| 619 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 620 |
+
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 621 |
+
|
| 622 |
+
if (d % 8 == 0 && input.element_size() == 2) {
|
| 623 |
+
LAUNCH_POLY_NORM_BACKWARD(8);
|
| 624 |
+
} else if (d % 4 == 0 && input.element_size() == 4) {
|
| 625 |
+
LAUNCH_POLY_NORM_BACKWARD(4);
|
| 626 |
+
} else {
|
| 627 |
+
LAUNCH_POLY_NORM_BACKWARD(0);
|
| 628 |
+
}
|
| 629 |
+
|
| 630 |
+
if (bias_grad.defined()) {
|
| 631 |
+
torch::Tensor acc = torch::empty_like(bias_grad, temp_bias_grad.options());
|
| 632 |
+
at::sum_out(acc, temp_bias_grad, {0});
|
| 633 |
+
bias_grad.copy_(acc);
|
| 634 |
+
}
|
| 635 |
+
|
| 636 |
+
if (weight_grad.defined()) {
|
| 637 |
+
torch::Tensor acc =
|
| 638 |
+
torch::empty_like(weight_grad, temp_weight_grad.options());
|
| 639 |
+
at::sum_out(acc, temp_weight_grad, {0});
|
| 640 |
+
weight_grad.copy_(acc);
|
| 641 |
+
}
|
| 642 |
+
}
|
activation/poly_norm.cu
CHANGED
|
@@ -7,7 +7,6 @@
|
|
| 7 |
|
| 8 |
#include "assert_utils.h"
|
| 9 |
#include "atomic_utils.h"
|
| 10 |
-
#include "block_reduce.h"
|
| 11 |
#include "cuda_compat.h"
|
| 12 |
#include "dispatch_utils.h"
|
| 13 |
|
|
@@ -17,6 +16,18 @@ template <typename type, int N> struct alignas(sizeof(type) * N) type_vec_t {
|
|
| 17 |
type data[N];
|
| 18 |
};
|
| 19 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
template <typename scalar_t, typename acc_t, int width>
|
| 21 |
__global__ std::enable_if_t<(width > 0)>
|
| 22 |
poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
@@ -39,7 +50,7 @@ poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 39 |
|
| 40 |
#pragma unroll
|
| 41 |
for (int i = 0; i < width; ++i) {
|
| 42 |
-
acc_t x1 =
|
| 43 |
acc_t x2 = x1 * x1;
|
| 44 |
acc_t x4 = x2 * x2;
|
| 45 |
acc_t x6 = x4 * x2;
|
|
@@ -50,14 +61,16 @@ poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 50 |
}
|
| 51 |
}
|
| 52 |
|
| 53 |
-
using BlockReduce = cub::BlockReduce<
|
| 54 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 55 |
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
|
|
|
|
|
|
| 61 |
|
| 62 |
__shared__ acc_t s_bias;
|
| 63 |
|
|
@@ -90,14 +103,12 @@ poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 90 |
|
| 91 |
#pragma unroll
|
| 92 |
for (int i = 0; i < width; ++i) {
|
| 93 |
-
acc_t x1 =
|
| 94 |
acc_t x2 = x1 * x1;
|
| 95 |
acc_t x3 = x2 * x1;
|
| 96 |
|
| 97 |
-
|
| 98 |
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
| 99 |
-
|
| 100 |
-
y_vec.data[i] = static_cast<scalar_t>(y);
|
| 101 |
}
|
| 102 |
output_vec[vec_offset + idx] = y_vec;
|
| 103 |
}
|
|
@@ -127,14 +138,16 @@ poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 127 |
sum6 += x6;
|
| 128 |
}
|
| 129 |
|
| 130 |
-
using BlockReduce = cub::BlockReduce<
|
| 131 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 132 |
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
|
|
|
|
|
|
| 138 |
|
| 139 |
__shared__ acc_t s_bias;
|
| 140 |
|
|
@@ -199,7 +212,7 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 199 |
|
| 200 |
#pragma unroll
|
| 201 |
for (int i = 0; i < width; ++i) {
|
| 202 |
-
acc_t x1 =
|
| 203 |
acc_t x2 = x1 * x1;
|
| 204 |
acc_t x3 = x2 * x1;
|
| 205 |
acc_t x4 = x2 * x2;
|
|
@@ -209,7 +222,7 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 209 |
sum4 += x4;
|
| 210 |
sum6 += x6;
|
| 211 |
|
| 212 |
-
acc_t dy =
|
| 213 |
|
| 214 |
sum_dx1 += dy * x1;
|
| 215 |
sum_dx2 += dy * x2;
|
|
@@ -217,22 +230,25 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 217 |
}
|
| 218 |
}
|
| 219 |
|
| 220 |
-
using BlockReduce = cub::BlockReduce<
|
| 221 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 222 |
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
sum4 = BlockReduce(reduceStore).Sum(sum4, blockDim.x);
|
| 227 |
-
__syncthreads();
|
| 228 |
-
sum6 = BlockReduce(reduceStore).Sum(sum6, blockDim.x);
|
| 229 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 230 |
__syncthreads();
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
|
|
|
| 236 |
|
| 237 |
__shared__ acc_t s_mean2;
|
| 238 |
__shared__ acc_t s_mean4;
|
|
@@ -288,16 +304,16 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 288 |
|
| 289 |
#pragma unroll
|
| 290 |
for (int i = 0; i < width; ++i) {
|
| 291 |
-
acc_t x1 =
|
| 292 |
acc_t x2 = x1 * x1;
|
| 293 |
acc_t x3 = x2 * x1;
|
| 294 |
-
acc_t dy =
|
| 295 |
|
| 296 |
if (input_grad) {
|
| 297 |
acc_t dx3 = c3 * x2 * (dy * mean6 - x3 * sdx3);
|
| 298 |
acc_t dx2 = c2 * x1 * (dy * mean4 - x2 * sdx2);
|
| 299 |
acc_t dx1 = c1 * (dy * mean2 - x1 * sdx1);
|
| 300 |
-
dx_vec.data[i] =
|
| 301 |
}
|
| 302 |
|
| 303 |
sum_dy += dy;
|
|
@@ -311,13 +327,17 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 311 |
}
|
| 312 |
}
|
| 313 |
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
|
| 317 |
-
|
| 318 |
-
|
| 319 |
-
|
| 320 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 321 |
|
| 322 |
if (threadIdx.x == 0) {
|
| 323 |
temp_bias_grad[blockIdx.x] = sum_dy;
|
|
@@ -364,22 +384,25 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 364 |
sum_dx3 += dy * x3;
|
| 365 |
}
|
| 366 |
|
| 367 |
-
using BlockReduce = cub::BlockReduce<
|
| 368 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 369 |
|
| 370 |
-
|
| 371 |
-
|
| 372 |
-
|
| 373 |
-
sum4 = BlockReduce(reduceStore).Sum(sum4, blockDim.x);
|
| 374 |
-
__syncthreads();
|
| 375 |
-
sum6 = BlockReduce(reduceStore).Sum(sum6, blockDim.x);
|
| 376 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 377 |
__syncthreads();
|
| 378 |
-
|
| 379 |
-
|
| 380 |
-
|
| 381 |
-
|
| 382 |
-
|
|
|
|
| 383 |
|
| 384 |
__shared__ acc_t s_mean2;
|
| 385 |
__shared__ acc_t s_mean4;
|
|
@@ -445,13 +468,17 @@ poly_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 445 |
sum_dw2 += dy * (x1 * inv_std1);
|
| 446 |
}
|
| 447 |
|
| 448 |
-
|
| 449 |
-
|
| 450 |
-
|
| 451 |
-
|
| 452 |
-
|
| 453 |
-
|
| 454 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 455 |
|
| 456 |
if (threadIdx.x == 0) {
|
| 457 |
temp_bias_grad[token_idx] = sum_dy;
|
|
|
|
| 7 |
|
| 8 |
#include "assert_utils.h"
|
| 9 |
#include "atomic_utils.h"
|
|
|
|
| 10 |
#include "cuda_compat.h"
|
| 11 |
#include "dispatch_utils.h"
|
| 12 |
|
|
|
|
| 16 |
type data[N];
|
| 17 |
};
|
| 18 |
|
| 19 |
+
struct SumOp {
|
| 20 |
+
__device__ float3 operator()(const float3 &a, const float3 &b) const {
|
| 21 |
+
return make_float3(a.x + b.x, a.y + b.y, a.z + b.z);
|
| 22 |
+
}
|
| 23 |
+
};
|
| 24 |
+
|
| 25 |
+
struct SumOp4 {
|
| 26 |
+
__device__ float4 operator()(const float4 &a, const float4 &b) const {
|
| 27 |
+
return make_float4(a.x + b.x, a.y + b.y, a.z + b.z, a.w + b.w);
|
| 28 |
+
}
|
| 29 |
+
};
|
| 30 |
+
|
| 31 |
template <typename scalar_t, typename acc_t, int width>
|
| 32 |
__global__ std::enable_if_t<(width > 0)>
|
| 33 |
poly_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
|
|
| 50 |
|
| 51 |
#pragma unroll
|
| 52 |
for (int i = 0; i < width; ++i) {
|
| 53 |
+
acc_t x1 = x_vec.data[i];
|
| 54 |
acc_t x2 = x1 * x1;
|
| 55 |
acc_t x4 = x2 * x2;
|
| 56 |
acc_t x6 = x4 * x2;
|
|
|
|
| 61 |
}
|
| 62 |
}
|
| 63 |
|
| 64 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 65 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 66 |
|
| 67 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 68 |
+
float3 block_sums =
|
| 69 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 70 |
+
|
| 71 |
+
sum2 = block_sums.x;
|
| 72 |
+
sum4 = block_sums.y;
|
| 73 |
+
sum6 = block_sums.z;
|
| 74 |
|
| 75 |
__shared__ acc_t s_bias;
|
| 76 |
|
|
|
|
| 103 |
|
| 104 |
#pragma unroll
|
| 105 |
for (int i = 0; i < width; ++i) {
|
| 106 |
+
acc_t x1 = x_vec.data[i];
|
| 107 |
acc_t x2 = x1 * x1;
|
| 108 |
acc_t x3 = x2 * x1;
|
| 109 |
|
| 110 |
+
y_vec.data[i] =
|
| 111 |
x1 * w2_inv_std1 + x2 * w1_inv_std2 + x3 * w0_inv_std3 + bias_reg;
|
|
|
|
|
|
|
| 112 |
}
|
| 113 |
output_vec[vec_offset + idx] = y_vec;
|
| 114 |
}
|
|
|
|
| 138 |
sum6 += x6;
|
| 139 |
}
|
| 140 |
|
| 141 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 142 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 143 |
|
| 144 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 145 |
+
float3 block_sums =
|
| 146 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 147 |
+
|
| 148 |
+
sum2 = block_sums.x;
|
| 149 |
+
sum4 = block_sums.y;
|
| 150 |
+
sum6 = block_sums.z;
|
| 151 |
|
| 152 |
__shared__ acc_t s_bias;
|
| 153 |
|
|
|
|
| 212 |
|
| 213 |
#pragma unroll
|
| 214 |
for (int i = 0; i < width; ++i) {
|
| 215 |
+
acc_t x1 = x_vec.data[i];
|
| 216 |
acc_t x2 = x1 * x1;
|
| 217 |
acc_t x3 = x2 * x1;
|
| 218 |
acc_t x4 = x2 * x2;
|
|
|
|
| 222 |
sum4 += x4;
|
| 223 |
sum6 += x6;
|
| 224 |
|
| 225 |
+
acc_t dy = dy_vec.data[i];
|
| 226 |
|
| 227 |
sum_dx1 += dy * x1;
|
| 228 |
sum_dx2 += dy * x2;
|
|
|
|
| 230 |
}
|
| 231 |
}
|
| 232 |
|
| 233 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 234 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 235 |
|
| 236 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 237 |
+
float3 block_sums =
|
| 238 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
|
|
|
|
|
|
|
|
|
| 239 |
|
| 240 |
+
sum2 = block_sums.x;
|
| 241 |
+
sum4 = block_sums.y;
|
| 242 |
+
sum6 = block_sums.z;
|
| 243 |
+
|
| 244 |
+
float3 thread_dxs = make_float3(sum_dx1, sum_dx2, sum_dx3);
|
| 245 |
__syncthreads();
|
| 246 |
+
float3 block_sum_dxs =
|
| 247 |
+
BlockReduce(reduceStore).Reduce(thread_dxs, SumOp{}, blockDim.x);
|
| 248 |
+
|
| 249 |
+
sum_dx1 = block_sum_dxs.x;
|
| 250 |
+
sum_dx2 = block_sum_dxs.y;
|
| 251 |
+
sum_dx3 = block_sum_dxs.z;
|
| 252 |
|
| 253 |
__shared__ acc_t s_mean2;
|
| 254 |
__shared__ acc_t s_mean4;
|
|
|
|
| 304 |
|
| 305 |
#pragma unroll
|
| 306 |
for (int i = 0; i < width; ++i) {
|
| 307 |
+
acc_t x1 = x_vec.data[i];
|
| 308 |
acc_t x2 = x1 * x1;
|
| 309 |
acc_t x3 = x2 * x1;
|
| 310 |
+
acc_t dy = dy_vec.data[i];
|
| 311 |
|
| 312 |
if (input_grad) {
|
| 313 |
acc_t dx3 = c3 * x2 * (dy * mean6 - x3 * sdx3);
|
| 314 |
acc_t dx2 = c2 * x1 * (dy * mean4 - x2 * sdx2);
|
| 315 |
acc_t dx1 = c1 * (dy * mean2 - x1 * sdx1);
|
| 316 |
+
dx_vec.data[i] = dx1 + dx2 + dx3;
|
| 317 |
}
|
| 318 |
|
| 319 |
sum_dy += dy;
|
|
|
|
| 327 |
}
|
| 328 |
}
|
| 329 |
|
| 330 |
+
using BlockReduce4 = cub::BlockReduce<float4, 1024>;
|
| 331 |
+
__shared__ typename BlockReduce4::TempStorage reduceStore4;
|
| 332 |
+
|
| 333 |
+
float4 thread_sum_ds = make_float4(sum_dy, sum_dw0, sum_dw1, sum_dw2);
|
| 334 |
+
float4 block_sum_ds =
|
| 335 |
+
BlockReduce4(reduceStore4).Reduce(thread_sum_ds, SumOp4{}, blockDim.x);
|
| 336 |
+
|
| 337 |
+
sum_dy = block_sum_ds.x;
|
| 338 |
+
sum_dw0 = block_sum_ds.y;
|
| 339 |
+
sum_dw1 = block_sum_ds.z;
|
| 340 |
+
sum_dw2 = block_sum_ds.w;
|
| 341 |
|
| 342 |
if (threadIdx.x == 0) {
|
| 343 |
temp_bias_grad[blockIdx.x] = sum_dy;
|
|
|
|
| 384 |
sum_dx3 += dy * x3;
|
| 385 |
}
|
| 386 |
|
| 387 |
+
using BlockReduce = cub::BlockReduce<float3, 1024>;
|
| 388 |
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 389 |
|
| 390 |
+
float3 thread_sums = make_float3(sum2, sum4, sum6);
|
| 391 |
+
float3 block_sums =
|
| 392 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
|
|
|
|
|
|
|
|
|
| 393 |
|
| 394 |
+
sum2 = block_sums.x;
|
| 395 |
+
sum4 = block_sums.y;
|
| 396 |
+
sum6 = block_sums.z;
|
| 397 |
+
|
| 398 |
+
float3 thread_dxs = make_float3(sum_dx1, sum_dx2, sum_dx3);
|
| 399 |
__syncthreads();
|
| 400 |
+
float3 block_sum_dxs =
|
| 401 |
+
BlockReduce(reduceStore).Reduce(thread_dxs, SumOp{}, blockDim.x);
|
| 402 |
+
|
| 403 |
+
sum_dx1 = block_sum_dxs.x;
|
| 404 |
+
sum_dx2 = block_sum_dxs.y;
|
| 405 |
+
sum_dx3 = block_sum_dxs.z;
|
| 406 |
|
| 407 |
__shared__ acc_t s_mean2;
|
| 408 |
__shared__ acc_t s_mean4;
|
|
|
|
| 468 |
sum_dw2 += dy * (x1 * inv_std1);
|
| 469 |
}
|
| 470 |
|
| 471 |
+
using BlockReduce4 = cub::BlockReduce<float4, 1024>;
|
| 472 |
+
__shared__ typename BlockReduce4::TempStorage reduceStore4;
|
| 473 |
+
|
| 474 |
+
float4 thread_sum_ds = make_float4(sum_dy, sum_dw0, sum_dw1, sum_dw2);
|
| 475 |
+
float4 block_sum_ds =
|
| 476 |
+
BlockReduce4(reduceStore4).Reduce(thread_sum_ds, SumOp4{}, blockDim.x);
|
| 477 |
+
|
| 478 |
+
sum_dy = block_sum_ds.x;
|
| 479 |
+
sum_dw0 = block_sum_ds.y;
|
| 480 |
+
sum_dw1 = block_sum_ds.z;
|
| 481 |
+
sum_dw2 = block_sum_ds.w;
|
| 482 |
|
| 483 |
if (threadIdx.x == 0) {
|
| 484 |
temp_bias_grad[token_idx] = sum_dy;
|
activation/rms_norm.cu
CHANGED
|
@@ -7,18 +7,76 @@
|
|
| 7 |
|
| 8 |
#include "assert_utils.h"
|
| 9 |
#include "atomic_utils.h"
|
| 10 |
-
#include "block_reduce.h"
|
| 11 |
#include "cuda_compat.h"
|
| 12 |
#include "dispatch_utils.h"
|
| 13 |
|
| 14 |
namespace motif {
|
| 15 |
|
| 16 |
-
template <typename
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
const scalar_t *__restrict__ weight, // [d]
|
| 20 |
-
const float eps, const int d) {
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
const int64_t token_idx = blockIdx.x;
|
| 23 |
const int64_t vec_idx = threadIdx.x;
|
| 24 |
acc_t sum_square = 0.0f;
|
|
@@ -28,20 +86,123 @@ __global__ void rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 28 |
sum_square += x * x;
|
| 29 |
}
|
| 30 |
|
| 31 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
|
| 33 |
-
acc_t variance =
|
| 34 |
-
_block_reduce_sum<acc_t, BLOCK_SIZE>(shared, sum_square, d) / d;
|
| 35 |
-
acc_t scale = rsqrt(variance + eps);
|
| 36 |
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 37 |
acc_t x = input[token_idx * d + idx];
|
| 38 |
acc_t w = weight[idx];
|
| 39 |
-
out[token_idx * d + idx] = w * x *
|
| 40 |
}
|
| 41 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
-
|
| 44 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
rms_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
| 46 |
acc_t *__restrict__ temp_weight_grad, // [..., d]
|
| 47 |
const scalar_t *__restrict__ output_grad, // [..., d]
|
|
@@ -61,30 +222,55 @@ rms_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
|
| 61 |
sum_square += x * x;
|
| 62 |
}
|
| 63 |
|
| 64 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
-
d_sum =
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
acc_t
|
| 70 |
-
acc_t
|
| 71 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
| 73 |
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 74 |
acc_t x = input[token_idx * d + idx];
|
| 75 |
acc_t dy = output_grad[token_idx * d + idx];
|
| 76 |
acc_t w = weight[idx];
|
| 77 |
|
| 78 |
-
input_grad
|
| 79 |
-
|
| 80 |
-
if (temp_weight_grad) {
|
| 81 |
-
temp_weight_grad[token_idx * d + idx] = dy * x * scale;
|
| 82 |
}
|
|
|
|
| 83 |
}
|
| 84 |
}
|
| 85 |
|
| 86 |
} // namespace motif
|
| 87 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 88 |
void rms_norm(torch::Tensor &out, // [..., d]
|
| 89 |
const torch::Tensor &input, // [..., d]
|
| 90 |
const torch::Tensor &weight, // [d]
|
|
@@ -93,27 +279,36 @@ void rms_norm(torch::Tensor &out, // [..., d]
|
|
| 93 |
AssertTensorNotNull(weight, "weight");
|
| 94 |
// TODO shape check
|
| 95 |
|
| 96 |
-
constexpr int BLOCK_SIZE = 256;
|
| 97 |
-
|
| 98 |
int d = input.size(-1);
|
| 99 |
int64_t num_tokens = input.numel() / input.size(-1);
|
| 100 |
dim3 grid(num_tokens);
|
| 101 |
-
|
|
|
|
| 102 |
|
| 103 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 104 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
});
|
| 111 |
}
|
| 112 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
void rms_norm_backward(torch::Tensor &input_grad, // [..., d]
|
| 114 |
-
torch::Tensor &weight_grad, // [
|
| 115 |
-
const torch::Tensor &output_grad, // [d]
|
| 116 |
-
const torch::Tensor &input, // [d]
|
| 117 |
const torch::Tensor &weight, // [d]
|
| 118 |
double eps) {
|
| 119 |
AssertTensorShapeEqual(input, input_grad, "input", "input_grad");
|
|
@@ -122,30 +317,27 @@ void rms_norm_backward(torch::Tensor &input_grad, // [..., d]
|
|
| 122 |
// TODO shape check
|
| 123 |
// weight_grad, input_grad can be nullable
|
| 124 |
|
| 125 |
-
constexpr int BLOCK_SIZE = 256;
|
| 126 |
-
|
| 127 |
int d = input.size(-1);
|
| 128 |
int64_t num_tokens = input.numel() / input.size(-1);
|
| 129 |
dim3 grid(num_tokens);
|
| 130 |
-
|
|
|
|
| 131 |
|
| 132 |
torch::Tensor temp_weight_grad =
|
| 133 |
torch::empty({num_tokens, d}, input.options().dtype(torch::kFloat));
|
| 134 |
|
| 135 |
-
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 136 |
-
|
| 137 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
input.data_ptr<scalar_t>(),
|
| 145 |
-
weight.data_ptr<scalar_t>(), eps, d);
|
| 146 |
-
});
|
| 147 |
|
| 148 |
if (weight_grad.defined()) {
|
| 149 |
-
|
|
|
|
|
|
|
|
|
|
| 150 |
}
|
| 151 |
}
|
|
|
|
| 7 |
|
| 8 |
#include "assert_utils.h"
|
| 9 |
#include "atomic_utils.h"
|
|
|
|
| 10 |
#include "cuda_compat.h"
|
| 11 |
#include "dispatch_utils.h"
|
| 12 |
|
| 13 |
namespace motif {
|
| 14 |
|
| 15 |
+
template <typename type, int N> struct alignas(sizeof(type) * N) type_vec_t {
|
| 16 |
+
type data[N];
|
| 17 |
+
};
|
|
|
|
|
|
|
| 18 |
|
| 19 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 20 |
+
__global__ std::enable_if_t<(width > 0)>
|
| 21 |
+
rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 22 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 23 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 24 |
+
const float eps, const int d) {
|
| 25 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 26 |
+
|
| 27 |
+
const int vec_d = d / width;
|
| 28 |
+
const int64_t vec_offset = blockIdx.x * vec_d;
|
| 29 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 30 |
+
acc_t sum_square = 0.0f;
|
| 31 |
+
|
| 32 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 33 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 34 |
+
|
| 35 |
+
#pragma unroll
|
| 36 |
+
for (int i = 0; i < width; ++i) {
|
| 37 |
+
acc_t x = x_vec.data[i];
|
| 38 |
+
sum_square += x * x;
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
using BlockReduce = cub::BlockReduce<float, 1024>;
|
| 43 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 44 |
+
|
| 45 |
+
sum_square = BlockReduce(reduceStore).Sum(sum_square, blockDim.x);
|
| 46 |
+
|
| 47 |
+
__shared__ acc_t s_scale;
|
| 48 |
+
|
| 49 |
+
if (threadIdx.x == 0) {
|
| 50 |
+
s_scale = rsqrtf(sum_square / d + eps);
|
| 51 |
+
}
|
| 52 |
+
__syncthreads();
|
| 53 |
+
|
| 54 |
+
const vec_t *__restrict__ weight_vec =
|
| 55 |
+
reinterpret_cast<const vec_t *>(weight);
|
| 56 |
+
vec_t *__restrict__ output_vec = reinterpret_cast<vec_t *>(out);
|
| 57 |
+
|
| 58 |
+
for (int64_t idx = threadIdx.x; idx < vec_d; idx += blockDim.x) {
|
| 59 |
+
vec_t x_vec = input_vec[vec_offset + idx];
|
| 60 |
+
vec_t w_vec = weight_vec[idx];
|
| 61 |
+
vec_t y_vec;
|
| 62 |
+
|
| 63 |
+
#pragma unroll
|
| 64 |
+
for (int i = 0; i < width; ++i) {
|
| 65 |
+
acc_t x = x_vec.data[i];
|
| 66 |
+
acc_t w = w_vec.data[i];
|
| 67 |
+
|
| 68 |
+
y_vec.data[i] = w * x * s_scale;
|
| 69 |
+
}
|
| 70 |
+
output_vec[vec_offset + idx] = y_vec;
|
| 71 |
+
}
|
| 72 |
+
}
|
| 73 |
+
|
| 74 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 75 |
+
__global__ std::enable_if_t<(width == 0)>
|
| 76 |
+
rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
| 77 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 78 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 79 |
+
const float eps, const int d) {
|
| 80 |
const int64_t token_idx = blockIdx.x;
|
| 81 |
const int64_t vec_idx = threadIdx.x;
|
| 82 |
acc_t sum_square = 0.0f;
|
|
|
|
| 86 |
sum_square += x * x;
|
| 87 |
}
|
| 88 |
|
| 89 |
+
using BlockReduce = cub::BlockReduce<float, 1024>;
|
| 90 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 91 |
+
|
| 92 |
+
sum_square = BlockReduce(reduceStore).Sum(sum_square, blockDim.x);
|
| 93 |
+
|
| 94 |
+
__shared__ acc_t s_scale;
|
| 95 |
+
|
| 96 |
+
if (vec_idx == 0) {
|
| 97 |
+
s_scale = rsqrtf(sum_square / d + eps);
|
| 98 |
+
}
|
| 99 |
+
__syncthreads();
|
| 100 |
|
|
|
|
|
|
|
|
|
|
| 101 |
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 102 |
acc_t x = input[token_idx * d + idx];
|
| 103 |
acc_t w = weight[idx];
|
| 104 |
+
out[token_idx * d + idx] = w * x * s_scale;
|
| 105 |
}
|
| 106 |
}
|
| 107 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 108 |
+
__global__ std::enable_if_t<(width > 0)>
|
| 109 |
+
rms_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
| 110 |
+
acc_t *__restrict__ temp_weight_grad, // [..., d]
|
| 111 |
+
const scalar_t *__restrict__ output_grad, // [..., d]
|
| 112 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 113 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 114 |
+
const float eps, const int d) {
|
| 115 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 116 |
+
using dw_vec_t = type_vec_t<acc_t, width>;
|
| 117 |
+
|
| 118 |
+
const int64_t token_idx = blockIdx.x;
|
| 119 |
+
const int64_t vec_idx = threadIdx.x;
|
| 120 |
+
|
| 121 |
+
const int vec_d = d / width;
|
| 122 |
+
const int64_t vec_offset = token_idx * vec_d;
|
| 123 |
+
|
| 124 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 125 |
+
const vec_t *__restrict__ output_grad_vec =
|
| 126 |
+
reinterpret_cast<const vec_t *>(output_grad);
|
| 127 |
+
const vec_t *__restrict__ weight_vec =
|
| 128 |
+
reinterpret_cast<const vec_t *>(weight);
|
| 129 |
+
|
| 130 |
+
acc_t d_sum = 0.0f;
|
| 131 |
+
acc_t sum_square = 0.0f;
|
| 132 |
+
|
| 133 |
+
for (int64_t vidx = vec_idx; vidx < vec_d; vidx += blockDim.x) {
|
| 134 |
+
vec_t x_vec = input_vec[vec_offset + vidx];
|
| 135 |
+
vec_t dy_vec = output_grad_vec[vec_offset + vidx];
|
| 136 |
+
vec_t w_vec = weight_vec[vidx];
|
| 137 |
|
| 138 |
+
#pragma unroll
|
| 139 |
+
for (int i = 0; i < width; ++i) {
|
| 140 |
+
acc_t x = x_vec.data[i];
|
| 141 |
+
acc_t dy = dy_vec.data[i];
|
| 142 |
+
acc_t w = w_vec.data[i];
|
| 143 |
+
d_sum += dy * x * w;
|
| 144 |
+
sum_square += x * x;
|
| 145 |
+
}
|
| 146 |
+
}
|
| 147 |
+
|
| 148 |
+
using BlockReduce = cub::BlockReduce<float2, 1024>;
|
| 149 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 150 |
+
struct SumOp {
|
| 151 |
+
__device__ float2 operator()(const float2 &a, const float2 &b) const {
|
| 152 |
+
return make_float2(a.x + b.x, a.y + b.y);
|
| 153 |
+
}
|
| 154 |
+
};
|
| 155 |
+
float2 thread_sums = make_float2(d_sum, sum_square);
|
| 156 |
+
float2 block_sums =
|
| 157 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 158 |
+
|
| 159 |
+
d_sum = block_sums.x;
|
| 160 |
+
sum_square = block_sums.y;
|
| 161 |
+
|
| 162 |
+
__shared__ acc_t s_scale;
|
| 163 |
+
__shared__ acc_t s_dxx;
|
| 164 |
+
|
| 165 |
+
if (threadIdx.x == 0) {
|
| 166 |
+
acc_t scale = rsqrtf(sum_square / d + eps);
|
| 167 |
+
s_dxx = d_sum * scale * scale * scale / d;
|
| 168 |
+
s_scale = scale;
|
| 169 |
+
}
|
| 170 |
+
__syncthreads();
|
| 171 |
+
acc_t scale = s_scale;
|
| 172 |
+
acc_t dxx = s_dxx;
|
| 173 |
+
vec_t *__restrict__ input_grad_vec = reinterpret_cast<vec_t *>(input_grad);
|
| 174 |
+
dw_vec_t *__restrict__ temp_weight_grad_vec =
|
| 175 |
+
reinterpret_cast<dw_vec_t *>(temp_weight_grad);
|
| 176 |
+
|
| 177 |
+
for (int64_t vidx = vec_idx; vidx < vec_d; vidx += blockDim.x) {
|
| 178 |
+
vec_t x_vec = input_vec[vec_offset + vidx];
|
| 179 |
+
vec_t dy_vec = output_grad_vec[vec_offset + vidx];
|
| 180 |
+
vec_t w_vec = weight_vec[vidx];
|
| 181 |
+
|
| 182 |
+
vec_t in_grad_vec;
|
| 183 |
+
dw_vec_t tw_grad_vec;
|
| 184 |
+
|
| 185 |
+
#pragma unroll
|
| 186 |
+
for (int i = 0; i < width; ++i) {
|
| 187 |
+
acc_t x = x_vec.data[i];
|
| 188 |
+
acc_t dy = dy_vec.data[i];
|
| 189 |
+
acc_t w = w_vec.data[i];
|
| 190 |
+
|
| 191 |
+
if (input_grad) {
|
| 192 |
+
in_grad_vec.data[i] = scale * dy * w - dxx * x;
|
| 193 |
+
}
|
| 194 |
+
tw_grad_vec.data[i] = dy * x * scale;
|
| 195 |
+
}
|
| 196 |
+
|
| 197 |
+
if (input_grad) {
|
| 198 |
+
input_grad_vec[vec_offset + vidx] = in_grad_vec;
|
| 199 |
+
}
|
| 200 |
+
temp_weight_grad_vec[vec_offset + vidx] = tw_grad_vec;
|
| 201 |
+
}
|
| 202 |
+
}
|
| 203 |
+
|
| 204 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 205 |
+
__global__ std::enable_if_t<(width == 0)>
|
| 206 |
rms_norm_backward_kernel(scalar_t *__restrict__ input_grad, // [..., d]
|
| 207 |
acc_t *__restrict__ temp_weight_grad, // [..., d]
|
| 208 |
const scalar_t *__restrict__ output_grad, // [..., d]
|
|
|
|
| 222 |
sum_square += x * x;
|
| 223 |
}
|
| 224 |
|
| 225 |
+
using BlockReduce = cub::BlockReduce<float2, 1024>;
|
| 226 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 227 |
+
struct SumOp {
|
| 228 |
+
__device__ float2 operator()(const float2 &a, const float2 &b) const {
|
| 229 |
+
return make_float2(a.x + b.x, a.y + b.y);
|
| 230 |
+
}
|
| 231 |
+
};
|
| 232 |
+
float2 thread_sums = make_float2(d_sum, sum_square);
|
| 233 |
+
float2 block_sums =
|
| 234 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 235 |
|
| 236 |
+
d_sum = block_sums.x;
|
| 237 |
+
sum_square = block_sums.y;
|
| 238 |
+
|
| 239 |
+
__shared__ acc_t s_scale;
|
| 240 |
+
__shared__ acc_t s_dxx;
|
| 241 |
+
|
| 242 |
+
if (threadIdx.x == 0) {
|
| 243 |
+
acc_t scale = rsqrtf(sum_square / d + eps);
|
| 244 |
+
s_dxx = d_sum * scale * scale * scale / d;
|
| 245 |
+
s_scale = scale;
|
| 246 |
+
}
|
| 247 |
+
__syncthreads();
|
| 248 |
+
|
| 249 |
+
acc_t scale = s_scale;
|
| 250 |
+
acc_t dxx = s_dxx;
|
| 251 |
|
| 252 |
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 253 |
acc_t x = input[token_idx * d + idx];
|
| 254 |
acc_t dy = output_grad[token_idx * d + idx];
|
| 255 |
acc_t w = weight[idx];
|
| 256 |
|
| 257 |
+
if (input_grad) {
|
| 258 |
+
input_grad[token_idx * d + idx] = scale * dy * w - dxx * x;
|
|
|
|
|
|
|
| 259 |
}
|
| 260 |
+
temp_weight_grad[token_idx * d + idx] = dy * x * scale;
|
| 261 |
}
|
| 262 |
}
|
| 263 |
|
| 264 |
} // namespace motif
|
| 265 |
|
| 266 |
+
#define LAUNCH_RMS_NORM(width) \
|
| 267 |
+
MOTIF_DISPATCH_FLOATING_TYPES(input.scalar_type(), "rms_norm_kernel", [&] { \
|
| 268 |
+
motif::rms_norm_kernel<scalar_t, float, width> \
|
| 269 |
+
<<<grid, block, 0, stream>>>(out.data_ptr<scalar_t>(), \
|
| 270 |
+
input.data_ptr<scalar_t>(), \
|
| 271 |
+
weight.data_ptr<scalar_t>(), eps, d); \
|
| 272 |
+
});
|
| 273 |
+
|
| 274 |
void rms_norm(torch::Tensor &out, // [..., d]
|
| 275 |
const torch::Tensor &input, // [..., d]
|
| 276 |
const torch::Tensor &weight, // [d]
|
|
|
|
| 279 |
AssertTensorNotNull(weight, "weight");
|
| 280 |
// TODO shape check
|
| 281 |
|
|
|
|
|
|
|
| 282 |
int d = input.size(-1);
|
| 283 |
int64_t num_tokens = input.numel() / input.size(-1);
|
| 284 |
dim3 grid(num_tokens);
|
| 285 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 286 |
+
dim3 block(std::min(d, max_block_size));
|
| 287 |
|
| 288 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 289 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 290 |
+
if (d % 8 == 0) {
|
| 291 |
+
LAUNCH_RMS_NORM(8);
|
| 292 |
+
} else {
|
| 293 |
+
LAUNCH_RMS_NORM(0);
|
| 294 |
+
}
|
|
|
|
| 295 |
}
|
| 296 |
|
| 297 |
+
#define LAUNCH_RMS_NORM_BWD(width) \
|
| 298 |
+
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 299 |
+
input.scalar_type(), "rms_norm_backward_kernel", [&] { \
|
| 300 |
+
motif::rms_norm_backward_kernel<scalar_t, float, width> \
|
| 301 |
+
<<<grid, block, 0, stream>>>(input_grad.data_ptr<scalar_t>(), \
|
| 302 |
+
temp_weight_grad.data_ptr<float>(), \
|
| 303 |
+
output_grad.data_ptr<scalar_t>(), \
|
| 304 |
+
input.data_ptr<scalar_t>(), \
|
| 305 |
+
weight.data_ptr<scalar_t>(), eps, d); \
|
| 306 |
+
});
|
| 307 |
+
|
| 308 |
void rms_norm_backward(torch::Tensor &input_grad, // [..., d]
|
| 309 |
+
torch::Tensor &weight_grad, // [d]
|
| 310 |
+
const torch::Tensor &output_grad, // [..., d]
|
| 311 |
+
const torch::Tensor &input, // [..., d]
|
| 312 |
const torch::Tensor &weight, // [d]
|
| 313 |
double eps) {
|
| 314 |
AssertTensorShapeEqual(input, input_grad, "input", "input_grad");
|
|
|
|
| 317 |
// TODO shape check
|
| 318 |
// weight_grad, input_grad can be nullable
|
| 319 |
|
|
|
|
|
|
|
| 320 |
int d = input.size(-1);
|
| 321 |
int64_t num_tokens = input.numel() / input.size(-1);
|
| 322 |
dim3 grid(num_tokens);
|
| 323 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 324 |
+
dim3 block(std::min(d, max_block_size));
|
| 325 |
|
| 326 |
torch::Tensor temp_weight_grad =
|
| 327 |
torch::empty({num_tokens, d}, input.options().dtype(torch::kFloat));
|
| 328 |
|
|
|
|
|
|
|
| 329 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 330 |
+
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 331 |
+
if (d % 8 == 0) {
|
| 332 |
+
LAUNCH_RMS_NORM_BWD(8);
|
| 333 |
+
} else {
|
| 334 |
+
LAUNCH_RMS_NORM_BWD(0);
|
| 335 |
+
}
|
|
|
|
|
|
|
|
|
|
| 336 |
|
| 337 |
if (weight_grad.defined()) {
|
| 338 |
+
torch::Tensor acc =
|
| 339 |
+
torch::empty_like(weight_grad, temp_weight_grad.options());
|
| 340 |
+
at::sum_out(acc, temp_weight_grad, {0});
|
| 341 |
+
weight_grad.copy_(acc);
|
| 342 |
}
|
| 343 |
}
|
benchmarks/README.md
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Benchmark Runner
|
| 2 |
+
|
| 3 |
+
This script benchmarks **forward/backward performance** of several operations (`rms`, `add_rms`, `poly`, `mul_poly`).
|
| 4 |
+
Results can be saved as **CSV files** or **plots**.
|
| 5 |
+
|
| 6 |
+
> **Note**<br>
|
| 7 |
+
> To run the benchmarks, you must select the appropriate Torch version along with the corresponding CUDA/ROCm build from within the `build` directory.
|
| 8 |
+
>
|
| 9 |
+
> **Example:**
|
| 10 |
+
>
|
| 11 |
+
> ```bash
|
| 12 |
+
> export PYTHONPATH=$PYTHONPATH:<YOUR_PATH>/activation/build/torch27-cxx11-cu128-x86_64-linux
|
| 13 |
+
> ```
|
| 14 |
+
|
| 15 |
+
## Usage
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
python main.py --case <CASE> [--plot] [--save-path <DIR>]
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
- `--case` (required): one of `rms`, `add_rms`, `poly`, `mul_poly`
|
| 22 |
+
- `--plot`: save plots instead of CSVs
|
| 23 |
+
- `--save-path`: output directory (default: `./configs/`)
|
| 24 |
+
|
| 25 |
+
## Examples
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
python main.py --case add_rms --save-path ./results/
|
| 29 |
+
python main.py --case poly --plot --save-path ./plots/
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
## Output
|
| 33 |
+
|
| 34 |
+
- CSV: `<case>-fwd-perf.csv`, `<case>-bwd-perf.csv`
|
| 35 |
+
- Plots: `plot_<case>-fwd-perf.png`, `plot_<case>-bwd-perf.png`
|
benchmarks/cases/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
benchmarks/cases/add_rms.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from common.diff_engine import DiffCase
|
| 3 |
+
|
| 4 |
+
import activation
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class FusedAddRMSNorm(torch.nn.Module):
|
| 8 |
+
|
| 9 |
+
def __init__(self, d, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.weight = torch.nn.Parameter(torch.ones(d, dtype=dtype))
|
| 12 |
+
self.eps = eps
|
| 13 |
+
|
| 14 |
+
def forward(self, x, residual):
|
| 15 |
+
return activation.rms_norm((x + residual), self.weight, self.eps)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class AddRMS(DiffCase):
|
| 19 |
+
|
| 20 |
+
def build_inputs(self, bs, sl, hidden, dtype, eps):
|
| 21 |
+
return {
|
| 22 |
+
"x":
|
| 23 |
+
torch.randn(bs, sl, hidden, dtype=dtype, requires_grad=True),
|
| 24 |
+
"residual":
|
| 25 |
+
torch.randn(bs, sl, hidden, dtype=dtype, requires_grad=True),
|
| 26 |
+
"weight":
|
| 27 |
+
torch.ones(hidden, dtype=dtype),
|
| 28 |
+
"dim":
|
| 29 |
+
hidden,
|
| 30 |
+
"eps":
|
| 31 |
+
eps,
|
| 32 |
+
"dtype":
|
| 33 |
+
dtype,
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
def make_naive(self, I):
|
| 37 |
+
m = FusedAddRMSNorm(I["dim"], I["eps"], dtype=I["dtype"])
|
| 38 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 39 |
+
return m
|
| 40 |
+
|
| 41 |
+
def make_cuda(self, I):
|
| 42 |
+
m = activation.layers.FusedAddRMSNorm(I["dim"],
|
| 43 |
+
I["eps"],
|
| 44 |
+
dtype=I["dtype"])
|
| 45 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 46 |
+
return m
|
| 47 |
+
|
| 48 |
+
def forward(self, obj, I):
|
| 49 |
+
return obj(I["x"], I["residual"])
|
| 50 |
+
|
| 51 |
+
def grad_inputs(self, I):
|
| 52 |
+
return [I["x"], I["residual"]]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
CASE = AddRMS()
|
benchmarks/cases/mul_poly.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from common.diff_engine import DiffCase
|
| 3 |
+
|
| 4 |
+
import activation
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class FusedMulPolyNorm(torch.nn.Module):
|
| 8 |
+
|
| 9 |
+
def __init__(self, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.weight = torch.nn.Parameter(torch.ones(3, dtype=dtype) / 3)
|
| 12 |
+
self.bias = torch.nn.Parameter(torch.zeros(1, dtype=dtype))
|
| 13 |
+
self.eps = eps
|
| 14 |
+
|
| 15 |
+
def forward(self, x, mul):
|
| 16 |
+
output = activation.poly_norm(x, self.weight, self.bias, self.eps)
|
| 17 |
+
return output * mul
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class MulPoly(DiffCase):
|
| 21 |
+
|
| 22 |
+
def build_inputs(self, bs, sl, hidden, dtype, eps):
|
| 23 |
+
return {
|
| 24 |
+
"x": torch.randn(bs, sl, hidden, dtype=dtype, requires_grad=True),
|
| 25 |
+
"mul": torch.randn(bs, sl, hidden, dtype=dtype,
|
| 26 |
+
requires_grad=True),
|
| 27 |
+
"weight": torch.ones(3, dtype=dtype),
|
| 28 |
+
"bias": torch.ones(1, dtype=dtype),
|
| 29 |
+
"dim": hidden,
|
| 30 |
+
"eps": eps,
|
| 31 |
+
"dtype": dtype,
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
def make_naive(self, I):
|
| 35 |
+
m = FusedMulPolyNorm(I["eps"], dtype=I["dtype"])
|
| 36 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 37 |
+
m.bias = torch.nn.Parameter(I["bias"].detach().clone())
|
| 38 |
+
return m
|
| 39 |
+
|
| 40 |
+
def make_cuda(self, I):
|
| 41 |
+
m = activation.layers.FusedMulPolyNorm(I["eps"], dtype=I["dtype"])
|
| 42 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 43 |
+
m.bias = torch.nn.Parameter(I["bias"].detach().clone())
|
| 44 |
+
return m
|
| 45 |
+
|
| 46 |
+
def forward(self, obj, I):
|
| 47 |
+
return obj(I["x"], I["mul"])
|
| 48 |
+
|
| 49 |
+
def grad_inputs(self, I):
|
| 50 |
+
return [I["x"], I["mul"]]
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
CASE = MulPoly()
|
benchmarks/cases/poly.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from common.diff_engine import DiffCase
|
| 3 |
+
|
| 4 |
+
import activation
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PolyNorm(torch.nn.Module):
|
| 8 |
+
|
| 9 |
+
def __init__(self, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 10 |
+
super().__init__()
|
| 11 |
+
self.weight = torch.nn.Parameter(torch.ones(3, dtype=dtype) / 3)
|
| 12 |
+
self.bias = torch.nn.Parameter(torch.zeros(1, dtype=dtype))
|
| 13 |
+
self.eps = eps
|
| 14 |
+
|
| 15 |
+
def _norm(self, x):
|
| 16 |
+
return x / torch.sqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
orig_dtype = x.dtype
|
| 20 |
+
x_float = x.to(torch.float32)
|
| 21 |
+
output = (self.weight[0] * self._norm(x_float**3) +
|
| 22 |
+
self.weight[1] * self._norm(x_float**2) +
|
| 23 |
+
self.weight[2] * self._norm(x_float) + self.bias)
|
| 24 |
+
return output.to(orig_dtype)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Poly(DiffCase):
|
| 28 |
+
|
| 29 |
+
def build_inputs(self, bs, sl, hidden, dtype, eps):
|
| 30 |
+
return {
|
| 31 |
+
"x": torch.randn(bs, sl, hidden, dtype=dtype, requires_grad=True),
|
| 32 |
+
"weight": torch.ones(3, dtype=dtype),
|
| 33 |
+
"bias": torch.ones(1, dtype=dtype),
|
| 34 |
+
"dim": hidden,
|
| 35 |
+
"eps": eps,
|
| 36 |
+
"dtype": dtype,
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
def make_naive(self, I):
|
| 40 |
+
m = PolyNorm(I["eps"], dtype=I["dtype"])
|
| 41 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 42 |
+
m.bias = torch.nn.Parameter(I["bias"].detach().clone())
|
| 43 |
+
return m
|
| 44 |
+
|
| 45 |
+
def make_cuda(self, I):
|
| 46 |
+
m = activation.layers.PolyNorm(I["eps"], dtype=I["dtype"])
|
| 47 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 48 |
+
m.bias = torch.nn.Parameter(I["bias"].detach().clone())
|
| 49 |
+
return m
|
| 50 |
+
|
| 51 |
+
def forward(self, obj, I):
|
| 52 |
+
return obj(I["x"])
|
| 53 |
+
|
| 54 |
+
def grad_inputs(self, I):
|
| 55 |
+
return [I["x"]]
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
CASE = Poly()
|
benchmarks/cases/rms.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from common.diff_engine import DiffCase
|
| 3 |
+
|
| 4 |
+
import activation
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class RMS(DiffCase):
|
| 8 |
+
|
| 9 |
+
def build_inputs(self, bs, sl, hidden, dtype, eps):
|
| 10 |
+
return {
|
| 11 |
+
"x": torch.randn(bs, sl, hidden, dtype=dtype, requires_grad=True),
|
| 12 |
+
"weight": torch.ones(hidden, dtype=dtype),
|
| 13 |
+
"dim": hidden,
|
| 14 |
+
"eps": eps,
|
| 15 |
+
"dtype": dtype,
|
| 16 |
+
}
|
| 17 |
+
|
| 18 |
+
def make_naive(self, I):
|
| 19 |
+
m = torch.nn.RMSNorm(I["dim"], I["eps"], dtype=I["dtype"])
|
| 20 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 21 |
+
return m
|
| 22 |
+
|
| 23 |
+
def make_cuda(self, I):
|
| 24 |
+
m = activation.layers.RMSNorm(I["dim"], I["eps"], dtype=I["dtype"])
|
| 25 |
+
m.weight = torch.nn.Parameter(I["weight"].detach().clone())
|
| 26 |
+
return m
|
| 27 |
+
|
| 28 |
+
def forward(self, obj, I):
|
| 29 |
+
return obj(I["x"])
|
| 30 |
+
|
| 31 |
+
def grad_inputs(self, I):
|
| 32 |
+
return [I["x"]]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
CASE = RMS()
|
benchmarks/common/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
benchmarks/common/bench_framework.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections
|
| 2 |
+
import math
|
| 3 |
+
import re
|
| 4 |
+
from typing import Any, Dict, Sequence
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import triton
|
| 8 |
+
|
| 9 |
+
from .diff_engine import DiffCase
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def make_fwd_key(batch_size, seq_len, dim):
|
| 13 |
+
return f"forward : ({batch_size}, {seq_len}, {dim})"
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def make_bwd_key(batch_size, seq_len, dim):
|
| 17 |
+
return f"backward : ({batch_size}, {seq_len}, {dim})"
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_config_string(config_str):
|
| 21 |
+
match = re.match(r"(\w+)\s*:\s*\(\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*\)",
|
| 22 |
+
config_str)
|
| 23 |
+
if not match:
|
| 24 |
+
raise ValueError(f"Invalid config string: {config_str}")
|
| 25 |
+
_, bs, sl, d = match.groups()
|
| 26 |
+
return int(bs), int(sl), int(d)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def make_fwd_benchmark_for_case(
|
| 30 |
+
*,
|
| 31 |
+
case: DiffCase,
|
| 32 |
+
configs: Sequence[tuple[int, int, int]],
|
| 33 |
+
plot_name: str,
|
| 34 |
+
ylabel: str = "us",
|
| 35 |
+
line_vals=("naive", "cuda", "speedup"),
|
| 36 |
+
line_names: Dict[str, str] | None = None,
|
| 37 |
+
dtype=torch.bfloat16,
|
| 38 |
+
eps: float = 1e-6,
|
| 39 |
+
time_unit_scale: float = 1000,
|
| 40 |
+
):
|
| 41 |
+
timings_ms = collections.defaultdict(dict)
|
| 42 |
+
line_vals = list(line_vals)
|
| 43 |
+
line_names = line_names or {v: v.title() for v in line_vals}
|
| 44 |
+
x_vals = [list(_) for _ in configs]
|
| 45 |
+
|
| 46 |
+
@triton.testing.perf_report(
|
| 47 |
+
triton.testing.Benchmark(x_names=["dim", "batch_size", "seq_len"],
|
| 48 |
+
x_vals=x_vals,
|
| 49 |
+
line_arg="provider",
|
| 50 |
+
line_vals=line_vals,
|
| 51 |
+
line_names=[line_names[v] for v in line_vals],
|
| 52 |
+
ylabel=ylabel,
|
| 53 |
+
plot_name=plot_name,
|
| 54 |
+
args={}))
|
| 55 |
+
def bench(dim, batch_size, seq_len, provider):
|
| 56 |
+
key = make_fwd_key(dim, batch_size, seq_len)
|
| 57 |
+
I = case.build_inputs(batch_size, seq_len, dim, dtype, eps)
|
| 58 |
+
if provider == "speedup":
|
| 59 |
+
return timings_ms["naive"][key] / timings_ms["cuda"][key]
|
| 60 |
+
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 61 |
+
run = lambda: case.forward(obj, I)
|
| 62 |
+
ms = triton.testing.do_bench(run)
|
| 63 |
+
timings_ms[provider][key] = ms
|
| 64 |
+
return time_unit_scale * ms
|
| 65 |
+
|
| 66 |
+
return bench
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def make_fwd_benchmark_plot_for_case(
|
| 70 |
+
*,
|
| 71 |
+
case: DiffCase,
|
| 72 |
+
configs: Sequence[tuple[int, int, int]],
|
| 73 |
+
plot_name: str,
|
| 74 |
+
ylabel: str = "Relative Speedup",
|
| 75 |
+
line_vals=("naive", "cuda"),
|
| 76 |
+
line_names: Dict[str, str] | None = None,
|
| 77 |
+
dtype=torch.bfloat16,
|
| 78 |
+
eps: float = 1e-6,
|
| 79 |
+
):
|
| 80 |
+
timings_ms = collections.defaultdict(dict)
|
| 81 |
+
spdup_ratio = list()
|
| 82 |
+
line_vals = list(line_vals)
|
| 83 |
+
line_names = line_names or {v: v.title() for v in line_vals}
|
| 84 |
+
x_vals = [make_fwd_key(*_) for _ in configs]
|
| 85 |
+
x_vals.append("Geometric Mean")
|
| 86 |
+
|
| 87 |
+
@triton.testing.perf_report(
|
| 88 |
+
triton.testing.Benchmark(x_names=["config"],
|
| 89 |
+
x_vals=x_vals,
|
| 90 |
+
line_arg="provider",
|
| 91 |
+
line_vals=line_vals,
|
| 92 |
+
line_names=[line_names[v] for v in line_vals],
|
| 93 |
+
ylabel=ylabel,
|
| 94 |
+
plot_name=plot_name,
|
| 95 |
+
args={}))
|
| 96 |
+
def bench(config, provider):
|
| 97 |
+
if config == "Geometric Mean":
|
| 98 |
+
if provider == "cuda":
|
| 99 |
+
return round(math.prod(spdup_ratio)**(1 / len(spdup_ratio)), 2)
|
| 100 |
+
else:
|
| 101 |
+
return 1.00
|
| 102 |
+
batch_size, seq_len, dim = parse_config_string(config)
|
| 103 |
+
I = case.build_inputs(batch_size, seq_len, dim, dtype, eps)
|
| 104 |
+
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 105 |
+
run = lambda: case.forward(obj, I)
|
| 106 |
+
ms = triton.testing.do_bench(run)
|
| 107 |
+
timings_ms[provider][config] = ms
|
| 108 |
+
if provider == "cuda":
|
| 109 |
+
ratio = timings_ms["naive"][config] / timings_ms["cuda"][config]
|
| 110 |
+
spdup_ratio.append(ratio)
|
| 111 |
+
return round(ratio, 2)
|
| 112 |
+
else:
|
| 113 |
+
return 1.00
|
| 114 |
+
|
| 115 |
+
return bench
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def make_bwd_benchmark_for_case(
|
| 119 |
+
*,
|
| 120 |
+
case: DiffCase,
|
| 121 |
+
configs: Sequence[tuple[int, int, int]],
|
| 122 |
+
plot_name: str,
|
| 123 |
+
ylabel: str = "us",
|
| 124 |
+
line_vals=("naive", "cuda", "speedup"),
|
| 125 |
+
line_names: Dict[str, str] | None = None,
|
| 126 |
+
dtype=torch.bfloat16,
|
| 127 |
+
eps: float = 1e-6,
|
| 128 |
+
time_unit_scale: float = 1000,
|
| 129 |
+
):
|
| 130 |
+
timings_ms = collections.defaultdict(dict)
|
| 131 |
+
line_vals = list(line_vals)
|
| 132 |
+
line_names = line_names or {v: v.title() for v in line_vals}
|
| 133 |
+
x_vals = [list(_) for _ in configs]
|
| 134 |
+
|
| 135 |
+
@triton.testing.perf_report(
|
| 136 |
+
triton.testing.Benchmark(x_names=["dim", "batch_size", "seq_len"],
|
| 137 |
+
x_vals=x_vals,
|
| 138 |
+
line_arg="provider",
|
| 139 |
+
line_vals=line_vals,
|
| 140 |
+
line_names=[line_names[v] for v in line_vals],
|
| 141 |
+
ylabel=ylabel,
|
| 142 |
+
plot_name=plot_name,
|
| 143 |
+
args={}))
|
| 144 |
+
def bench(dim, batch_size, seq_len, provider):
|
| 145 |
+
key = make_bwd_key(dim, batch_size, seq_len)
|
| 146 |
+
I = case.build_inputs(batch_size, seq_len, dim, dtype, eps)
|
| 147 |
+
if provider == "speedup":
|
| 148 |
+
return timings_ms["naive"][key] / timings_ms["cuda"][key]
|
| 149 |
+
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 150 |
+
y = case.forward(obj, I)
|
| 151 |
+
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 152 |
+
g = torch.randn_like(y)
|
| 153 |
+
run = lambda: torch.autograd.grad(y,
|
| 154 |
+
gin,
|
| 155 |
+
g,
|
| 156 |
+
retain_graph=True,
|
| 157 |
+
create_graph=False,
|
| 158 |
+
allow_unused=False)
|
| 159 |
+
ms = triton.testing.do_bench(run)
|
| 160 |
+
timings_ms[provider][key] = ms
|
| 161 |
+
return time_unit_scale * ms
|
| 162 |
+
|
| 163 |
+
return bench
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def make_bwd_benchmark_plot_for_case(
|
| 167 |
+
*,
|
| 168 |
+
case: DiffCase,
|
| 169 |
+
configs: Sequence[tuple[int, int, int]],
|
| 170 |
+
plot_name: str,
|
| 171 |
+
ylabel: str = "Relative Speedup",
|
| 172 |
+
line_vals=("naive", "cuda"),
|
| 173 |
+
line_names: Dict[str, str] | None = None,
|
| 174 |
+
dtype=torch.bfloat16,
|
| 175 |
+
eps: float = 1e-6,
|
| 176 |
+
):
|
| 177 |
+
timings_ms = collections.defaultdict(dict)
|
| 178 |
+
spdup_ratio = list()
|
| 179 |
+
line_vals = list(line_vals)
|
| 180 |
+
line_names = line_names or {v: v.title() for v in line_vals}
|
| 181 |
+
x_vals = [make_bwd_key(*_) for _ in configs]
|
| 182 |
+
x_vals.append("Geometric Mean")
|
| 183 |
+
|
| 184 |
+
@triton.testing.perf_report(
|
| 185 |
+
triton.testing.Benchmark(x_names=["config"],
|
| 186 |
+
x_vals=x_vals,
|
| 187 |
+
line_arg="provider",
|
| 188 |
+
line_vals=line_vals,
|
| 189 |
+
line_names=[line_names[v] for v in line_vals],
|
| 190 |
+
ylabel=ylabel,
|
| 191 |
+
plot_name=plot_name,
|
| 192 |
+
args={}))
|
| 193 |
+
def bench(config, provider):
|
| 194 |
+
if config == "Geometric Mean":
|
| 195 |
+
if provider == "cuda":
|
| 196 |
+
return round(math.prod(spdup_ratio)**(1 / len(spdup_ratio)), 2)
|
| 197 |
+
else:
|
| 198 |
+
return 1.00
|
| 199 |
+
batch_size, seq_len, dim = parse_config_string(config)
|
| 200 |
+
I = case.build_inputs(batch_size, seq_len, dim, dtype, eps)
|
| 201 |
+
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 202 |
+
y = case.forward(obj, I)
|
| 203 |
+
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 204 |
+
g = torch.randn_like(y)
|
| 205 |
+
run = lambda: torch.autograd.grad(y,
|
| 206 |
+
gin,
|
| 207 |
+
g,
|
| 208 |
+
retain_graph=True,
|
| 209 |
+
create_graph=False,
|
| 210 |
+
allow_unused=False)
|
| 211 |
+
ms = triton.testing.do_bench(run)
|
| 212 |
+
timings_ms[provider][config] = ms
|
| 213 |
+
if provider == "cuda":
|
| 214 |
+
ratio = timings_ms["naive"][config] / timings_ms["cuda"][config]
|
| 215 |
+
spdup_ratio.append(ratio)
|
| 216 |
+
return round(ratio, 2)
|
| 217 |
+
else:
|
| 218 |
+
return 1.00
|
| 219 |
+
|
| 220 |
+
return bench
|
benchmarks/common/diff_engine.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Any, Dict, Sequence
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class DiffCase(ABC):
|
| 8 |
+
|
| 9 |
+
@abstractmethod
|
| 10 |
+
def build_inputs(self, hidden: int, bs: int, sl: int, dtype: torch.dtype,
|
| 11 |
+
eps: float) -> Dict[str, Any]:
|
| 12 |
+
...
|
| 13 |
+
|
| 14 |
+
@abstractmethod
|
| 15 |
+
def make_naive(self, I: Dict[str, Any]) -> Any:
|
| 16 |
+
...
|
| 17 |
+
|
| 18 |
+
@abstractmethod
|
| 19 |
+
def make_cuda(self, I: Dict[str, Any]) -> Any:
|
| 20 |
+
...
|
| 21 |
+
|
| 22 |
+
@abstractmethod
|
| 23 |
+
def forward(self, obj: Any, I: Dict[str, Any]) -> torch.Tensor:
|
| 24 |
+
...
|
| 25 |
+
|
| 26 |
+
@abstractmethod
|
| 27 |
+
def grad_inputs(self, I: Dict[str, Any]) -> Sequence[torch.Tensor]:
|
| 28 |
+
...
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def _clone_payload(d, device):
|
| 32 |
+
out = {}
|
| 33 |
+
for k, v in d.items():
|
| 34 |
+
if isinstance(v, torch.Tensor):
|
| 35 |
+
t = v.detach().clone().to(device)
|
| 36 |
+
t.requires_grad_(v.requires_grad)
|
| 37 |
+
out[k] = t
|
| 38 |
+
else:
|
| 39 |
+
out[k] = v
|
| 40 |
+
return out
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def _unit_grad_like(y):
|
| 44 |
+
g = torch.randn_like(y)
|
| 45 |
+
n = g.norm()
|
| 46 |
+
return g if n == 0 else g / n
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def calculate_diff(
|
| 50 |
+
case: DiffCase,
|
| 51 |
+
*,
|
| 52 |
+
batch_size: int,
|
| 53 |
+
seq_len: int,
|
| 54 |
+
hidden_size: int,
|
| 55 |
+
dtype=torch.bfloat16,
|
| 56 |
+
eps: float = 1e-6,
|
| 57 |
+
atol: float = 1e-2,
|
| 58 |
+
rtol: float = 1e-2,
|
| 59 |
+
device="cuda",
|
| 60 |
+
) -> None:
|
| 61 |
+
base = case.build_inputs(hidden_size, batch_size, seq_len, dtype, eps)
|
| 62 |
+
I_n = _clone_payload(base, device)
|
| 63 |
+
I_c = _clone_payload(base, device)
|
| 64 |
+
obj_n = case.make_naive(I_n)
|
| 65 |
+
obj_c = case.make_cuda(I_c)
|
| 66 |
+
y_n = case.forward(obj_n, I_n)
|
| 67 |
+
y_c = case.forward(obj_c, I_c)
|
| 68 |
+
torch.testing.assert_close(y_n, y_c, atol=atol, rtol=rtol)
|
| 69 |
+
gin_n = list(case.grad_inputs(I_n)) + list(obj_n.parameters())
|
| 70 |
+
gin_c = list(case.grad_inputs(I_c)) + list(obj_c.parameters())
|
| 71 |
+
g = _unit_grad_like(y_n).to(device)
|
| 72 |
+
ng = torch.autograd.grad(y_n,
|
| 73 |
+
gin_n,
|
| 74 |
+
g,
|
| 75 |
+
retain_graph=False,
|
| 76 |
+
create_graph=False,
|
| 77 |
+
allow_unused=False)
|
| 78 |
+
cg = torch.autograd.grad(y_c,
|
| 79 |
+
gin_c,
|
| 80 |
+
g,
|
| 81 |
+
retain_graph=False,
|
| 82 |
+
create_graph=False,
|
| 83 |
+
allow_unused=False)
|
| 84 |
+
torch.testing.assert_close(ng, cg, atol=atol, rtol=rtol)
|
| 85 |
+
print("✅ forward + backward match")
|
benchmarks/plots/h100/add_rms/plot_add_rms-bwd-perf.png
ADDED

|
benchmarks/plots/h100/add_rms/plot_add_rms-fwd-perf.png
ADDED

|
benchmarks/plots/h100/mul_poly/plot_mul_poly-bwd-perf.png
ADDED

|
benchmarks/plots/h100/mul_poly/plot_mul_poly-fwd-perf.png
ADDED

|
benchmarks/plots/h100/poly/plot_poly-bwd-perf.png
ADDED

|
benchmarks/plots/h100/poly/plot_poly-fwd-perf.png
ADDED
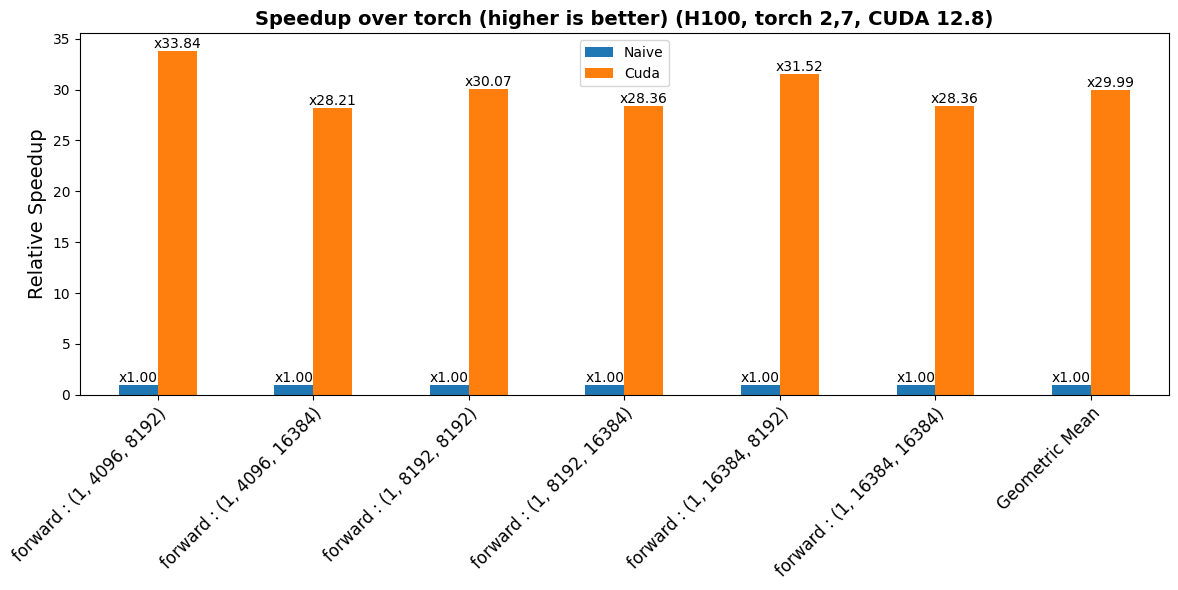
|
benchmarks/plots/h100/rms/plot_rms-bwd-perf.png
ADDED

|
benchmarks/plots/h100/rms/plot_rms-fwd-perf.png
ADDED

|
benchmarks/plots/mi250/add_rms/plot_add_rms-bwd-perf.png
ADDED

|
benchmarks/plots/mi250/add_rms/plot_add_rms-fwd-perf.png
ADDED

|
benchmarks/plots/mi250/mul_poly/plot_mul_poly-bwd-perf.png
ADDED

|
benchmarks/plots/mi250/mul_poly/plot_mul_poly-fwd-perf.png
ADDED

|
benchmarks/plots/mi250/poly/plot_poly-bwd-perf.png
ADDED

|
benchmarks/plots/mi250/poly/plot_poly-fwd-perf.png
ADDED
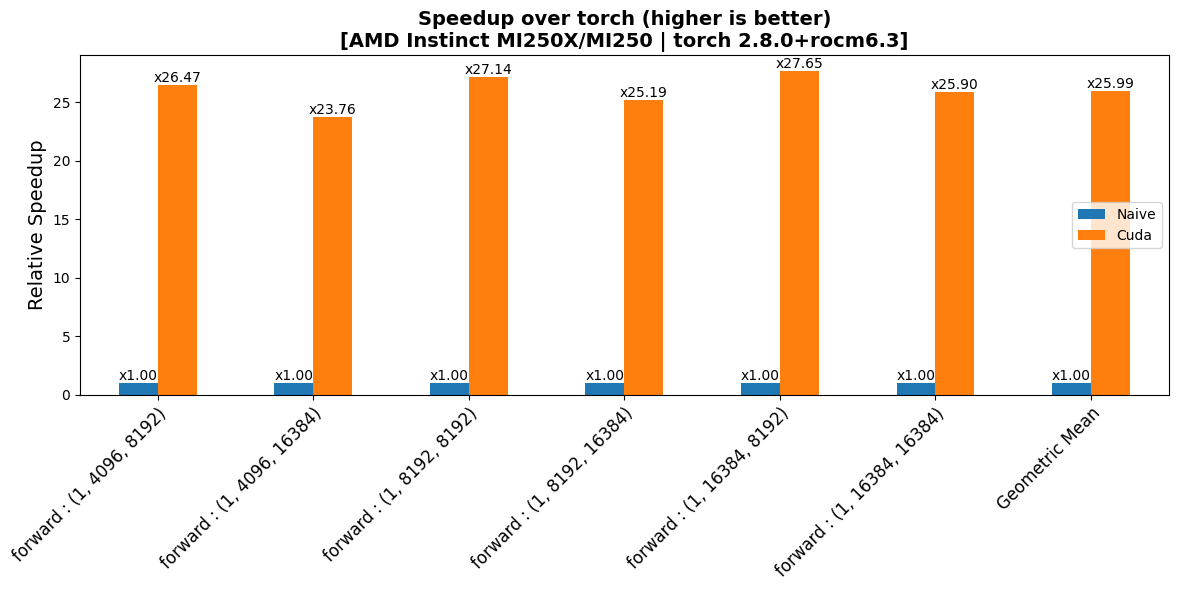
|
benchmarks/plots/mi250/rms/plot_rms-bwd-perf.png
ADDED
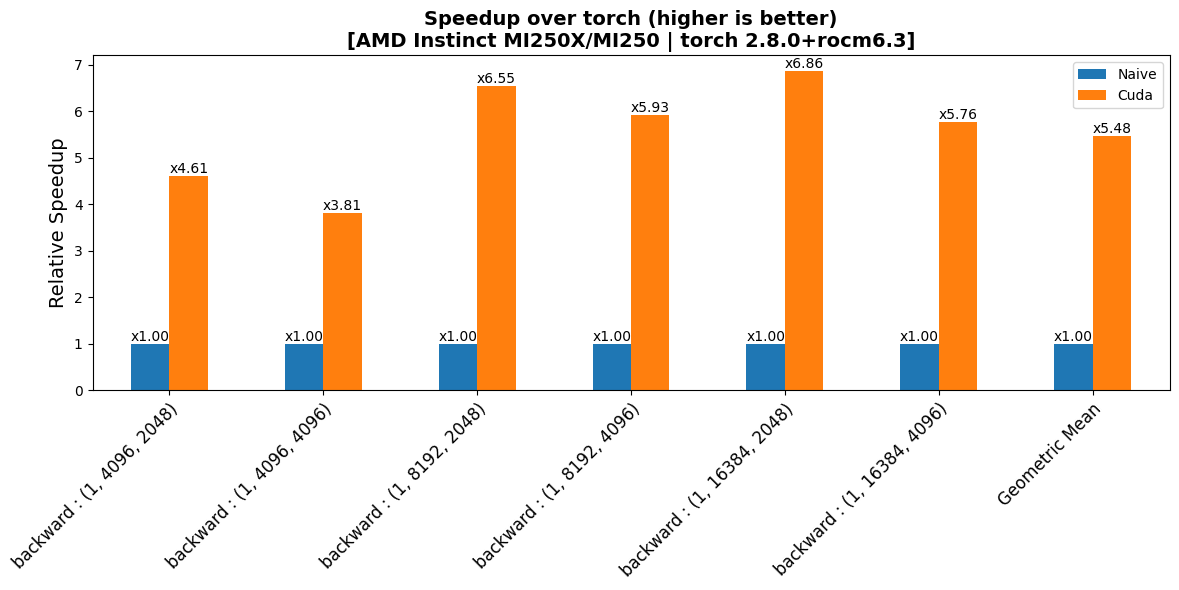
|
benchmarks/plots/mi250/rms/plot_rms-fwd-perf.png
ADDED
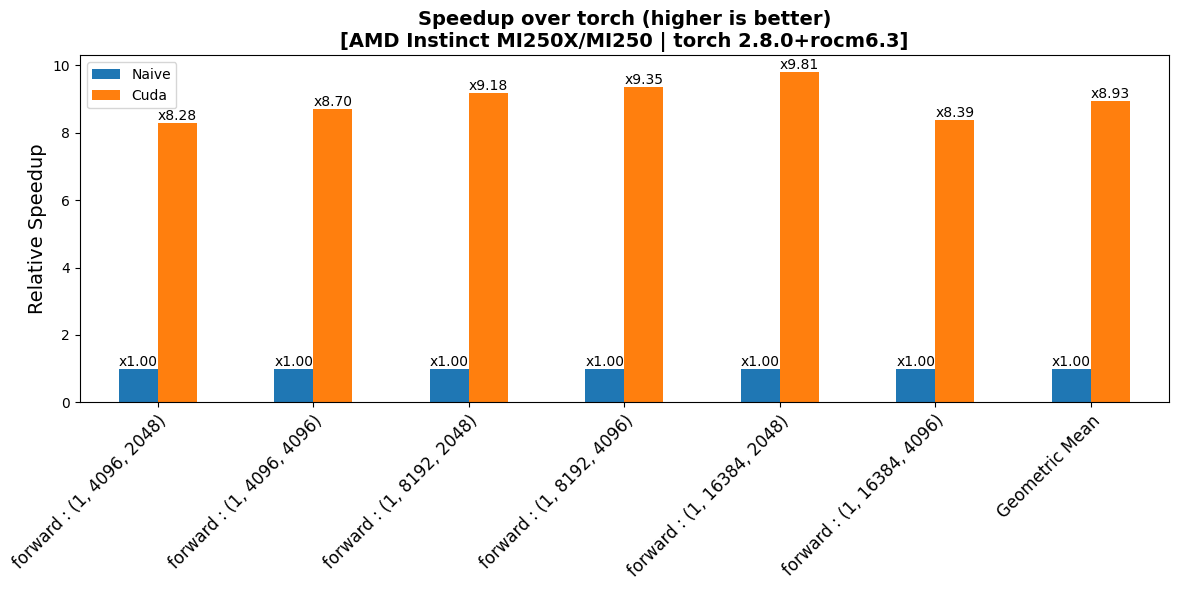
|
benchmarks/run_cases.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import importlib
|
| 4 |
+
import itertools
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from common.bench_framework import (make_bwd_benchmark_for_case,
|
| 9 |
+
make_bwd_benchmark_plot_for_case,
|
| 10 |
+
make_fwd_benchmark_for_case,
|
| 11 |
+
make_fwd_benchmark_plot_for_case)
|
| 12 |
+
from common.diff_engine import DiffCase, calculate_diff
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def make_title_tag():
|
| 16 |
+
if torch.cuda.is_available():
|
| 17 |
+
dev_name = torch.cuda.get_device_name(0)
|
| 18 |
+
else:
|
| 19 |
+
dev_name = "CPU"
|
| 20 |
+
|
| 21 |
+
torch_ver = torch.__version__
|
| 22 |
+
|
| 23 |
+
return f"[{dev_name} | torch {torch_ver}]"
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def plot_result(r_path):
|
| 27 |
+
import matplotlib.pyplot as plt
|
| 28 |
+
import pandas as pd
|
| 29 |
+
df = pd.read_csv(r_path + ".csv")
|
| 30 |
+
plt.figure(figsize=(12, 6))
|
| 31 |
+
ax = df.plot(x="config", y=["Naive", "Cuda"], kind="bar", ax=plt.gca())
|
| 32 |
+
ax.set_title("Speedup over torch (higher is better)\n" + make_title_tag(),
|
| 33 |
+
fontsize=14,
|
| 34 |
+
fontweight="bold")
|
| 35 |
+
ax.set_ylabel("Relative Speedup", fontsize=14)
|
| 36 |
+
ax.set_xlabel("")
|
| 37 |
+
plt.xticks(rotation=45, fontsize=12, ha="right", rotation_mode="anchor")
|
| 38 |
+
for container in ax.containers:
|
| 39 |
+
labels = [f"x{v.get_height():.2f}" for v in container]
|
| 40 |
+
ax.bar_label(container, labels=labels, label_type="edge", fontsize=10)
|
| 41 |
+
plt.tight_layout()
|
| 42 |
+
plt.savefig(r_path + ".png", bbox_inches="tight")
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def main():
|
| 46 |
+
ap = argparse.ArgumentParser()
|
| 47 |
+
ap.add_argument("--case",
|
| 48 |
+
choices=["rms", "add_rms", "poly", "mul_poly"],
|
| 49 |
+
required=True)
|
| 50 |
+
ap.add_argument("--plot", action="store_true")
|
| 51 |
+
ap.add_argument(
|
| 52 |
+
"--save-path",
|
| 53 |
+
type=str,
|
| 54 |
+
default="./configs/",
|
| 55 |
+
help="Path to save benchmark results",
|
| 56 |
+
)
|
| 57 |
+
args = ap.parse_args()
|
| 58 |
+
|
| 59 |
+
torch.set_default_device("cuda")
|
| 60 |
+
mod = importlib.import_module(f"cases.{args.case}")
|
| 61 |
+
case: DiffCase = mod.CASE
|
| 62 |
+
|
| 63 |
+
calculate_diff(
|
| 64 |
+
case,
|
| 65 |
+
batch_size=2,
|
| 66 |
+
seq_len=128,
|
| 67 |
+
hidden_size=4096,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
save_dir = os.path.join(args.save_path, args.case)
|
| 71 |
+
if args.plot:
|
| 72 |
+
batch_size_range = [1]
|
| 73 |
+
seq_length_range = [4096, 8192, 16384]
|
| 74 |
+
dim = [8192, 16384] if "poly" in args.case else [2048, 4096]
|
| 75 |
+
configs = list(
|
| 76 |
+
itertools.product(batch_size_range, seq_length_range, dim))
|
| 77 |
+
plot_name = f"plot_{args.case}-fwd-perf"
|
| 78 |
+
bench = make_fwd_benchmark_plot_for_case(
|
| 79 |
+
case=case,
|
| 80 |
+
configs=configs,
|
| 81 |
+
plot_name=plot_name,
|
| 82 |
+
line_names={
|
| 83 |
+
"naive": "Naive",
|
| 84 |
+
"cuda": "Cuda",
|
| 85 |
+
},
|
| 86 |
+
)
|
| 87 |
+
bench.run(print_data=True, save_path=save_dir)
|
| 88 |
+
plot_result(os.path.join(save_dir, plot_name))
|
| 89 |
+
|
| 90 |
+
plot_name = f"plot_{args.case}-bwd-perf"
|
| 91 |
+
bench = make_bwd_benchmark_plot_for_case(
|
| 92 |
+
case=case,
|
| 93 |
+
configs=configs,
|
| 94 |
+
plot_name=plot_name,
|
| 95 |
+
line_names={
|
| 96 |
+
"naive": "Naive",
|
| 97 |
+
"cuda": "Cuda",
|
| 98 |
+
},
|
| 99 |
+
)
|
| 100 |
+
bench.run(print_data=True, save_path=save_dir)
|
| 101 |
+
plot_result(os.path.join(save_dir, plot_name))
|
| 102 |
+
for f in glob.glob(os.path.join(save_dir, "*.html")) + glob.glob(
|
| 103 |
+
os.path.join(save_dir, "*.csv")):
|
| 104 |
+
os.remove(f)
|
| 105 |
+
else:
|
| 106 |
+
batch_size_range = [2**i for i in range(0, 4, 1)]
|
| 107 |
+
seq_length_range = [2**i for i in range(10, 14, 1)]
|
| 108 |
+
dim = [8192, 16384] if "poly" in args.case else [2048, 4096]
|
| 109 |
+
configs = list(
|
| 110 |
+
itertools.product(dim, batch_size_range, seq_length_range))
|
| 111 |
+
|
| 112 |
+
bench = make_fwd_benchmark_for_case(
|
| 113 |
+
case=case,
|
| 114 |
+
configs=configs,
|
| 115 |
+
plot_name=f"{args.case}-fwd-perf",
|
| 116 |
+
line_names={
|
| 117 |
+
"naive": "Naive",
|
| 118 |
+
"cuda": "Cuda",
|
| 119 |
+
"speedup": "SpeedUp"
|
| 120 |
+
},
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
bench.run(print_data=True, save_path=save_dir)
|
| 124 |
+
|
| 125 |
+
bench = make_bwd_benchmark_for_case(
|
| 126 |
+
case=case,
|
| 127 |
+
configs=configs,
|
| 128 |
+
plot_name=f"{args.case}-bwd-perf",
|
| 129 |
+
line_names={
|
| 130 |
+
"naive": "Naive",
|
| 131 |
+
"cuda": "Cuda",
|
| 132 |
+
"speedup": "SpeedUp"
|
| 133 |
+
},
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
bench.run(print_data=True, save_path=save_dir)
|
| 137 |
+
for f in glob.glob(os.path.join(save_dir, "*.html")) + glob.glob(
|
| 138 |
+
os.path.join(save_dir, "*.png")):
|
| 139 |
+
os.remove(f)
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
if __name__ == "__main__":
|
| 143 |
+
main()
|
build.toml
CHANGED
|
@@ -13,9 +13,10 @@ backend = "rocm"
|
|
| 13 |
rocm-archs = [ "gfx90a", "gfx942" ]
|
| 14 |
src = [
|
| 15 |
"activation/poly_norm.cu",
|
|
|
|
| 16 |
"activation/rms_norm.cu",
|
|
|
|
| 17 |
"activation/cuda_compat.h",
|
| 18 |
-
"activation/block_reduce.h",
|
| 19 |
"activation/dispatch_utils.h",
|
| 20 |
"activation/assert_utils.h",
|
| 21 |
"activation/atomic_utils.h",
|
|
@@ -26,9 +27,10 @@ depends = [ "torch" ]
|
|
| 26 |
backend = "cuda"
|
| 27 |
src = [
|
| 28 |
"activation/poly_norm.cu",
|
|
|
|
| 29 |
"activation/rms_norm.cu",
|
|
|
|
| 30 |
"activation/cuda_compat.h",
|
| 31 |
-
"activation/block_reduce.h",
|
| 32 |
"activation/dispatch_utils.h",
|
| 33 |
"activation/assert_utils.h",
|
| 34 |
"activation/atomic_utils.h",
|
|
|
|
| 13 |
rocm-archs = [ "gfx90a", "gfx942" ]
|
| 14 |
src = [
|
| 15 |
"activation/poly_norm.cu",
|
| 16 |
+
"activation/fused_mul_poly_norm.cu",
|
| 17 |
"activation/rms_norm.cu",
|
| 18 |
+
"activation/fused_add_rms_norm.cu",
|
| 19 |
"activation/cuda_compat.h",
|
|
|
|
| 20 |
"activation/dispatch_utils.h",
|
| 21 |
"activation/assert_utils.h",
|
| 22 |
"activation/atomic_utils.h",
|
|
|
|
| 27 |
backend = "cuda"
|
| 28 |
src = [
|
| 29 |
"activation/poly_norm.cu",
|
| 30 |
+
"activation/fused_mul_poly_norm.cu",
|
| 31 |
"activation/rms_norm.cu",
|
| 32 |
+
"activation/fused_add_rms_norm.cu",
|
| 33 |
"activation/cuda_compat.h",
|
|
|
|
| 34 |
"activation/dispatch_utils.h",
|
| 35 |
"activation/assert_utils.h",
|
| 36 |
"activation/atomic_utils.h",
|
build/torch27-cxx11-cu118-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
@@ -15,6 +15,16 @@ def poly_norm(
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
def rms_norm(
|
| 19 |
x: torch.Tensor,
|
| 20 |
weight: torch.Tensor,
|
|
@@ -23,8 +33,20 @@ def rms_norm(
|
|
| 23 |
return RMSNormFunction.apply(x, weight, eps)
|
| 24 |
|
| 25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
__all__ = [
|
| 27 |
"poly_norm",
|
|
|
|
|
|
|
|
|
|
| 28 |
"layers",
|
| 29 |
"ops",
|
| 30 |
]
|
|
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
| 18 |
+
def fused_mul_poly_norm(
|
| 19 |
+
x: torch.Tensor,
|
| 20 |
+
mul: torch.Tensor,
|
| 21 |
+
weight: torch.Tensor,
|
| 22 |
+
bias: torch.Tensor,
|
| 23 |
+
eps: float = 1e-6,
|
| 24 |
+
) -> None:
|
| 25 |
+
return FusedMulPolyNormFunction.apply(x, mul, weight, bias, eps)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
def rms_norm(
|
| 29 |
x: torch.Tensor,
|
| 30 |
weight: torch.Tensor,
|
|
|
|
| 33 |
return RMSNormFunction.apply(x, weight, eps)
|
| 34 |
|
| 35 |
|
| 36 |
+
def fused_add_rms_norm(
|
| 37 |
+
x: torch.Tensor,
|
| 38 |
+
residual: torch.Tensor,
|
| 39 |
+
weight: torch.Tensor,
|
| 40 |
+
eps: float = 1e-6,
|
| 41 |
+
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)[0]
|
| 43 |
+
|
| 44 |
+
|
| 45 |
__all__ = [
|
| 46 |
"poly_norm",
|
| 47 |
+
"fused_mul_poly_norm",
|
| 48 |
+
"rms_norm",
|
| 49 |
+
"fused_add_rms_norm",
|
| 50 |
"layers",
|
| 51 |
"ops",
|
| 52 |
]
|
tests/perf.png → build/torch27-cxx11-cu118-x86_64-linux/activation/_activation_20250907180255.abi3.so
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d21a85bf21aa74f1281541e658acfd4f4326d902efe3578b059eccf054443284
|
| 3 |
+
size 8089696
|
build/torch27-cxx11-cu118-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_20250907180255
|
| 3 |
+
ops = torch.ops._activation_20250907180255
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_20250907180255::{op_name}"
|
build/torch27-cxx11-cu118-x86_64-linux/activation/layers.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
@@ -28,6 +28,30 @@ class PolyNorm(nn.Module):
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
class RMSNorm(nn.Module):
|
| 32 |
|
| 33 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
@@ -46,3 +70,25 @@ class RMSNorm(nn.Module):
|
|
| 46 |
Resets parameters based on their initialization used in __init__.
|
| 47 |
"""
|
| 48 |
init.ones_(self.weight)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
| 31 |
+
class FusedMulPolyNorm(nn.Module):
|
| 32 |
+
|
| 33 |
+
def __init__(self, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.weight = torch.nn.Parameter(torch.ones(3, dtype=dtype) / 3)
|
| 36 |
+
self.bias = torch.nn.Parameter(torch.zeros(1, dtype=dtype))
|
| 37 |
+
self.eps = eps
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self,
|
| 41 |
+
x: torch.Tensor,
|
| 42 |
+
mul: torch.Tensor,
|
| 43 |
+
):
|
| 44 |
+
return FusedMulPolyNormFunction.apply(x, mul, self.weight, self.bias,
|
| 45 |
+
self.eps)
|
| 46 |
+
|
| 47 |
+
def reset_parameters(self) -> None:
|
| 48 |
+
"""
|
| 49 |
+
Resets parameters based on their initialization used in __init__.
|
| 50 |
+
"""
|
| 51 |
+
init.ones_(self.weight)
|
| 52 |
+
init.zeros_(self.bias)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
class RMSNorm(nn.Module):
|
| 56 |
|
| 57 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
|
|
| 70 |
Resets parameters based on their initialization used in __init__.
|
| 71 |
"""
|
| 72 |
init.ones_(self.weight)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class FusedAddRMSNorm(nn.Module):
|
| 76 |
+
|
| 77 |
+
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 78 |
+
super().__init__()
|
| 79 |
+
self.weight = torch.nn.Parameter(torch.ones(dim, dtype=dtype))
|
| 80 |
+
self.eps = eps
|
| 81 |
+
|
| 82 |
+
def forward(
|
| 83 |
+
self,
|
| 84 |
+
x: torch.Tensor,
|
| 85 |
+
residual: torch.Tensor,
|
| 86 |
+
):
|
| 87 |
+
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)[0]
|
| 89 |
+
|
| 90 |
+
def reset_parameters(self) -> None:
|
| 91 |
+
"""
|
| 92 |
+
Resets parameters based on their initialization used in __init__.
|
| 93 |
+
"""
|
| 94 |
+
init.ones_(self.weight)
|
build/torch27-cxx11-cu118-x86_64-linux/activation/poly_norm.py
CHANGED
|
@@ -37,3 +37,40 @@ class PolyNormFunction(torch.autograd.Function):
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class FusedMulPolyNormFunction(torch.autograd.Function):
|
| 43 |
+
# Note that forward, setup_context, and backward are @staticmethods
|
| 44 |
+
@staticmethod
|
| 45 |
+
def forward(input, mul, weight, bias, eps):
|
| 46 |
+
output = torch.empty_like(input)
|
| 47 |
+
ops.fused_mul_poly_norm(output, input, mul, weight, bias, eps)
|
| 48 |
+
return output
|
| 49 |
+
|
| 50 |
+
@staticmethod
|
| 51 |
+
# inputs is a Tuple of all of the inputs passed to forward.
|
| 52 |
+
# output is the output of the forward().
|
| 53 |
+
def setup_context(ctx, inputs, output):
|
| 54 |
+
input, mul, weight, bias, eps = inputs
|
| 55 |
+
ctx.save_for_backward(input, mul, weight, bias)
|
| 56 |
+
ctx.eps = eps
|
| 57 |
+
|
| 58 |
+
# This function has only a single output, so it gets only one gradient
|
| 59 |
+
@staticmethod
|
| 60 |
+
def backward(ctx, output_grad):
|
| 61 |
+
input, mul, weight, bias = ctx.saved_tensors
|
| 62 |
+
eps = ctx.eps
|
| 63 |
+
|
| 64 |
+
input_grad = torch.empty_like(
|
| 65 |
+
input) if ctx.needs_input_grad[0] else None
|
| 66 |
+
mul_grad = torch.empty_like(mul) if ctx.needs_input_grad[1] else None
|
| 67 |
+
weight_grad = torch.empty_like(
|
| 68 |
+
weight) if ctx.needs_input_grad[2] else None
|
| 69 |
+
bias_grad = (torch.empty(1, dtype=weight.dtype, device=weight.device)
|
| 70 |
+
if ctx.needs_input_grad[3] else None)
|
| 71 |
+
|
| 72 |
+
ops.fused_mul_poly_norm_backward(input_grad, mul_grad, weight_grad,
|
| 73 |
+
bias_grad, output_grad, input, mul,
|
| 74 |
+
weight, bias, eps)
|
| 75 |
+
|
| 76 |
+
return input_grad, mul_grad, weight_grad, bias_grad, None
|
build/torch27-cxx11-cu118-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -35,3 +35,50 @@ class RMSNormFunction(torch.autograd.Function):
|
|
| 35 |
weight, eps)
|
| 36 |
|
| 37 |
return input_grad, weight_grad, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
weight, eps)
|
| 36 |
|
| 37 |
return input_grad, weight_grad, None
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# Inherit from Function
|
| 41 |
+
class FusedAddRMSNormFunction(torch.autograd.Function):
|
| 42 |
+
# Note that forward, setup_context, and backward are @staticmethods
|
| 43 |
+
@staticmethod
|
| 44 |
+
def forward(input, residual, weight, eps):
|
| 45 |
+
output = torch.empty_like(input)
|
| 46 |
+
add_output = torch.empty_like(input)
|
| 47 |
+
ops.fused_add_rms_norm(output, add_output, input, residual, weight,
|
| 48 |
+
eps)
|
| 49 |
+
return output, add_output
|
| 50 |
+
|
| 51 |
+
@staticmethod
|
| 52 |
+
# inputs is a Tuple of all of the inputs passed to forward.
|
| 53 |
+
# output is the output of the forward().
|
| 54 |
+
def setup_context(ctx, inputs, outputs):
|
| 55 |
+
_, _, weight, eps = inputs
|
| 56 |
+
_, add_output = outputs
|
| 57 |
+
ctx.mark_non_differentiable(add_output)
|
| 58 |
+
ctx.set_materialize_grads(False)
|
| 59 |
+
ctx.save_for_backward(weight, add_output)
|
| 60 |
+
ctx.eps = eps
|
| 61 |
+
|
| 62 |
+
# This function only needs one gradient
|
| 63 |
+
@staticmethod
|
| 64 |
+
def backward(ctx, output_grad, _):
|
| 65 |
+
weight, add_output = ctx.saved_tensors
|
| 66 |
+
eps = ctx.eps
|
| 67 |
+
|
| 68 |
+
if output_grad is None:
|
| 69 |
+
output_grad = torch.zeros_like(add_output)
|
| 70 |
+
|
| 71 |
+
need_in = ctx.needs_input_grad[0]
|
| 72 |
+
need_res = ctx.needs_input_grad[1]
|
| 73 |
+
|
| 74 |
+
grad = torch.empty_like(output_grad) if need_in or need_res else None
|
| 75 |
+
|
| 76 |
+
weight_grad = torch.empty_like(
|
| 77 |
+
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
+
|
| 79 |
+
ops.rms_norm_backward(grad, weight_grad, output_grad, add_output,
|
| 80 |
+
weight, eps)
|
| 81 |
+
input_grad = grad if need_in else None
|
| 82 |
+
residual_grad = grad if need_res else None
|
| 83 |
+
|
| 84 |
+
return input_grad, residual_grad, weight_grad, None
|
build/torch27-cxx11-cu126-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
@@ -15,6 +15,16 @@ def poly_norm(
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
def rms_norm(
|
| 19 |
x: torch.Tensor,
|
| 20 |
weight: torch.Tensor,
|
|
@@ -23,8 +33,20 @@ def rms_norm(
|
|
| 23 |
return RMSNormFunction.apply(x, weight, eps)
|
| 24 |
|
| 25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
__all__ = [
|
| 27 |
"poly_norm",
|
|
|
|
|
|
|
|
|
|
| 28 |
"layers",
|
| 29 |
"ops",
|
| 30 |
]
|
|
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
| 18 |
+
def fused_mul_poly_norm(
|
| 19 |
+
x: torch.Tensor,
|
| 20 |
+
mul: torch.Tensor,
|
| 21 |
+
weight: torch.Tensor,
|
| 22 |
+
bias: torch.Tensor,
|
| 23 |
+
eps: float = 1e-6,
|
| 24 |
+
) -> None:
|
| 25 |
+
return FusedMulPolyNormFunction.apply(x, mul, weight, bias, eps)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
def rms_norm(
|
| 29 |
x: torch.Tensor,
|
| 30 |
weight: torch.Tensor,
|
|
|
|
| 33 |
return RMSNormFunction.apply(x, weight, eps)
|
| 34 |
|
| 35 |
|
| 36 |
+
def fused_add_rms_norm(
|
| 37 |
+
x: torch.Tensor,
|
| 38 |
+
residual: torch.Tensor,
|
| 39 |
+
weight: torch.Tensor,
|
| 40 |
+
eps: float = 1e-6,
|
| 41 |
+
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)[0]
|
| 43 |
+
|
| 44 |
+
|
| 45 |
__all__ = [
|
| 46 |
"poly_norm",
|
| 47 |
+
"fused_mul_poly_norm",
|
| 48 |
+
"rms_norm",
|
| 49 |
+
"fused_add_rms_norm",
|
| 50 |
"layers",
|
| 51 |
"ops",
|
| 52 |
]
|
build/torch27-cxx11-cu126-x86_64-linux/activation/_activation_20250907180255.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:74d4955271509451b946495da75f69a0f978e7258b8303fe3c077e585c0d3e6a
|
| 3 |
+
size 8272456
|
build/torch27-cxx11-cu126-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_20250907180255
|
| 3 |
+
ops = torch.ops._activation_20250907180255
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_20250907180255::{op_name}"
|
build/torch27-cxx11-cu126-x86_64-linux/activation/layers.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
@@ -28,6 +28,30 @@ class PolyNorm(nn.Module):
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
class RMSNorm(nn.Module):
|
| 32 |
|
| 33 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
@@ -46,3 +70,25 @@ class RMSNorm(nn.Module):
|
|
| 46 |
Resets parameters based on their initialization used in __init__.
|
| 47 |
"""
|
| 48 |
init.ones_(self.weight)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
| 31 |
+
class FusedMulPolyNorm(nn.Module):
|
| 32 |
+
|
| 33 |
+
def __init__(self, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.weight = torch.nn.Parameter(torch.ones(3, dtype=dtype) / 3)
|
| 36 |
+
self.bias = torch.nn.Parameter(torch.zeros(1, dtype=dtype))
|
| 37 |
+
self.eps = eps
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self,
|
| 41 |
+
x: torch.Tensor,
|
| 42 |
+
mul: torch.Tensor,
|
| 43 |
+
):
|
| 44 |
+
return FusedMulPolyNormFunction.apply(x, mul, self.weight, self.bias,
|
| 45 |
+
self.eps)
|
| 46 |
+
|
| 47 |
+
def reset_parameters(self) -> None:
|
| 48 |
+
"""
|
| 49 |
+
Resets parameters based on their initialization used in __init__.
|
| 50 |
+
"""
|
| 51 |
+
init.ones_(self.weight)
|
| 52 |
+
init.zeros_(self.bias)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
class RMSNorm(nn.Module):
|
| 56 |
|
| 57 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
|
|
| 70 |
Resets parameters based on their initialization used in __init__.
|
| 71 |
"""
|
| 72 |
init.ones_(self.weight)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class FusedAddRMSNorm(nn.Module):
|
| 76 |
+
|
| 77 |
+
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 78 |
+
super().__init__()
|
| 79 |
+
self.weight = torch.nn.Parameter(torch.ones(dim, dtype=dtype))
|
| 80 |
+
self.eps = eps
|
| 81 |
+
|
| 82 |
+
def forward(
|
| 83 |
+
self,
|
| 84 |
+
x: torch.Tensor,
|
| 85 |
+
residual: torch.Tensor,
|
| 86 |
+
):
|
| 87 |
+
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)[0]
|
| 89 |
+
|
| 90 |
+
def reset_parameters(self) -> None:
|
| 91 |
+
"""
|
| 92 |
+
Resets parameters based on their initialization used in __init__.
|
| 93 |
+
"""
|
| 94 |
+
init.ones_(self.weight)
|
build/torch27-cxx11-cu126-x86_64-linux/activation/poly_norm.py
CHANGED
|
@@ -37,3 +37,40 @@ class PolyNormFunction(torch.autograd.Function):
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class FusedMulPolyNormFunction(torch.autograd.Function):
|
| 43 |
+
# Note that forward, setup_context, and backward are @staticmethods
|
| 44 |
+
@staticmethod
|
| 45 |
+
def forward(input, mul, weight, bias, eps):
|
| 46 |
+
output = torch.empty_like(input)
|
| 47 |
+
ops.fused_mul_poly_norm(output, input, mul, weight, bias, eps)
|
| 48 |
+
return output
|
| 49 |
+
|
| 50 |
+
@staticmethod
|
| 51 |
+
# inputs is a Tuple of all of the inputs passed to forward.
|
| 52 |
+
# output is the output of the forward().
|
| 53 |
+
def setup_context(ctx, inputs, output):
|
| 54 |
+
input, mul, weight, bias, eps = inputs
|
| 55 |
+
ctx.save_for_backward(input, mul, weight, bias)
|
| 56 |
+
ctx.eps = eps
|
| 57 |
+
|
| 58 |
+
# This function has only a single output, so it gets only one gradient
|
| 59 |
+
@staticmethod
|
| 60 |
+
def backward(ctx, output_grad):
|
| 61 |
+
input, mul, weight, bias = ctx.saved_tensors
|
| 62 |
+
eps = ctx.eps
|
| 63 |
+
|
| 64 |
+
input_grad = torch.empty_like(
|
| 65 |
+
input) if ctx.needs_input_grad[0] else None
|
| 66 |
+
mul_grad = torch.empty_like(mul) if ctx.needs_input_grad[1] else None
|
| 67 |
+
weight_grad = torch.empty_like(
|
| 68 |
+
weight) if ctx.needs_input_grad[2] else None
|
| 69 |
+
bias_grad = (torch.empty(1, dtype=weight.dtype, device=weight.device)
|
| 70 |
+
if ctx.needs_input_grad[3] else None)
|
| 71 |
+
|
| 72 |
+
ops.fused_mul_poly_norm_backward(input_grad, mul_grad, weight_grad,
|
| 73 |
+
bias_grad, output_grad, input, mul,
|
| 74 |
+
weight, bias, eps)
|
| 75 |
+
|
| 76 |
+
return input_grad, mul_grad, weight_grad, bias_grad, None
|
build/torch27-cxx11-cu126-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -35,3 +35,50 @@ class RMSNormFunction(torch.autograd.Function):
|
|
| 35 |
weight, eps)
|
| 36 |
|
| 37 |
return input_grad, weight_grad, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
weight, eps)
|
| 36 |
|
| 37 |
return input_grad, weight_grad, None
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# Inherit from Function
|
| 41 |
+
class FusedAddRMSNormFunction(torch.autograd.Function):
|
| 42 |
+
# Note that forward, setup_context, and backward are @staticmethods
|
| 43 |
+
@staticmethod
|
| 44 |
+
def forward(input, residual, weight, eps):
|
| 45 |
+
output = torch.empty_like(input)
|
| 46 |
+
add_output = torch.empty_like(input)
|
| 47 |
+
ops.fused_add_rms_norm(output, add_output, input, residual, weight,
|
| 48 |
+
eps)
|
| 49 |
+
return output, add_output
|
| 50 |
+
|
| 51 |
+
@staticmethod
|
| 52 |
+
# inputs is a Tuple of all of the inputs passed to forward.
|
| 53 |
+
# output is the output of the forward().
|
| 54 |
+
def setup_context(ctx, inputs, outputs):
|
| 55 |
+
_, _, weight, eps = inputs
|
| 56 |
+
_, add_output = outputs
|
| 57 |
+
ctx.mark_non_differentiable(add_output)
|
| 58 |
+
ctx.set_materialize_grads(False)
|
| 59 |
+
ctx.save_for_backward(weight, add_output)
|
| 60 |
+
ctx.eps = eps
|
| 61 |
+
|
| 62 |
+
# This function only needs one gradient
|
| 63 |
+
@staticmethod
|
| 64 |
+
def backward(ctx, output_grad, _):
|
| 65 |
+
weight, add_output = ctx.saved_tensors
|
| 66 |
+
eps = ctx.eps
|
| 67 |
+
|
| 68 |
+
if output_grad is None:
|
| 69 |
+
output_grad = torch.zeros_like(add_output)
|
| 70 |
+
|
| 71 |
+
need_in = ctx.needs_input_grad[0]
|
| 72 |
+
need_res = ctx.needs_input_grad[1]
|
| 73 |
+
|
| 74 |
+
grad = torch.empty_like(output_grad) if need_in or need_res else None
|
| 75 |
+
|
| 76 |
+
weight_grad = torch.empty_like(
|
| 77 |
+
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
+
|
| 79 |
+
ops.rms_norm_backward(grad, weight_grad, output_grad, add_output,
|
| 80 |
+
weight, eps)
|
| 81 |
+
input_grad = grad if need_in else None
|
| 82 |
+
residual_grad = grad if need_res else None
|
| 83 |
+
|
| 84 |
+
return input_grad, residual_grad, weight_grad, None
|
build/torch27-cxx11-cu128-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
@@ -15,6 +15,16 @@ def poly_norm(
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
def rms_norm(
|
| 19 |
x: torch.Tensor,
|
| 20 |
weight: torch.Tensor,
|
|
@@ -23,8 +33,20 @@ def rms_norm(
|
|
| 23 |
return RMSNormFunction.apply(x, weight, eps)
|
| 24 |
|
| 25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
__all__ = [
|
| 27 |
"poly_norm",
|
|
|
|
|
|
|
|
|
|
| 28 |
"layers",
|
| 29 |
"ops",
|
| 30 |
]
|
|
|
|
| 2 |
|
| 3 |
from . import layers
|
| 4 |
from ._ops import ops
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
def poly_norm(
|
|
|
|
| 15 |
return PolyNormFunction.apply(x, weight, bias, eps)
|
| 16 |
|
| 17 |
|
| 18 |
+
def fused_mul_poly_norm(
|
| 19 |
+
x: torch.Tensor,
|
| 20 |
+
mul: torch.Tensor,
|
| 21 |
+
weight: torch.Tensor,
|
| 22 |
+
bias: torch.Tensor,
|
| 23 |
+
eps: float = 1e-6,
|
| 24 |
+
) -> None:
|
| 25 |
+
return FusedMulPolyNormFunction.apply(x, mul, weight, bias, eps)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
def rms_norm(
|
| 29 |
x: torch.Tensor,
|
| 30 |
weight: torch.Tensor,
|
|
|
|
| 33 |
return RMSNormFunction.apply(x, weight, eps)
|
| 34 |
|
| 35 |
|
| 36 |
+
def fused_add_rms_norm(
|
| 37 |
+
x: torch.Tensor,
|
| 38 |
+
residual: torch.Tensor,
|
| 39 |
+
weight: torch.Tensor,
|
| 40 |
+
eps: float = 1e-6,
|
| 41 |
+
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)[0]
|
| 43 |
+
|
| 44 |
+
|
| 45 |
__all__ = [
|
| 46 |
"poly_norm",
|
| 47 |
+
"fused_mul_poly_norm",
|
| 48 |
+
"rms_norm",
|
| 49 |
+
"fused_add_rms_norm",
|
| 50 |
"layers",
|
| 51 |
"ops",
|
| 52 |
]
|
build/torch27-cxx11-cu128-x86_64-linux/activation/_activation_20250907180255.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0bf0d2ab5ff5520704e0b0c959b61d0043d360cfd4335950e69677873a87e436
|
| 3 |
+
size 12792112
|
build/torch27-cxx11-cu128-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_20250907180255
|
| 3 |
+
ops = torch.ops._activation_20250907180255
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_20250907180255::{op_name}"
|
build/torch27-cxx11-cu128-x86_64-linux/activation/layers.py
CHANGED
|
@@ -2,8 +2,8 @@ import torch
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
-
from .poly_norm import PolyNormFunction
|
| 6 |
-
from .rms_norm import RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
@@ -28,6 +28,30 @@ class PolyNorm(nn.Module):
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
class RMSNorm(nn.Module):
|
| 32 |
|
| 33 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
@@ -46,3 +70,25 @@ class RMSNorm(nn.Module):
|
|
| 46 |
Resets parameters based on their initialization used in __init__.
|
| 47 |
"""
|
| 48 |
init.ones_(self.weight)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
import torch.nn as nn
|
| 3 |
from torch.nn import init
|
| 4 |
|
| 5 |
+
from .poly_norm import FusedMulPolyNormFunction, PolyNormFunction
|
| 6 |
+
from .rms_norm import FusedAddRMSNormFunction, RMSNormFunction
|
| 7 |
|
| 8 |
|
| 9 |
class PolyNorm(nn.Module):
|
|
|
|
| 28 |
init.zeros_(self.bias)
|
| 29 |
|
| 30 |
|
| 31 |
+
class FusedMulPolyNorm(nn.Module):
|
| 32 |
+
|
| 33 |
+
def __init__(self, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.weight = torch.nn.Parameter(torch.ones(3, dtype=dtype) / 3)
|
| 36 |
+
self.bias = torch.nn.Parameter(torch.zeros(1, dtype=dtype))
|
| 37 |
+
self.eps = eps
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self,
|
| 41 |
+
x: torch.Tensor,
|
| 42 |
+
mul: torch.Tensor,
|
| 43 |
+
):
|
| 44 |
+
return FusedMulPolyNormFunction.apply(x, mul, self.weight, self.bias,
|
| 45 |
+
self.eps)
|
| 46 |
+
|
| 47 |
+
def reset_parameters(self) -> None:
|
| 48 |
+
"""
|
| 49 |
+
Resets parameters based on their initialization used in __init__.
|
| 50 |
+
"""
|
| 51 |
+
init.ones_(self.weight)
|
| 52 |
+
init.zeros_(self.bias)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
class RMSNorm(nn.Module):
|
| 56 |
|
| 57 |
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
|
|
|
| 70 |
Resets parameters based on their initialization used in __init__.
|
| 71 |
"""
|
| 72 |
init.ones_(self.weight)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class FusedAddRMSNorm(nn.Module):
|
| 76 |
+
|
| 77 |
+
def __init__(self, dim: int, eps=1e-6, dtype: torch.dtype = torch.float32):
|
| 78 |
+
super().__init__()
|
| 79 |
+
self.weight = torch.nn.Parameter(torch.ones(dim, dtype=dtype))
|
| 80 |
+
self.eps = eps
|
| 81 |
+
|
| 82 |
+
def forward(
|
| 83 |
+
self,
|
| 84 |
+
x: torch.Tensor,
|
| 85 |
+
residual: torch.Tensor,
|
| 86 |
+
):
|
| 87 |
+
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)[0]
|
| 89 |
+
|
| 90 |
+
def reset_parameters(self) -> None:
|
| 91 |
+
"""
|
| 92 |
+
Resets parameters based on their initialization used in __init__.
|
| 93 |
+
"""
|
| 94 |
+
init.ones_(self.weight)
|
build/torch27-cxx11-cu128-x86_64-linux/activation/poly_norm.py
CHANGED
|
@@ -37,3 +37,40 @@ class PolyNormFunction(torch.autograd.Function):
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
input, weight, eps)
|
| 38 |
|
| 39 |
return input_grad, weight_grad, bias_grad, None
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class FusedMulPolyNormFunction(torch.autograd.Function):
|
| 43 |
+
# Note that forward, setup_context, and backward are @staticmethods
|
| 44 |
+
@staticmethod
|
| 45 |
+
def forward(input, mul, weight, bias, eps):
|
| 46 |
+
output = torch.empty_like(input)
|
| 47 |
+
ops.fused_mul_poly_norm(output, input, mul, weight, bias, eps)
|
| 48 |
+
return output
|
| 49 |
+
|
| 50 |
+
@staticmethod
|
| 51 |
+
# inputs is a Tuple of all of the inputs passed to forward.
|
| 52 |
+
# output is the output of the forward().
|
| 53 |
+
def setup_context(ctx, inputs, output):
|
| 54 |
+
input, mul, weight, bias, eps = inputs
|
| 55 |
+
ctx.save_for_backward(input, mul, weight, bias)
|
| 56 |
+
ctx.eps = eps
|
| 57 |
+
|
| 58 |
+
# This function has only a single output, so it gets only one gradient
|
| 59 |
+
@staticmethod
|
| 60 |
+
def backward(ctx, output_grad):
|
| 61 |
+
input, mul, weight, bias = ctx.saved_tensors
|
| 62 |
+
eps = ctx.eps
|
| 63 |
+
|
| 64 |
+
input_grad = torch.empty_like(
|
| 65 |
+
input) if ctx.needs_input_grad[0] else None
|
| 66 |
+
mul_grad = torch.empty_like(mul) if ctx.needs_input_grad[1] else None
|
| 67 |
+
weight_grad = torch.empty_like(
|
| 68 |
+
weight) if ctx.needs_input_grad[2] else None
|
| 69 |
+
bias_grad = (torch.empty(1, dtype=weight.dtype, device=weight.device)
|
| 70 |
+
if ctx.needs_input_grad[3] else None)
|
| 71 |
+
|
| 72 |
+
ops.fused_mul_poly_norm_backward(input_grad, mul_grad, weight_grad,
|
| 73 |
+
bias_grad, output_grad, input, mul,
|
| 74 |
+
weight, bias, eps)
|
| 75 |
+
|
| 76 |
+
return input_grad, mul_grad, weight_grad, bias_grad, None
|