
Upload 5 files
Browse files- README-en.md +262 -0
- static/attributes.jpg +3 -0
- static/pipeline.jpg +3 -0
- static/topic_distribution.jpg +3 -0
- static/topic_visualization.jpg +3 -0
README-en.md
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align="center">
|
| 2 |
+
📷 CAMS: A Large-Scale, Multi-faceted, Attribute-based Chinese Summarization Dataset
|
| 3 |
+
</h1>
|
| 4 |
+
<p align="center">
|
| 5 |
+
<a href="https://github.com/Mxoder/Maxs-Awesome-Datasets" target="_blank">💻 Github Repo</a> <br>
|
| 6 |
+
<a href="https://huggingface.co/datasets/Mxode/CAMS" target="_blank">简体中文</a> | English <br>
|
| 7 |
+
</p>
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
## Introduction
|
| 13 |
+
|
| 14 |
+
CAMS (**C**hinese **A**ttribute-based **M**ulti-faceted **S**ummarization) is a large-scale Chinese summarization dataset designed to advance research in long-document summarization. With the rapid development of Large Language Models (LLMs), high-quality, large-scale training data has become crucial, especially for non-English languages. CAMS aims to fill the gap in the field of Chinese long-text summarization.
|
| 15 |
+
|
| 16 |
+
The dataset contains **1 million** high-quality, long Chinese articles. Each article is paired with three summaries of different granularities and a rich set of attribute labels.
|
| 17 |
+
|
| 18 |
+
### Key Features
|
| 19 |
+
|
| 20 |
+
- **Focus on Long Documents**: The articles in the dataset have an average length of over 1,500 characters, providing a challenging platform for training and evaluating long-text summarization models.
|
| 21 |
+
- **Multi-Level Summaries**: Each article comes with three hierarchically structured summaries:
|
| 22 |
+
- **Long Summary**: A detailed and comprehensive summary covering the key information of the original text.
|
| 23 |
+
- **Medium Summary**: A concise overview of the article's core points.
|
| 24 |
+
- **Short Summary**: A one-sentence summary of the article's central idea.
|
| 25 |
+
- **Rich Attribute Annotations**: Each article has been annotated with multi-dimensional attributes, including:
|
| 26 |
+
- **Keywords**
|
| 27 |
+
- **Statement Type**: Factual Statement vs. Opinion Expression
|
| 28 |
+
- **Sentiment**: Positive, Somewhat Positive, Neutral, Somewhat Negative, Negative
|
| 29 |
+
- **Formality**: Formal vs. Colloquial
|
| 30 |
+
- **Tense**: Past, Present, Future
|
| 31 |
+
|
| 32 |
+
We hope the CAMS dataset will foster research and innovation in areas such as controllable summarization, attribute-aware generation, and long-text understanding.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## 📊 Data Statistics
|
| 39 |
+
|
| 40 |
+
### Basic Information
|
| 41 |
+
|
| 42 |
+
To better illustrate the basic statistics of CAMS, we compare it with other mainstream Chinese and English summarization datasets.
|
| 43 |
+
|
| 44 |
+
<table>
|
| 45 |
+
<thead>
|
| 46 |
+
<tr>
|
| 47 |
+
<th style="text-align: left;"><strong>Dataset</strong></th>
|
| 48 |
+
<th style="text-align: left;"><strong>Size</strong></th>
|
| 49 |
+
<th style="text-align: left;"><strong>Avg. Doc Length</strong></th>
|
| 50 |
+
<th style="text-align: left;"><strong>Avg. Summary Length</strong></th>
|
| 51 |
+
<th style="text-align: left;"><strong>Avg. #Keywords</strong></th>
|
| 52 |
+
</tr>
|
| 53 |
+
</thead>
|
| 54 |
+
<tbody>
|
| 55 |
+
<tr>
|
| 56 |
+
<td colspan="5" style="text-align: center;"><strong>English</strong></td>
|
| 57 |
+
</tr>
|
| 58 |
+
<tr>
|
| 59 |
+
<td style="text-align: left;">NYT</td>
|
| 60 |
+
<td style="text-align: left;">655K</td>
|
| 61 |
+
<td style="text-align: left;">552.1</td>
|
| 62 |
+
<td style="text-align: left;">42.8</td>
|
| 63 |
+
<td style="text-align: left;">-</td>
|
| 64 |
+
</tr>
|
| 65 |
+
<tr>
|
| 66 |
+
<td style="text-align: left;">CNNDM</td>
|
| 67 |
+
<td style="text-align: left;">312K</td>
|
| 68 |
+
<td style="text-align: left;">791.7</td>
|
| 69 |
+
<td style="text-align: left;">55.2</td>
|
| 70 |
+
<td style="text-align: left;">-</td>
|
| 71 |
+
</tr>
|
| 72 |
+
<tr>
|
| 73 |
+
<td style="text-align: left;">Newsroom</td>
|
| 74 |
+
<td style="text-align: left;">1.0M</td>
|
| 75 |
+
<td style="text-align: left;">765.6</td>
|
| 76 |
+
<td style="text-align: left;">30.2</td>
|
| 77 |
+
<td style="text-align: left;">-</td>
|
| 78 |
+
</tr>
|
| 79 |
+
<tr>
|
| 80 |
+
<td colspan="5" style="text-align: center;"><strong>Chinese</strong></td>
|
| 81 |
+
</tr>
|
| 82 |
+
<tr>
|
| 83 |
+
<td style="text-align: left;">LCSTS</td>
|
| 84 |
+
<td style="text-align: left;">2.4M</td>
|
| 85 |
+
<td style="text-align: left;">103.7</td>
|
| 86 |
+
<td style="text-align: left;">17.9</td>
|
| 87 |
+
<td style="text-align: left;">-</td>
|
| 88 |
+
</tr>
|
| 89 |
+
<tr>
|
| 90 |
+
<td style="text-align: left;">CLTS</td>
|
| 91 |
+
<td style="text-align: left;">185K</td>
|
| 92 |
+
<td style="text-align: left;">1363.7</td>
|
| 93 |
+
<td style="text-align: left;">58.1</td>
|
| 94 |
+
<td style="text-align: left;">-</td>
|
| 95 |
+
</tr>
|
| 96 |
+
<tr>
|
| 97 |
+
<td style="text-align: left;">CNewSum</td>
|
| 98 |
+
<td style="text-align: left;">396K</td>
|
| 99 |
+
<td style="text-align: left;">730.4</td>
|
| 100 |
+
<td style="text-align: left;">35.1</td>
|
| 101 |
+
<td style="text-align: left;">-</td>
|
| 102 |
+
</tr>
|
| 103 |
+
<tr>
|
| 104 |
+
<td style="text-align: left;">CSL</td>
|
| 105 |
+
<td style="text-align: left;">396K</td>
|
| 106 |
+
<td style="text-align: left;">206.0</td>
|
| 107 |
+
<td style="text-align: left;">19.0</td>
|
| 108 |
+
<td style="text-align: left;">5.1</td>
|
| 109 |
+
</tr>
|
| 110 |
+
<tr>
|
| 111 |
+
<td style="text-align: left;"><strong>CAMS</strong></td>
|
| 112 |
+
<td style="text-align: left;"><strong>1.0M</strong></td>
|
| 113 |
+
<td style="text-align: left;"><strong>1571.4</strong></td>
|
| 114 |
+
<td style="text-align: left;"><strong>60.0 (S)</strong> <br><strong>185.7 (M)</strong> <br><strong>428.1 (L)</strong></td>
|
| 115 |
+
<td style="text-align: left;"><strong>14.3</strong></td>
|
| 116 |
+
</tr>
|
| 117 |
+
</tbody>
|
| 118 |
+
</table>
|
| 119 |
+
|
| 120 |
+
### Topic Distribution
|
| 121 |
+
|
| 122 |
+
CAMS covers 30 distinct topics, where the `key` is the field name in the dataset and the `value` is the topic content:
|
| 123 |
+
|
| 124 |
+
```json
|
| 125 |
+
{
|
| 126 |
+
"other_manufacturing": "Other Manufacturing",
|
| 127 |
+
"automobile": "Automobile",
|
| 128 |
+
"biomedicine": "Biomedicine",
|
| 129 |
+
"computer_communication": "Computer Communication",
|
| 130 |
+
"subject_education_education": "Education",
|
| 131 |
+
"finance_economics": "Finance & Economics",
|
| 132 |
+
"transportation": "Transportation",
|
| 133 |
+
"literature_emotion": "Literature & Emotion",
|
| 134 |
+
"water_resources_ocean": "Water Resources",
|
| 135 |
+
"aerospace": "Aerospace",
|
| 136 |
+
"technology_scientific_research": "Scientific Research",
|
| 137 |
+
"electric_power_energy": "Energy & Power",
|
| 138 |
+
"mining": "Mining",
|
| 139 |
+
"petrochemical": "Petrochemical",
|
| 140 |
+
"law_judiciary": "Law & Judiciary",
|
| 141 |
+
"accommodation_catering_hotel": "Hospitality",
|
| 142 |
+
"film_entertainment": "Film & Entertainment",
|
| 143 |
+
"agriculture_forestry_animal_husbandry_fishery": "Agriculture & Fishery",
|
| 144 |
+
"current_affairs_government_administration": "Government & Public Affairs",
|
| 145 |
+
"news_media": "News & Media",
|
| 146 |
+
"artificial_intelligence_machine_learning": "AI & Machine Learning",
|
| 147 |
+
"computer_programming_code": "Software Development",
|
| 148 |
+
"sports": "Sports",
|
| 149 |
+
"fire_safety_food_safety": "Food & Fire Safety",
|
| 150 |
+
"mathematics_statistics": "Math & Statistics",
|
| 151 |
+
"medicine_health_psychology_traditional_chinese_medicine": "Medicine & Health",
|
| 152 |
+
"game": "Gaming",
|
| 153 |
+
"other_information_services_information_security": "Information Security",
|
| 154 |
+
"real_estate_construction": "Real Estate & Construction",
|
| 155 |
+
"tourism_geography": "Tourism & Geography"
|
| 156 |
+
}
|
| 157 |
+
````
|
| 158 |
+
|
| 159 |
+
The topic distribution of the samples is as follows:
|
| 160 |
+
|
| 161 |
+

|
| 162 |
+
|
| 163 |
+
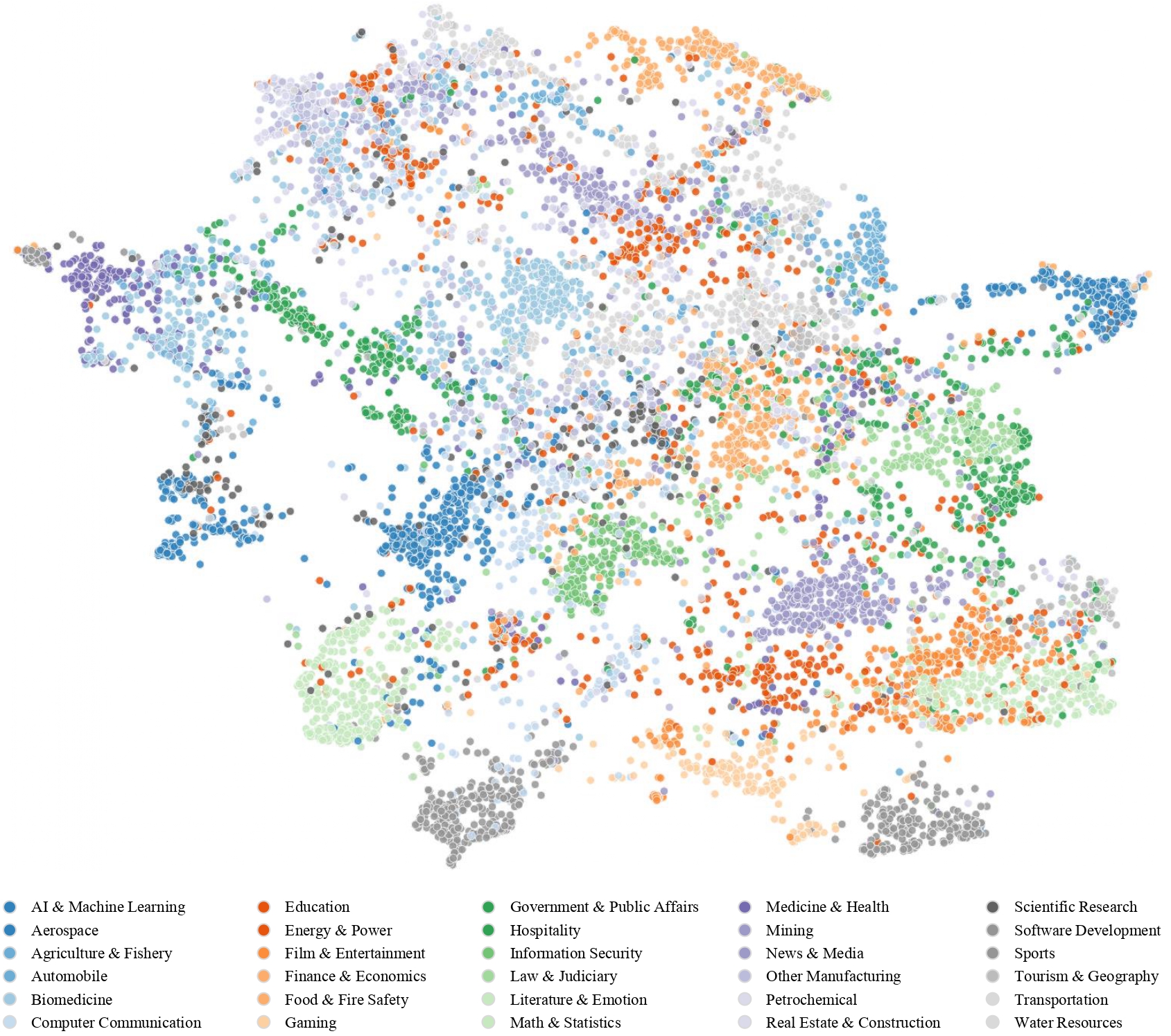
We also extracted a subset of samples, obtained their text embeddings, and visualized the topic distribution using UMAP for dimensionality reduction:
|
| 164 |
+
|
| 165 |
+

|
| 166 |
+
|
| 167 |
+
### Attribute Annotation
|
| 168 |
+
|
| 169 |
+
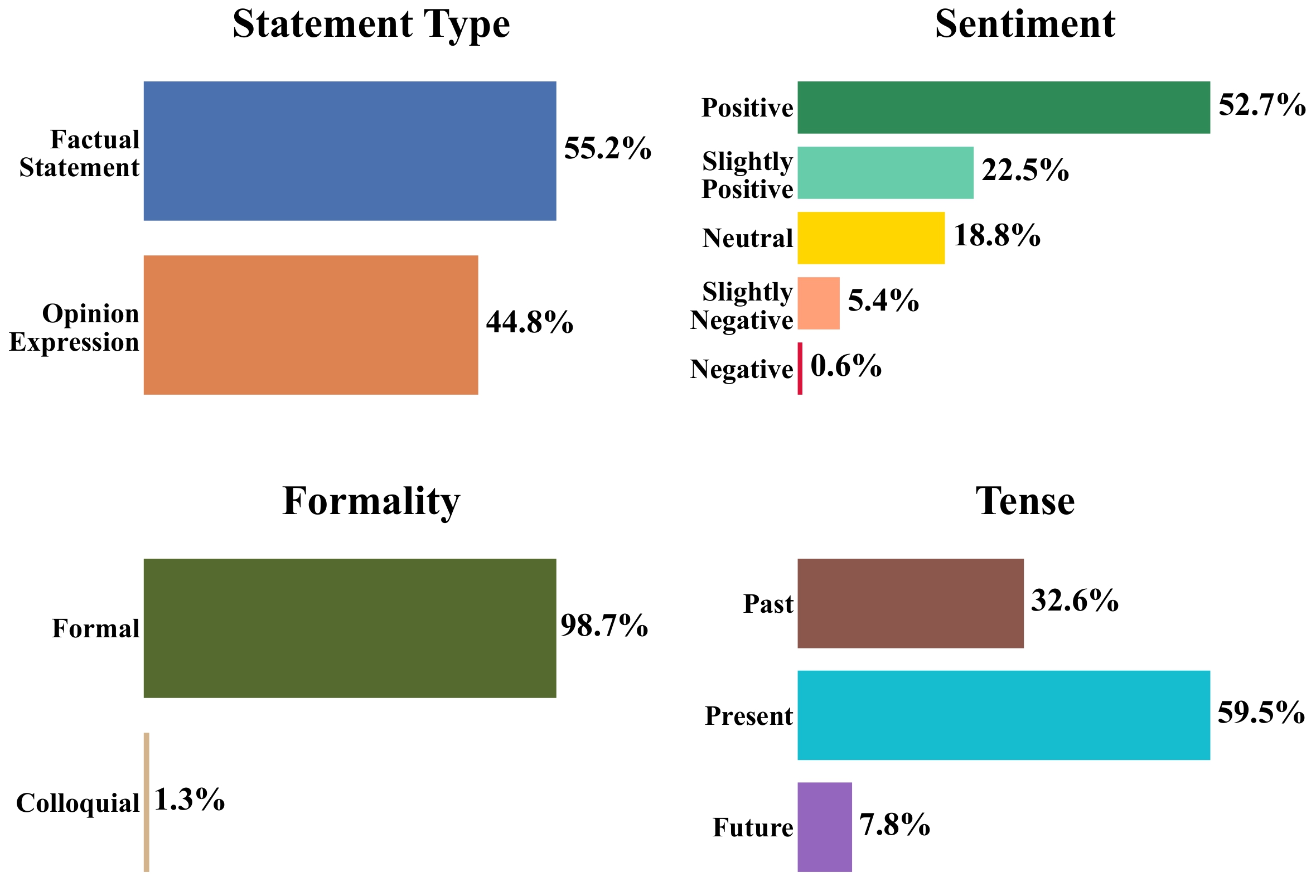
The distribution of the four additional attribute annotations is shown below:
|
| 170 |
+
|
| 171 |
+

|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
## 📂 Data Format
|
| 178 |
+
|
| 179 |
+
Each sample in the dataset is stored in JSON format and contains the following fields:
|
| 180 |
+
|
| 181 |
+
```json
|
| 182 |
+
{
|
| 183 |
+
"id": "A unique identifier for each data entry",
|
| 184 |
+
"text": "The original content of the article",
|
| 185 |
+
"topic": "The topic of the article",
|
| 186 |
+
"short_summary": "A one-sentence short summary",
|
| 187 |
+
"medium_summary": "A medium-length summary",
|
| 188 |
+
"long_summary": "A detailed long summary",
|
| 189 |
+
"keywords": ["Keyword1", "Keyword2", "Keyword3", "..."],
|
| 190 |
+
"statement_type": "The type of statement (e.g., factual vs. opinion)",
|
| 191 |
+
"sentiment": "The sentiment of the article or the author's stance",
|
| 192 |
+
"formality": "The formality of the article's writing style",
|
| 193 |
+
"tense": "The tense of the article",
|
| 194 |
+
}
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
## 🛠️ Dataset Construction
|
| 202 |
+
|
| 203 |
+
The construction of CAMS was divided into three main stages:
|
| 204 |
+
|
| 205 |
+
1. **Data Source and Preprocessing**: We started with approximately 10 million articles from a large-scale, high-quality corpus, [IndustryCorpus2](https://huggingface.co/datasets/BAAI/IndustryCorpus2), as our initial candidate set. After rigorous quality filtering, heuristic-based filtering, and topic-balanced resampling, we curated a final set of 1 million high-quality, topically diverse articles.
|
| 206 |
+
|
| 207 |
+
2. **Multi-Level Summary Generation**: We proposed a **Stepwise Generation** pipeline. This process first generates a detailed long summary from the original article. Then, it uses both the original article and the long summary as context to generate the medium summary. Finally, it combines the article, long summary, and medium summary to produce the most concise short summary. This method ensures consistency and coherence across the different levels of summaries.
|
| 208 |
+
|
| 209 |
+
<img src="static/pipeline.jpg" alt="Stepwise Generation Pipeline" style="zoom:50%;" />
|
| 210 |
+
|
| 211 |
+
3. **Multi-faceted Attribute Annotation**: For each article, we performed keyword extraction and annotated multiple linguistic and stylistic attributes. We employed a multi-round generation and voting mechanism to ensure the accuracy of these annotations.
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
## 🚀 Usage Example
|
| 218 |
+
|
| 219 |
+
You can easily load the CAMS dataset using the 🤗 `datasets` library.
|
| 220 |
+
|
| 221 |
+
```python
|
| 222 |
+
from datasets import load_dataset
|
| 223 |
+
|
| 224 |
+
# Load the CAMS dataset
|
| 225 |
+
dataset = load_dataset("Mxode/CAMS")
|
| 226 |
+
|
| 227 |
+
# Inspect the dataset structure
|
| 228 |
+
print(dataset)
|
| 229 |
+
|
| 230 |
+
# Access the first sample
|
| 231 |
+
sample = dataset["train"][0]
|
| 232 |
+
print("Article:", sample["text"][:200])
|
| 233 |
+
print("Short Summary:", sample["short_summary"])
|
| 234 |
+
print("Keywords:", sample["keywords"])
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
## 📜 Citation
|
| 242 |
+
|
| 243 |
+
If you use the CAMS dataset in your research, please cite our work:
|
| 244 |
+
|
| 245 |
+
```bibtex
|
| 246 |
+
@misc{zhang2025CAMS,
|
| 247 |
+
title={CAMS: A Large-Scale Chinese Attribute-based Multi-faceted Summarization Dataset},
|
| 248 |
+
url={https://huggingface.co/datasets/Mxode/CAMS},
|
| 249 |
+
author={Xiantao Zhang},
|
| 250 |
+
month={August},
|
| 251 |
+
year={2025}
|
| 252 |
+
}
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
## 📄 License
|
| 260 |
+
|
| 261 |
+
This dataset is licensed under the **CC BY-SA 4.0** license.
|
| 262 |
+
|
static/attributes.jpg
ADDED
|
Git LFS Details
|
static/pipeline.jpg
ADDED

|
Git LFS Details
|
static/topic_distribution.jpg
ADDED

|
Git LFS Details
|
static/topic_visualization.jpg
ADDED
|
Git LFS Details
|