---
license: apache-2.0
---
LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance
[](https://arxiv.org/abs/2507.06272)
[](https://huggingface.co/echo840/LIRA)
[](https://github.com/echo840/LIRA/issues?q=is%3Aopen+is%3Aissue)
[](https://github.com/echo840/LIRA/issues?q=is%3Aissue+is%3Aclosed)
[](https://github.com/echo840/LIRA)
> **LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance**
> Zhang Li, Biao Yang, Qiang Liu, Shuo Zhang, Zhiyin Ma, Liang Yin, Linger Deng, Yabo Sun, Yuliang Liu, Xiang Bai
[](https://arxiv.org/abs/2507.06272)
[](https://github.com/echo840/LIRA/edit/main/README.md)
[](https://huggingface.co/echo840/LIRA)
## Abstract
While large multi-modal models (LMMs) demonstrate promising capabilities in segmentation and comprehension, they still struggle with two limitations: inaccurate segmentation and hallucinated comprehension. These challenges stem primarily from constraints in weak visual comprehension and a lack of fine-grained perception. To alleviate these limitations, we propose LIRA, a framework that capitalizes on the complementary relationship between visual comprehension and segmentation via two key components: (1) Semantic-Enhanced Feature Extractor (SEFE) improves object attribute inference by fusing semantic and pixel-level features, leading to more accurate segmentation; (2) Interleaved Local Visual Coupling (ILVC) autoregressively generates local descriptions after extracting local features based on segmentation masks, offering fine-grained supervision to mitigate hallucinations. Furthermore, we find that the precision of object segmentation is positively correlated with the latent related semantics of the token. To quantify this relationship and the model's potential semantic inferring ability, we introduce the Attributes Evaluation (AttrEval) dataset. Our experiments show that LIRA achieves state-of-the-art performance in both segmentation and comprehension tasks.
## Overview
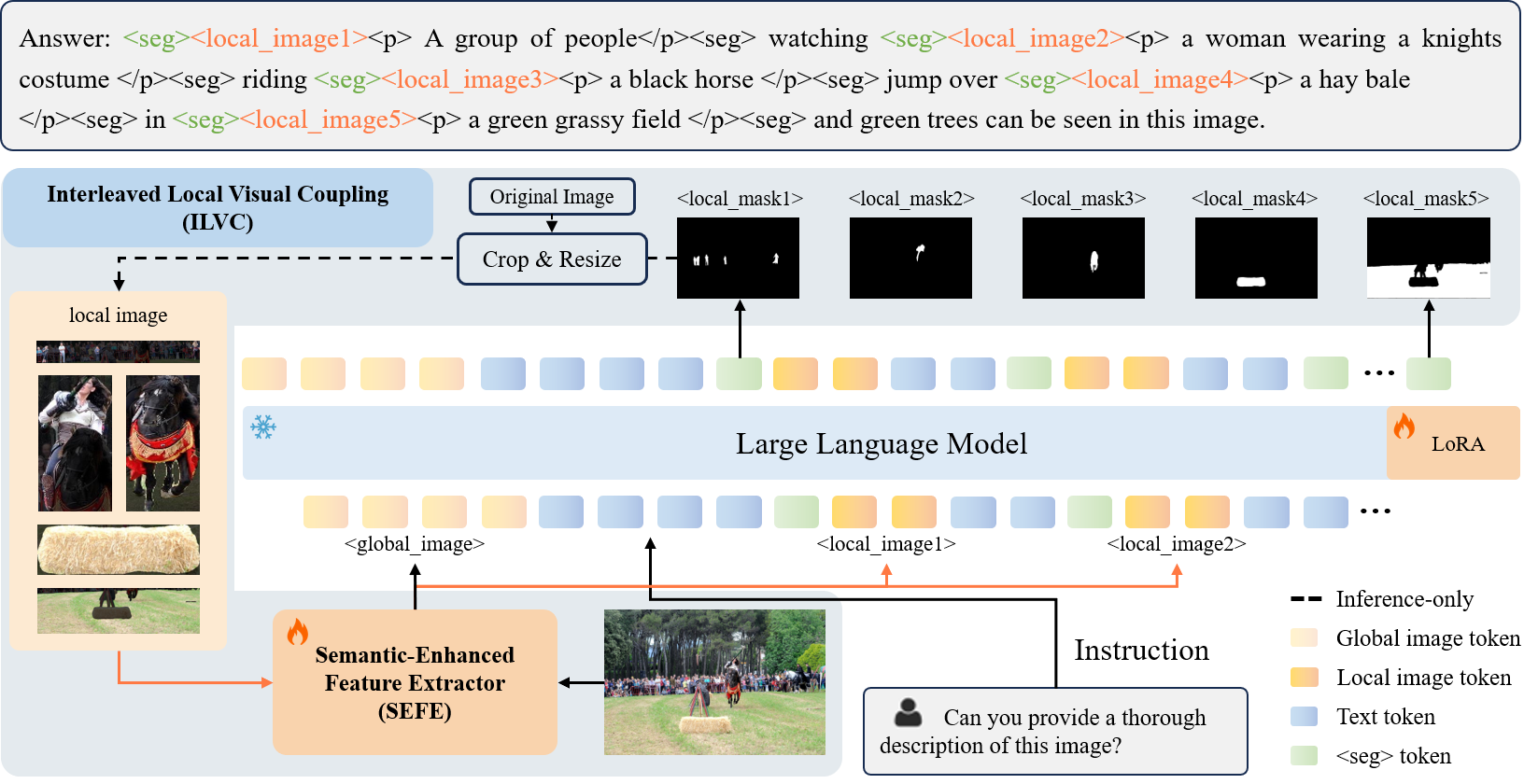 ## Results
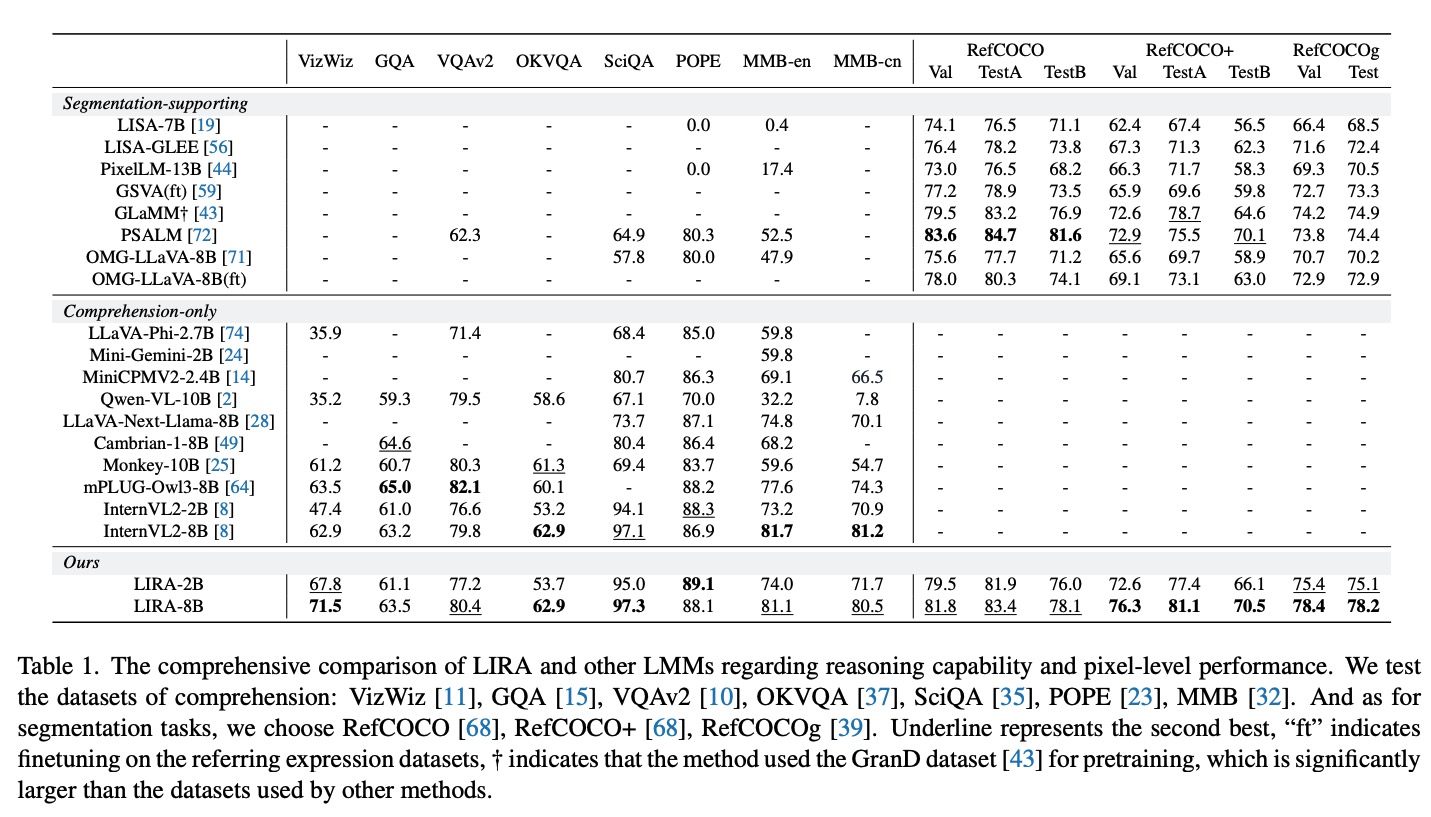
## Results
 ## Weights
1. Download model
```python
python download_model.py -n echo840/LIRA
```
2. Download InternVL
```python
python download_model.py -n OpenGVLab/InternVL2-2B # OpenGVLab/InternVL2-8B
```
## Demo
```python
python ./omg_llava/tools/app_lira.py ./omg_llava/configs/finetune/LIRA-2B.py ./model_weight/LIRA-2B.pth
```
## Train
1. Pretrain
```python
bash ./scripts/pretrain.sh
```
2. After train, please use the tools to convert deepspeed chekpoint to pth format
```python
python omg_llava/tools/convert_deepspeed2pth.py
${PATH_TO_CONFIG} \
${PATH_TO_DeepSpeed_PTH} \
--save-path ./pretrained/${PTH_NAME.pth}
```
3. Finetune
```python
bash ./scripts/finetune.sh
```
## Evaluation
```python
bash ./scripts/eval_gcg.sh # Evaluation on Grounded Conversation Generation Tasks.
bash ./scripts/eval_refseg.sh # Evaluation on Referring Segmentation Tasks.
bash ./scripts/eval_vqa.sh # Evaluation on Comprehension Tasks.
```
## Acknowledgments
Our code is built upon [OMGLLaVA](https://github.com/lxtGH/OMG-Seg) and [InternVL2](https://github.com/OpenGVLab/InternVL), and we sincerely thank them for providing the code and base models. We also thank [OPERA](https://github.com/shikiw/OPERA) for providing the evaluation code for chair.
## Citation
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
```BibTeX
@misc{li2025lirainferringsegmentationlarge,
title={LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance},
author={Zhang Li and Biao Yang and Qiang Liu and Shuo Zhang and Zhiyin Ma and Liang Yin and Linger Deng and Yabo Sun and Yuliang Liu and Xiang Bai},
year={2025},
eprint={2507.06272},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.06272},
}
```
## Weights
1. Download model
```python
python download_model.py -n echo840/LIRA
```
2. Download InternVL
```python
python download_model.py -n OpenGVLab/InternVL2-2B # OpenGVLab/InternVL2-8B
```
## Demo
```python
python ./omg_llava/tools/app_lira.py ./omg_llava/configs/finetune/LIRA-2B.py ./model_weight/LIRA-2B.pth
```
## Train
1. Pretrain
```python
bash ./scripts/pretrain.sh
```
2. After train, please use the tools to convert deepspeed chekpoint to pth format
```python
python omg_llava/tools/convert_deepspeed2pth.py
${PATH_TO_CONFIG} \
${PATH_TO_DeepSpeed_PTH} \
--save-path ./pretrained/${PTH_NAME.pth}
```
3. Finetune
```python
bash ./scripts/finetune.sh
```
## Evaluation
```python
bash ./scripts/eval_gcg.sh # Evaluation on Grounded Conversation Generation Tasks.
bash ./scripts/eval_refseg.sh # Evaluation on Referring Segmentation Tasks.
bash ./scripts/eval_vqa.sh # Evaluation on Comprehension Tasks.
```
## Acknowledgments
Our code is built upon [OMGLLaVA](https://github.com/lxtGH/OMG-Seg) and [InternVL2](https://github.com/OpenGVLab/InternVL), and we sincerely thank them for providing the code and base models. We also thank [OPERA](https://github.com/shikiw/OPERA) for providing the evaluation code for chair.
## Citation
If you wish to refer to the baseline results published here, please use the following BibTeX entries:
```BibTeX
@misc{li2025lirainferringsegmentationlarge,
title={LIRA: Inferring Segmentation in Large Multi-modal Models with Local Interleaved Region Assistance},
author={Zhang Li and Biao Yang and Qiang Liu and Shuo Zhang and Zhiyin Ma and Liang Yin and Linger Deng and Yabo Sun and Yuliang Liu and Xiang Bai},
year={2025},
eprint={2507.06272},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.06272},
}
```