---
license: apache-2.0
---
### Model Card
| Property | Value |
|----------|-------|
| **Model Type** | Vision Transformer (ViT) |
| **Architecture** | HEVC-Style Vision Transformer |
| **Hidden Size** | 1024 |
| **Intermediate Size** | 4096 |
| **Number of Layers** | 24 |
| **Number of Attention Heads** | 16 |
| **Patch Size** | 16 |
| **Image Resolution** | 448×448 (pre-trained) |
| **Video Resolution** | 224×224 with 256 tokens per frame |
| **Positional Encoding** | 3D RoPE (4:6:6 split for T:H:W) |
| **Normalization** | Layer Normalization |
| **Activation Function** | GELU |
| **License** | Apache 2.0 |
### Key Features
- **Codec-Style Patch Selection**: Instead of sampling sparse frames densely (all patches from few frames), OneVision Encoder samples dense frames sparsely (important patches from many frames).
- **3D Rotary Position Embedding**: Uses a 4:6:6 split for temporal, height, and width dimensions to capture spatiotemporal relationships.
- **Native Resolution Support**: Supports native resolution input without tiling or cropping.
- **Flash Attention 2**: Efficient attention implementation for improved performance and memory efficiency.
### Intended Use
#### Primary Use Cases
- **Video Understanding**: Action recognition, video captioning, video question answering
- **Image Understanding**: Document understanding (DocVQA), chart understanding (ChartQA), OCR tasks
- **Vision-Language Models**: As the vision encoder backbone for multimodal large language models
#### Downstream Tasks
- Video benchmarks: MVBench, VideoMME, Perception Test
- Image understanding: DocVQA, ChartQA, OCRBench
- Action recognition: SSv2, UCF101, Kinetics
### Quick Start
> [!IMPORTANT]
> **Transformers Version Compatibility:**
> - ✅ **`transformers==4.53.1`** (Recommended): Works with `AutoModel.from_pretrained()`
> - ⚠️ **`transformers>=5.0.0`**: Not currently supported. We are actively working on a fix.
> **Note:** This model supports native resolution input. For optimal performance:
> - **Image**: 448×448 resolution (pre-trained)
> - **Video**: 224×224 resolution with 256 tokens per frame (pre-trained)
```python
from transformers import AutoModel, AutoImageProcessor
from PIL import Image
import torch
# Load model and preprocessor
model = AutoModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large",
trust_remote_code=True
)
# Image inference: [B, C, H, W]
image = Image.open("path/to/your/image.jpg") # Replace with your image path
pixel_values = preprocessor(images=image, return_tensors="pt")["pixel_values"].to("cuda")
with torch.no_grad():
outputs = model(pixel_values)
# outputs.last_hidden_state: [B, num_patches, hidden_size]
# outputs.pooler_output: [B, hidden_size]
# Video inference: [B, C, T, H, W] with visible_indices
num_frames, frame_tokens, target_frames = 16, 256, 64
# Load video frames and preprocess each frame (replace with your video frame paths)
frames = [Image.open(f"path/to/frame_{i}.jpg") for i in range(num_frames)]
video_pixel_values = preprocessor(images=frames, return_tensors="pt")["pixel_values"]
# Reshape from [T, C, H, W] to [B, C, T, H, W]
video = video_pixel_values.unsqueeze(0).permute(0, 2, 1, 3, 4).to("cuda")
# Build visible_indices for temporal sampling
frame_pos = torch.linspace(0, target_frames - 1, num_frames).long().cuda()
visible_indices = (frame_pos.unsqueeze(-1) * frame_tokens + torch.arange(frame_tokens).cuda()).reshape(1, -1)
# visible_indices example (with 256 tokens per frame):
# Frame 0 (pos=0): indices [0, 1, 2, ..., 255]
# Frame 1 (pos=4): indices [1024, 1025, 1026, ..., 1279]
# Frame 2 (pos=8): indices [2048, 2049, 2050, ..., 2303]
# ...
# Frame 15 (pos=63): indices [16128, 16129, ..., 16383]
with torch.no_grad():
outputs = model(video, visible_indices=visible_indices)
```
### Loading from Source Code
```bash
git clone https://github.com/EvolvingLMMs-Lab/OneVision-Encoder.git
cd OneVision-Encoder
pip install -e .
```
```python
from onevision_encoder import OneVisionEncoderModel, OneVisionEncoderConfig
from transformers import AutoImageProcessor
model = OneVisionEncoderModel.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large",
trust_remote_code=True,
attn_implementation="flash_attention_2"
).to("cuda").eval()
preprocessor = AutoImageProcessor.from_pretrained(
"lmms-lab-encoder/onevision-encoder-large",
trust_remote_code=True
)
```
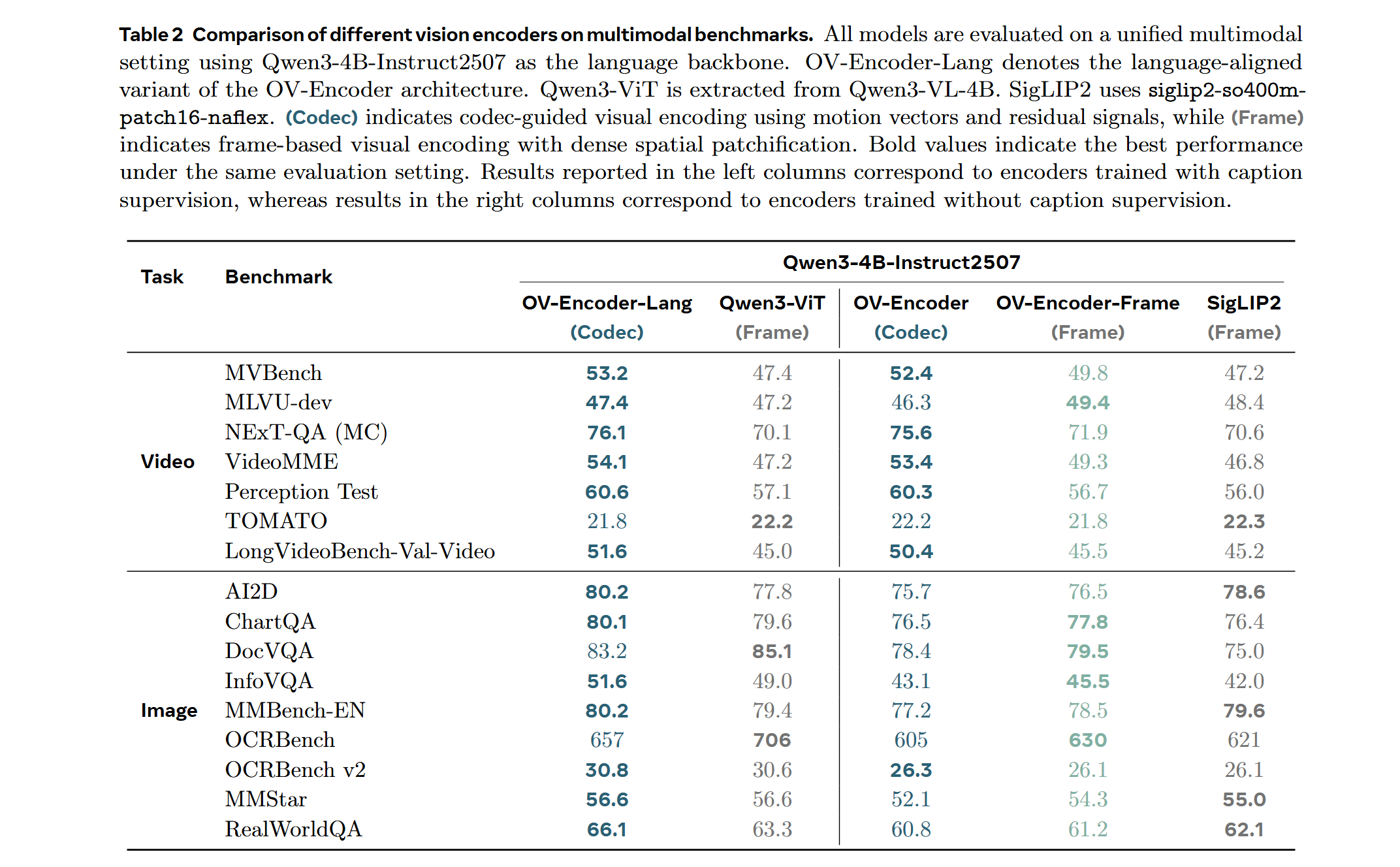
### LMM Probe Results
Training on a mixed dataset of 740K samples from LLaVA-OneVision and 800K samples from LLaVA-Video SFT. The training pipeline proceeds directly to Stage 2 fine-tuning. We adopt a streamlined native-resolution strategy inspired by LLaVA-OneVision: when the input frame resolution matches the model's native input size, it is fed directly—without tiling or cropping—to evaluate the ViT's native resolution capability.
### Attentive Probe Results
Performance comparison of different vision encoders using Attentive Probe evaluation. Models are evaluated using single clip input and trained for 10 epochs across 8 action recognition datasets. Results show average performance and per-dataset scores for 8-frame and 16-frame configurations.