Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- .gitattributes +11 -0
- .gitignore +162 -0
- README.md +46 -12
- app_ctrlx.py +412 -0
- assets/images/bear_avocado__spatext.jpg +0 -0
- assets/images/bedroom__sketch.jpg +0 -0
- assets/images/cat__mesh.jpg +0 -0
- assets/images/cat__point_cloud.jpg +0 -0
- assets/images/dog__sketch.jpg +0 -0
- assets/images/fruit_bowl.jpg +0 -0
- assets/images/grapes.jpg +0 -0
- assets/images/horse.jpg +0 -0
- assets/images/horse__point_cloud.jpg +0 -0
- assets/images/knight__humanoid.jpg +0 -0
- assets/images/library__mesh.jpg +0 -0
- assets/images/living_room__seg.jpg +0 -0
- assets/images/living_room_modern.jpg +0 -0
- assets/images/man_park.jpg +0 -0
- assets/images/person__mesh.jpg +0 -0
- assets/images/running__pose.jpg +0 -0
- assets/images/squirrel.jpg +0 -0
- assets/images/tiger.jpg +0 -0
- assets/images/van_gogh.jpg +0 -0
- ctrl_x/__init__.py +0 -0
- ctrl_x/pipelines/__init__.py +0 -0
- ctrl_x/pipelines/pipeline_sdxl.py +665 -0
- ctrl_x/utils/__init__.py +3 -0
- ctrl_x/utils/feature.py +79 -0
- ctrl_x/utils/media.py +21 -0
- ctrl_x/utils/sdxl.py +274 -0
- ctrl_x/utils/utils.py +88 -0
- docs/assets/bootstrap.min.css +0 -0
- docs/assets/cross_image_attention.jpg +3 -0
- docs/assets/ctrl-x.jpg +3 -0
- docs/assets/font.css +37 -0
- docs/assets/freecontrol.jpg +3 -0
- docs/assets/genforce.png +0 -0
- docs/assets/pipeline.jpg +3 -0
- docs/assets/results_animatediff.mp4 +3 -0
- docs/assets/results_multi_subject.jpg +3 -0
- docs/assets/results_struct+app.jpg +3 -0
- docs/assets/results_struct+app_2.jpg +3 -0
- docs/assets/results_struct+prompt.jpg +3 -0
- docs/assets/style.css +139 -0
- docs/assets/teaser_github.jpg +3 -0
- docs/assets/teaser_small.jpg +3 -0
- docs/index.html +186 -0
- environment.yaml +125 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,14 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
docs/assets/cross_image_attention.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
docs/assets/ctrl-x.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
docs/assets/freecontrol.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
docs/assets/pipeline.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
docs/assets/results_animatediff.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
docs/assets/results_multi_subject.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
docs/assets/results_struct+app.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
docs/assets/results_struct+app_2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
docs/assets/results_struct+prompt.jpg filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
docs/assets/teaser_github.jpg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
docs/assets/teaser_small.jpg filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 110 |
+
.pdm.toml
|
| 111 |
+
.pdm-python
|
| 112 |
+
.pdm-build/
|
| 113 |
+
|
| 114 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 115 |
+
__pypackages__/
|
| 116 |
+
|
| 117 |
+
# Celery stuff
|
| 118 |
+
celerybeat-schedule
|
| 119 |
+
celerybeat.pid
|
| 120 |
+
|
| 121 |
+
# SageMath parsed files
|
| 122 |
+
*.sage.py
|
| 123 |
+
|
| 124 |
+
# Environments
|
| 125 |
+
.env
|
| 126 |
+
.venv
|
| 127 |
+
env/
|
| 128 |
+
venv/
|
| 129 |
+
ENV/
|
| 130 |
+
env.bak/
|
| 131 |
+
venv.bak/
|
| 132 |
+
|
| 133 |
+
# Spyder project settings
|
| 134 |
+
.spyderproject
|
| 135 |
+
.spyproject
|
| 136 |
+
|
| 137 |
+
# Rope project settings
|
| 138 |
+
.ropeproject
|
| 139 |
+
|
| 140 |
+
# mkdocs documentation
|
| 141 |
+
/site
|
| 142 |
+
|
| 143 |
+
# mypy
|
| 144 |
+
.mypy_cache/
|
| 145 |
+
.dmypy.json
|
| 146 |
+
dmypy.json
|
| 147 |
+
|
| 148 |
+
# Pyre type checker
|
| 149 |
+
.pyre/
|
| 150 |
+
|
| 151 |
+
# pytype static type analyzer
|
| 152 |
+
.pytype/
|
| 153 |
+
|
| 154 |
+
# Cython debug symbols
|
| 155 |
+
cython_debug/
|
| 156 |
+
|
| 157 |
+
# PyCharm
|
| 158 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 159 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 160 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 161 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 162 |
+
#.idea/
|
README.md
CHANGED
|
@@ -1,12 +1,46 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance (NeurIPS 2024)
|
| 2 |
+
|
| 3 |
+
<a href="https://arxiv.org/abs/2406.07540"><img src="https://img.shields.io/badge/arXiv-Paper-red"></a>
|
| 4 |
+
<a href="https://genforce.github.io/ctrl-x"><img src="https://img.shields.io/badge/Project-Page-yellow"></a>
|
| 5 |
+
[](https://github.com/genforce/ctrl-x)
|
| 6 |
+
|
| 7 |
+
[Kuan Heng Lin](https://kuanhenglin.github.io)<sup>1*</sup>, [Sicheng Mo](https://sichengmo.github.io/)<sup>1*</sup>, [Ben Klingher](https://bklingher.github.io)<sup>1</sup>, [Fangzhou Mu](https://pages.cs.wisc.edu/~fmu/)<sup>2</sup>, [Bolei Zhou](https://boleizhou.github.io/)<sup>1</sup> <br>
|
| 8 |
+
<sup>1</sup>UCLA <sup>2</sup>NVIDIA <br>
|
| 9 |
+
<sup>*</sup>Equal contribution <br>
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
## Getting started
|
| 14 |
+
|
| 15 |
+
### Environment setup
|
| 16 |
+
|
| 17 |
+
Our code is built on top of [`diffusers v0.28.0`](https://github.com/huggingface/diffusers). To set up the environment, please run the following.
|
| 18 |
+
```
|
| 19 |
+
conda env create -f environment.yaml
|
| 20 |
+
conda activate ctrlx
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
### Gradio demo
|
| 24 |
+
|
| 25 |
+
We provide a user interface for testing our method. Running the following command starts the demo.
|
| 26 |
+
```
|
| 27 |
+
python3 app_ctrlx.py
|
| 28 |
+
```
|
| 29 |
+
Have fun playing around! :D
|
| 30 |
+
|
| 31 |
+
## Contact
|
| 32 |
+
|
| 33 |
+
For any questions, thoughts, discussions, and any other things you want to reach out for, please contact [Kuan Heng (Jordan) Lin](https://kuanhenglin.github.io) ([email protected]).
|
| 34 |
+
|
| 35 |
+
## Reference
|
| 36 |
+
|
| 37 |
+
If you use our code in your research, please cite the following work.
|
| 38 |
+
|
| 39 |
+
```bibtex
|
| 40 |
+
@inproceedings{lin2024ctrlx,
|
| 41 |
+
author = {Lin, {Kuan Heng} and Mo, Sicheng and Klingher, Ben and Mu, Fangzhou and Zhou, Bolei},
|
| 42 |
+
booktitle = {Advances in Neural Information Processing Systems},
|
| 43 |
+
title = {Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance},
|
| 44 |
+
year = {2024}
|
| 45 |
+
}
|
| 46 |
+
```
|
app_ctrlx.py
ADDED
|
@@ -0,0 +1,412 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from argparse import ArgumentParser
|
| 2 |
+
|
| 3 |
+
from diffusers import DDIMScheduler, StableDiffusionXLImg2ImgPipeline
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import torch
|
| 6 |
+
import yaml
|
| 7 |
+
|
| 8 |
+
from ctrl_x.pipelines.pipeline_sdxl import CtrlXStableDiffusionXLPipeline
|
| 9 |
+
from ctrl_x.utils import *
|
| 10 |
+
from ctrl_x.utils.sdxl import *
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
parser = ArgumentParser()
|
| 14 |
+
parser.add_argument("-m", "--model", type=str, default=None) # Optionally, load model checkpoint from single file
|
| 15 |
+
args = parser.parse_args()
|
| 16 |
+
|
| 17 |
+
torch.backends.cudnn.enabled = False # Sometimes necessary to suppress CUDNN_STATUS_NOT_SUPPORTED
|
| 18 |
+
|
| 19 |
+
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
|
| 20 |
+
|
| 21 |
+
model_id_or_path = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 22 |
+
refiner_id_or_path = "stabilityai/stable-diffusion-xl-refiner-1.0"
|
| 23 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 24 |
+
variant = "fp16" if device == "cuda" else "fp32"
|
| 25 |
+
|
| 26 |
+
scheduler = DDIMScheduler.from_config(model_id_or_path, subfolder="scheduler") # TODO: Support other schedulers
|
| 27 |
+
if args.model is None:
|
| 28 |
+
pipe = CtrlXStableDiffusionXLPipeline.from_pretrained(
|
| 29 |
+
model_id_or_path, scheduler=scheduler, torch_dtype=torch_dtype, variant=variant, use_safetensors=True
|
| 30 |
+
)
|
| 31 |
+
else:
|
| 32 |
+
print(f"Using weights {args.model} for SDXL base model.")
|
| 33 |
+
pipe = CtrlXStableDiffusionXLPipeline.from_single_file(args.model, scheduler=scheduler, torch_dtype=torch_dtype)
|
| 34 |
+
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
|
| 35 |
+
refiner_id_or_path, scheduler=scheduler, text_encoder_2=pipe.text_encoder_2, vae=pipe.vae,
|
| 36 |
+
torch_dtype=torch_dtype, variant=variant, use_safetensors=True,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
if torch.cuda.is_available():
|
| 40 |
+
pipe = pipe.to("cuda")
|
| 41 |
+
refiner = refiner.to("cuda")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_control_config(structure_schedule, appearance_schedule):
|
| 45 |
+
s = structure_schedule
|
| 46 |
+
a = appearance_schedule
|
| 47 |
+
|
| 48 |
+
control_config =\
|
| 49 |
+
f"""control_schedule:
|
| 50 |
+
# structure_conv structure_attn appearance_attn conv/attn
|
| 51 |
+
encoder: # (num layers)
|
| 52 |
+
0: [[ ], [ ], [ ]] # 2/0
|
| 53 |
+
1: [[ ], [ ], [{a}, {a} ]] # 2/2
|
| 54 |
+
2: [[ ], [ ], [{a}, {a} ]] # 2/2
|
| 55 |
+
middle: [[ ], [ ], [ ]] # 2/1
|
| 56 |
+
decoder:
|
| 57 |
+
0: [[{s} ], [{s}, {s}, {s}], [0.0, {a}, {a}]] # 3/3
|
| 58 |
+
1: [[ ], [ ], [{a}, {a} ]] # 3/3
|
| 59 |
+
2: [[ ], [ ], [ ]] # 3/0
|
| 60 |
+
|
| 61 |
+
control_target:
|
| 62 |
+
- [output_tensor] # structure_conv choices: {{hidden_states, output_tensor}}
|
| 63 |
+
- [query, key] # structure_attn choices: {{query, key, value}}
|
| 64 |
+
- [before] # appearance_attn choices: {{before, value, after}}
|
| 65 |
+
|
| 66 |
+
self_recurrence_schedule:
|
| 67 |
+
- [0.1, 0.5, 2] # format: [start, end, num_recurrence]"""
|
| 68 |
+
|
| 69 |
+
return control_config
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
css = """
|
| 73 |
+
.config textarea {font-family: monospace; font-size: 80%; white-space: pre}
|
| 74 |
+
.mono {font-family: monospace}
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
title = """
|
| 78 |
+
<div style="display: flex; align-items: center; justify-content: center;margin-bottom: -15px">
|
| 79 |
+
<h1 style="margin-left: 12px;text-align: center;display: inline-block">
|
| 80 |
+
Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance
|
| 81 |
+
</h1>
|
| 82 |
+
<h3 style="display: inline-block; margin-left: 10px; margin-top: 7.5px; font-weight: 500">
|
| 83 |
+
SDXL v1.0
|
| 84 |
+
</h3>
|
| 85 |
+
</div>
|
| 86 |
+
<div style="display: flex; align-items: center; justify-content: center;margin-bottom: 25px">
|
| 87 |
+
<h3 style="text-align: center">
|
| 88 |
+
[<a href="https://genforce.github.io/ctrl-x/">Page</a>]
|
| 89 |
+
|
| 90 |
+
[<a href="https://arxiv.org/abs/2406.07540">Paper</a>]
|
| 91 |
+
|
| 92 |
+
[<a href="https://github.com/genforce/ctrl-x">Code</a>]
|
| 93 |
+
</h3>
|
| 94 |
+
</div>
|
| 95 |
+
<div>
|
| 96 |
+
<p>
|
| 97 |
+
<b>Ctrl-X</b> is a simple training-free and guidance-free framework for text-to-image (T2I) generation with
|
| 98 |
+
structure and appearance control. Given structure and appearance images, Ctrl-X designs feedforward structure
|
| 99 |
+
control to enable structure alignment with the arbitrary structure image and semantic-aware appearance transfer
|
| 100 |
+
to facilitate the appearance transfer from the appearance image.
|
| 101 |
+
</p>
|
| 102 |
+
<p>
|
| 103 |
+
Here are some notes and tips for this demo:
|
| 104 |
+
</p>
|
| 105 |
+
<ul>
|
| 106 |
+
<li> On input images:
|
| 107 |
+
<ul>
|
| 108 |
+
<li>
|
| 109 |
+
If both the structure and appearance images are provided, then Ctrl-X does <i>structure and
|
| 110 |
+
appearance</i> control.
|
| 111 |
+
</li>
|
| 112 |
+
<li>
|
| 113 |
+
If only the structure image is provided, then Ctrl-X does <i>structure-only</i> control and the
|
| 114 |
+
appearance image is jointly generated with the output image.
|
| 115 |
+
</li>
|
| 116 |
+
<li>
|
| 117 |
+
Similarly, if only the appearance image is provided, then Ctrl-X does <i>appearance-only</i>
|
| 118 |
+
control.
|
| 119 |
+
</li>
|
| 120 |
+
</ul>
|
| 121 |
+
</li>
|
| 122 |
+
<li> On prompts:
|
| 123 |
+
<ul>
|
| 124 |
+
<li>
|
| 125 |
+
Though the output prompt can affect the output image to a noticeable extent, the "accuracy" of the
|
| 126 |
+
structure and appearance prompts are not impactful to the final image.
|
| 127 |
+
</li>
|
| 128 |
+
<li>
|
| 129 |
+
If the structure or appearance prompt is left blank, then it uses the (non-optional) output prompt
|
| 130 |
+
by default.
|
| 131 |
+
</li>
|
| 132 |
+
</ul>
|
| 133 |
+
</li>
|
| 134 |
+
<li> On control schedules:
|
| 135 |
+
<ul>
|
| 136 |
+
<li>
|
| 137 |
+
When "Use advanced config" is <b>OFF</b>, the demo uses the structure guidance
|
| 138 |
+
(<span class="mono">structure_conv</span> and <span class="mono">structure_attn</span>
|
| 139 |
+
in the advanced config) and appearance guidance (<span class="mono">appearance_attn</span> in the
|
| 140 |
+
advanced config) sliders to change the control schedules.
|
| 141 |
+
</li>
|
| 142 |
+
<li>
|
| 143 |
+
Otherwise, the demo uses "Advanced control config," which allows per-layer structure and
|
| 144 |
+
appearance schedule control, along with self-recurrence control. <i>This should be used
|
| 145 |
+
carefully</i>, and we recommend switching "Use advanced config" <b>OFF</b> in most cases. (For the
|
| 146 |
+
examples provided at the bottom of the demo, the advanced config uses the default schedules that
|
| 147 |
+
may not be the best settings for these examples.)
|
| 148 |
+
</li>
|
| 149 |
+
</ul>
|
| 150 |
+
</li>
|
| 151 |
+
</ul>
|
| 152 |
+
<p>
|
| 153 |
+
Have fun! :D
|
| 154 |
+
</p>
|
| 155 |
+
</div>
|
| 156 |
+
"""
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def inference(
|
| 160 |
+
structure_image, appearance_image,
|
| 161 |
+
prompt, structure_prompt, appearance_prompt,
|
| 162 |
+
positive_prompt, negative_prompt,
|
| 163 |
+
guidance_scale, structure_guidance_scale, appearance_guidance_scale,
|
| 164 |
+
num_inference_steps, eta, seed,
|
| 165 |
+
width, height,
|
| 166 |
+
structure_schedule, appearance_schedule, use_advanced_config,
|
| 167 |
+
control_config,
|
| 168 |
+
):
|
| 169 |
+
torch.manual_seed(seed)
|
| 170 |
+
|
| 171 |
+
pipe.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 172 |
+
timesteps = pipe.scheduler.timesteps
|
| 173 |
+
|
| 174 |
+
print(f"\nUsing the following control config (use_advanced_config={use_advanced_config}):")
|
| 175 |
+
if not use_advanced_config:
|
| 176 |
+
control_config = get_control_config(structure_schedule, appearance_schedule)
|
| 177 |
+
print(control_config, end="\n\n")
|
| 178 |
+
|
| 179 |
+
config = yaml.safe_load(control_config)
|
| 180 |
+
register_control(
|
| 181 |
+
model = pipe,
|
| 182 |
+
timesteps = timesteps,
|
| 183 |
+
control_schedule = config["control_schedule"],
|
| 184 |
+
control_target = config["control_target"],
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
pipe.safety_checker = None
|
| 188 |
+
pipe.requires_safety_checker = False
|
| 189 |
+
|
| 190 |
+
self_recurrence_schedule = get_self_recurrence_schedule(config["self_recurrence_schedule"], num_inference_steps)
|
| 191 |
+
|
| 192 |
+
pipe.set_progress_bar_config(desc="Ctrl-X inference")
|
| 193 |
+
refiner.set_progress_bar_config(desc="Refiner")
|
| 194 |
+
|
| 195 |
+
result, structure, appearance = pipe(
|
| 196 |
+
prompt = prompt,
|
| 197 |
+
structure_prompt = structure_prompt,
|
| 198 |
+
appearance_prompt = appearance_prompt,
|
| 199 |
+
structure_image = structure_image,
|
| 200 |
+
appearance_image = appearance_image,
|
| 201 |
+
num_inference_steps = num_inference_steps,
|
| 202 |
+
negative_prompt = negative_prompt,
|
| 203 |
+
positive_prompt = positive_prompt,
|
| 204 |
+
height = height,
|
| 205 |
+
width = width,
|
| 206 |
+
guidance_scale = guidance_scale,
|
| 207 |
+
structure_guidance_scale = structure_guidance_scale,
|
| 208 |
+
appearance_guidance_scale = appearance_guidance_scale,
|
| 209 |
+
eta = eta,
|
| 210 |
+
output_type = "pil",
|
| 211 |
+
return_dict = False,
|
| 212 |
+
control_schedule = config["control_schedule"],
|
| 213 |
+
self_recurrence_schedule = self_recurrence_schedule,
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
result_refiner = refiner(
|
| 217 |
+
image = pipe.refiner_args["latents"],
|
| 218 |
+
prompt = pipe.refiner_args["prompt"],
|
| 219 |
+
negative_prompt = pipe.refiner_args["negative_prompt"],
|
| 220 |
+
height = height,
|
| 221 |
+
width = width,
|
| 222 |
+
num_inference_steps = num_inference_steps,
|
| 223 |
+
guidance_scale = guidance_scale,
|
| 224 |
+
guidance_rescale = 0.7,
|
| 225 |
+
num_images_per_prompt = 1,
|
| 226 |
+
eta = eta,
|
| 227 |
+
output_type = "pil",
|
| 228 |
+
).images
|
| 229 |
+
del pipe.refiner_args
|
| 230 |
+
|
| 231 |
+
return [result[0], result_refiner[0], structure[0], appearance[0]]
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
with gr.Blocks(theme=gr.themes.Default(), css=css, title="Ctrl-X (SDXL v1.0)") as app:
|
| 235 |
+
gr.HTML(title)
|
| 236 |
+
|
| 237 |
+
with gr.Row():
|
| 238 |
+
|
| 239 |
+
with gr.Column(scale=55):
|
| 240 |
+
with gr.Group():
|
| 241 |
+
kwargs = {} # {"width": 400, "height": 400}
|
| 242 |
+
with gr.Row():
|
| 243 |
+
result = gr.Image(label="Output image", format="jpg", **kwargs)
|
| 244 |
+
result_refiner = gr.Image(label="Output image w/ refiner", format="jpg", **kwargs)
|
| 245 |
+
with gr.Row():
|
| 246 |
+
structure_recon = gr.Image(label="Structure image", format="jpg", **kwargs)
|
| 247 |
+
appearance_recon = gr.Image(label="Style image", format="jpg", **kwargs)
|
| 248 |
+
with gr.Row():
|
| 249 |
+
structure_image = gr.Image(label="Upload structure image (optional)", type="pil", **kwargs)
|
| 250 |
+
appearance_image = gr.Image(label="Upload appearance image (optional)", type="pil", **kwargs)
|
| 251 |
+
|
| 252 |
+
with gr.Column(scale=45):
|
| 253 |
+
with gr.Group():
|
| 254 |
+
with gr.Row():
|
| 255 |
+
structure_prompt = gr.Textbox(label="Structure prompt (optional)", placeholder="Prompt which describes the structure image")
|
| 256 |
+
appearance_prompt = gr.Textbox(label="Appearance prompt (optional)", placeholder="Prompt which describes the style image")
|
| 257 |
+
with gr.Row():
|
| 258 |
+
prompt = gr.Textbox(label="Output prompt", placeholder="Prompt which describes the output image")
|
| 259 |
+
with gr.Row():
|
| 260 |
+
positive_prompt = gr.Textbox(label="Positive prompt", value="high quality", placeholder="")
|
| 261 |
+
negative_prompt = gr.Textbox(label="Negative prompt", value="ugly, blurry, dark, low res, unrealistic", placeholder="")
|
| 262 |
+
with gr.Row():
|
| 263 |
+
guidance_scale = gr.Slider(label="Target guidance scale", value=5.0, minimum=1, maximum=10)
|
| 264 |
+
structure_guidance_scale = gr.Slider(label="Structure guidance scale", value=5.0, minimum=1, maximum=10)
|
| 265 |
+
appearance_guidance_scale = gr.Slider(label="Appearance guidance scale", value=5.0, minimum=1, maximum=10)
|
| 266 |
+
with gr.Row():
|
| 267 |
+
num_inference_steps = gr.Slider(label="# inference steps", value=50, minimum=1, maximum=200, step=1)
|
| 268 |
+
eta = gr.Slider(label="Eta (noise)", value=1.0, minimum=0, maximum=1.0, step=0.01)
|
| 269 |
+
seed = gr.Slider(0, 2147483647, label="Seed", value=90095, step=1)
|
| 270 |
+
with gr.Row():
|
| 271 |
+
width = gr.Slider(label="Width", value=1024, minimum=256, maximum=2048, step=pipe.vae_scale_factor)
|
| 272 |
+
height = gr.Slider(label="Height", value=1024, minimum=256, maximum=2048, step=pipe.vae_scale_factor)
|
| 273 |
+
with gr.Row():
|
| 274 |
+
structure_schedule = gr.Slider(label="Structure schedule", value=0.6, minimum=0.0, maximum=1.0, step=0.01, scale=2)
|
| 275 |
+
appearance_schedule = gr.Slider(label="Appearance schedule", value=0.6, minimum=0.0, maximum=1.0, step=0.01, scale=2)
|
| 276 |
+
use_advanced_config = gr.Checkbox(label="Use advanced config", value=False, scale=1)
|
| 277 |
+
with gr.Row():
|
| 278 |
+
control_config = gr.Textbox(
|
| 279 |
+
label="Advanced control config", lines=20, value=get_control_config(0.6, 0.6), elem_classes=["config"], visible=False,
|
| 280 |
+
)
|
| 281 |
+
use_advanced_config.change(
|
| 282 |
+
fn=lambda value: gr.update(visible=value), inputs=use_advanced_config, outputs=control_config,
|
| 283 |
+
)
|
| 284 |
+
with gr.Row():
|
| 285 |
+
generate = gr.Button(value="Run")
|
| 286 |
+
|
| 287 |
+
inputs = [
|
| 288 |
+
structure_image, appearance_image,
|
| 289 |
+
prompt, structure_prompt, appearance_prompt,
|
| 290 |
+
positive_prompt, negative_prompt,
|
| 291 |
+
guidance_scale, structure_guidance_scale, appearance_guidance_scale,
|
| 292 |
+
num_inference_steps, eta, seed,
|
| 293 |
+
width, height,
|
| 294 |
+
structure_schedule, appearance_schedule, use_advanced_config,
|
| 295 |
+
control_config,
|
| 296 |
+
]
|
| 297 |
+
outputs = [result, result_refiner, structure_recon, appearance_recon]
|
| 298 |
+
|
| 299 |
+
generate.click(inference, inputs=inputs, outputs=outputs)
|
| 300 |
+
|
| 301 |
+
examples = gr.Examples(
|
| 302 |
+
[
|
| 303 |
+
[
|
| 304 |
+
"assets/images/horse__point_cloud.jpg",
|
| 305 |
+
"assets/images/horse.jpg",
|
| 306 |
+
"a 3D point cloud of a horse",
|
| 307 |
+
"",
|
| 308 |
+
"a photo of a horse standing on grass",
|
| 309 |
+
0.6, 0.6,
|
| 310 |
+
],
|
| 311 |
+
[
|
| 312 |
+
"assets/images/cat__mesh.jpg",
|
| 313 |
+
"assets/images/tiger.jpg",
|
| 314 |
+
"a 3D mesh of a cat",
|
| 315 |
+
"",
|
| 316 |
+
"a photo of a tiger standing on snow",
|
| 317 |
+
0.6, 0.6,
|
| 318 |
+
],
|
| 319 |
+
[
|
| 320 |
+
"assets/images/dog__sketch.jpg",
|
| 321 |
+
"assets/images/squirrel.jpg",
|
| 322 |
+
"a sketch of a dog",
|
| 323 |
+
"",
|
| 324 |
+
"a photo of a squirrel",
|
| 325 |
+
0.6, 0.6,
|
| 326 |
+
],
|
| 327 |
+
[
|
| 328 |
+
"assets/images/living_room__seg.jpg",
|
| 329 |
+
"assets/images/van_gogh.jpg",
|
| 330 |
+
"a segmentation map of a living room",
|
| 331 |
+
"",
|
| 332 |
+
"a Van Gogh painting of a living room",
|
| 333 |
+
0.6, 0.6,
|
| 334 |
+
],
|
| 335 |
+
[
|
| 336 |
+
"assets/images/bedroom__sketch.jpg",
|
| 337 |
+
"assets/images/living_room_modern.jpg",
|
| 338 |
+
"a sketch of a bedroom",
|
| 339 |
+
"",
|
| 340 |
+
"a photo of a modern bedroom during sunset",
|
| 341 |
+
0.6, 0.6,
|
| 342 |
+
],
|
| 343 |
+
[
|
| 344 |
+
"assets/images/running__pose.jpg",
|
| 345 |
+
"assets/images/man_park.jpg",
|
| 346 |
+
"a pose image of a person running",
|
| 347 |
+
"",
|
| 348 |
+
"a photo of a man running in a park",
|
| 349 |
+
0.4, 0.6,
|
| 350 |
+
],
|
| 351 |
+
[
|
| 352 |
+
"assets/images/fruit_bowl.jpg",
|
| 353 |
+
"assets/images/grapes.jpg",
|
| 354 |
+
"a photo of a bowl of fruits",
|
| 355 |
+
"",
|
| 356 |
+
"a photo of a bowl of grapes in the trees",
|
| 357 |
+
0.6, 0.6,
|
| 358 |
+
],
|
| 359 |
+
[
|
| 360 |
+
"assets/images/bear_avocado__spatext.jpg",
|
| 361 |
+
None,
|
| 362 |
+
"a segmentation map of a bear and an avocado",
|
| 363 |
+
"",
|
| 364 |
+
"a realistic photo of a bear and an avocado in a forest",
|
| 365 |
+
0.6, 0.6,
|
| 366 |
+
],
|
| 367 |
+
[
|
| 368 |
+
"assets/images/cat__point_cloud.jpg",
|
| 369 |
+
None,
|
| 370 |
+
"a 3D point cloud of a cat",
|
| 371 |
+
"",
|
| 372 |
+
"an embroidery of a white cat sitting on a rock under the night sky",
|
| 373 |
+
0.6, 0.6,
|
| 374 |
+
],
|
| 375 |
+
[
|
| 376 |
+
"assets/images/library__mesh.jpg",
|
| 377 |
+
None,
|
| 378 |
+
"a 3D mesh of a library",
|
| 379 |
+
"",
|
| 380 |
+
"a Polaroid photo of an old library, sunlight streaming in",
|
| 381 |
+
0.6, 0.6,
|
| 382 |
+
],
|
| 383 |
+
[
|
| 384 |
+
"assets/images/knight__humanoid.jpg",
|
| 385 |
+
None,
|
| 386 |
+
"a 3D model of a person holding a sword and shield",
|
| 387 |
+
"",
|
| 388 |
+
"a photo of a medieval soldier standing on a barren field, raining",
|
| 389 |
+
0.6, 0.6,
|
| 390 |
+
],
|
| 391 |
+
[
|
| 392 |
+
"assets/images/person__mesh.jpg",
|
| 393 |
+
None,
|
| 394 |
+
"a 3D mesh of a person",
|
| 395 |
+
"",
|
| 396 |
+
"a photo of a Karate man performing in a cyberpunk city at night",
|
| 397 |
+
0.5, 0.6,
|
| 398 |
+
],
|
| 399 |
+
],
|
| 400 |
+
[
|
| 401 |
+
structure_image,
|
| 402 |
+
appearance_image,
|
| 403 |
+
structure_prompt,
|
| 404 |
+
appearance_prompt,
|
| 405 |
+
prompt,
|
| 406 |
+
structure_schedule,
|
| 407 |
+
appearance_schedule,
|
| 408 |
+
],
|
| 409 |
+
examples_per_page=50,
|
| 410 |
+
)
|
| 411 |
+
|
| 412 |
+
app.launch(debug=False, share=False)
|
assets/images/bear_avocado__spatext.jpg
ADDED

|
assets/images/bedroom__sketch.jpg
ADDED
|
assets/images/cat__mesh.jpg
ADDED

|
assets/images/cat__point_cloud.jpg
ADDED
|
assets/images/dog__sketch.jpg
ADDED

|
assets/images/fruit_bowl.jpg
ADDED

|
assets/images/grapes.jpg
ADDED

|
assets/images/horse.jpg
ADDED

|
assets/images/horse__point_cloud.jpg
ADDED

|
assets/images/knight__humanoid.jpg
ADDED

|
assets/images/library__mesh.jpg
ADDED

|
assets/images/living_room__seg.jpg
ADDED

|
assets/images/living_room_modern.jpg
ADDED

|
assets/images/man_park.jpg
ADDED

|
assets/images/person__mesh.jpg
ADDED

|
assets/images/running__pose.jpg
ADDED

|
assets/images/squirrel.jpg
ADDED

|
assets/images/tiger.jpg
ADDED

|
assets/images/van_gogh.jpg
ADDED

|
ctrl_x/__init__.py
ADDED
|
File without changes
|
ctrl_x/pipelines/__init__.py
ADDED
|
File without changes
|
ctrl_x/pipelines/pipeline_sdxl.py
ADDED
|
@@ -0,0 +1,665 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
from diffusers import StableDiffusionXLPipeline
|
| 6 |
+
from diffusers.image_processor import PipelineImageInput
|
| 7 |
+
from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img import\
|
| 8 |
+
rescale_noise_cfg, retrieve_latents, retrieve_timesteps
|
| 9 |
+
from diffusers.utils import BaseOutput, deprecate
|
| 10 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 11 |
+
import numpy as np
|
| 12 |
+
import PIL
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
from ..utils import *
|
| 16 |
+
from ..utils.sdxl import *
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
BATCH_ORDER = [
|
| 20 |
+
"structure_uncond", "appearance_uncond", "uncond", "structure_cond", "appearance_cond", "cond",
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def get_last_control_i(control_schedule, num_inference_steps):
|
| 25 |
+
if control_schedule is None:
|
| 26 |
+
return num_inference_steps, num_inference_steps
|
| 27 |
+
|
| 28 |
+
def max_(l):
|
| 29 |
+
if len(l) == 0:
|
| 30 |
+
return 0.0
|
| 31 |
+
return max(l)
|
| 32 |
+
|
| 33 |
+
structure_max = 0.0
|
| 34 |
+
appearance_max = 0.0
|
| 35 |
+
for block in control_schedule.values():
|
| 36 |
+
if isinstance(block, list): # Handling mid_block
|
| 37 |
+
block = {0: block}
|
| 38 |
+
for layer in block.values():
|
| 39 |
+
structure_max = max(structure_max, max_(layer[0] + layer[1]))
|
| 40 |
+
appearance_max = max(appearance_max, max_(layer[2]))
|
| 41 |
+
|
| 42 |
+
structure_i = round(num_inference_steps * structure_max)
|
| 43 |
+
appearance_i = round(num_inference_steps * appearance_max)
|
| 44 |
+
return structure_i, appearance_i
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
@dataclass
|
| 48 |
+
class CtrlXStableDiffusionXLPipelineOutput(BaseOutput):
|
| 49 |
+
images: Union[List[PIL.Image.Image], np.ndarray]
|
| 50 |
+
structures = Union[List[PIL.Image.Image], np.ndarray]
|
| 51 |
+
appearances = Union[List[PIL.Image.Image], np.ndarray]
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class CtrlXStableDiffusionXLPipeline(StableDiffusionXLPipeline): # diffusers==0.28.0
|
| 55 |
+
|
| 56 |
+
def prepare_latents(
|
| 57 |
+
self, image, batch_size, num_images_per_prompt, num_channels_latents, height, width,
|
| 58 |
+
dtype, device, generator=None, noise=None,
|
| 59 |
+
):
|
| 60 |
+
batch_size = batch_size * num_images_per_prompt
|
| 61 |
+
|
| 62 |
+
if noise is None:
|
| 63 |
+
shape = (
|
| 64 |
+
batch_size,
|
| 65 |
+
num_channels_latents,
|
| 66 |
+
height // self.vae_scale_factor,
|
| 67 |
+
width // self.vae_scale_factor
|
| 68 |
+
)
|
| 69 |
+
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 70 |
+
noise = noise * self.scheduler.init_noise_sigma # Starting noise, need to scale
|
| 71 |
+
else:
|
| 72 |
+
noise = noise.to(device)
|
| 73 |
+
|
| 74 |
+
if image is None:
|
| 75 |
+
return noise, None
|
| 76 |
+
|
| 77 |
+
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
| 78 |
+
raise ValueError(
|
| 79 |
+
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Offload text encoder if `enable_model_cpu_offload` was enabled
|
| 83 |
+
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
| 84 |
+
self.text_encoder_2.to("cpu")
|
| 85 |
+
torch.cuda.empty_cache()
|
| 86 |
+
|
| 87 |
+
image = image.to(device=device, dtype=dtype)
|
| 88 |
+
|
| 89 |
+
if image.shape[1] == 4: # Image already in latents form
|
| 90 |
+
init_latents = image
|
| 91 |
+
|
| 92 |
+
else:
|
| 93 |
+
# Make sure the VAE is in float32 mode, as it overflows in float16
|
| 94 |
+
if self.vae.config.force_upcast:
|
| 95 |
+
image = image.to(torch.float32)
|
| 96 |
+
self.vae.to(torch.float32)
|
| 97 |
+
|
| 98 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 99 |
+
raise ValueError(
|
| 100 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 101 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 102 |
+
)
|
| 103 |
+
elif isinstance(generator, list):
|
| 104 |
+
init_latents = [
|
| 105 |
+
retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
|
| 106 |
+
for i in range(batch_size)
|
| 107 |
+
]
|
| 108 |
+
init_latents = torch.cat(init_latents, dim=0)
|
| 109 |
+
else:
|
| 110 |
+
init_latents = retrieve_latents(self.vae.encode(image), generator=generator)
|
| 111 |
+
|
| 112 |
+
if self.vae.config.force_upcast:
|
| 113 |
+
self.vae.to(dtype)
|
| 114 |
+
|
| 115 |
+
init_latents = init_latents.to(dtype)
|
| 116 |
+
init_latents = self.vae.config.scaling_factor * init_latents
|
| 117 |
+
|
| 118 |
+
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
|
| 119 |
+
# Expand init_latents for batch_size
|
| 120 |
+
additional_image_per_prompt = batch_size // init_latents.shape[0]
|
| 121 |
+
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
|
| 122 |
+
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
|
| 123 |
+
raise ValueError(
|
| 124 |
+
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
|
| 125 |
+
)
|
| 126 |
+
else:
|
| 127 |
+
init_latents = torch.cat([init_latents], dim=0)
|
| 128 |
+
|
| 129 |
+
return noise, init_latents
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def structure_guidance_scale(self):
|
| 133 |
+
return self._guidance_scale if self._structure_guidance_scale is None else self._structure_guidance_scale
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def appearance_guidance_scale(self):
|
| 137 |
+
return self._guidance_scale if self._appearance_guidance_scale is None else self._appearance_guidance_scale
|
| 138 |
+
|
| 139 |
+
@torch.no_grad()
|
| 140 |
+
def __call__(
|
| 141 |
+
self,
|
| 142 |
+
prompt: Union[str, List[str]] = None, # TODO: Support prompt_2 and negative_prompt_2
|
| 143 |
+
structure_prompt: Optional[Union[str, List[str]]] = None,
|
| 144 |
+
appearance_prompt: Optional[Union[str, List[str]]] = None,
|
| 145 |
+
structure_image: Optional[PipelineImageInput] = None,
|
| 146 |
+
appearance_image: Optional[PipelineImageInput] = None,
|
| 147 |
+
num_inference_steps: int = 50,
|
| 148 |
+
timesteps: List[int] = None,
|
| 149 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 150 |
+
positive_prompt: Optional[Union[str, List[str]]] = None,
|
| 151 |
+
height: Optional[int] = None,
|
| 152 |
+
width: Optional[int] = None,
|
| 153 |
+
guidance_scale: float = 5.0,
|
| 154 |
+
structure_guidance_scale: Optional[float] = None,
|
| 155 |
+
appearance_guidance_scale: Optional[float] = None,
|
| 156 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 157 |
+
eta: float = 0.0,
|
| 158 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 159 |
+
latents: Optional[torch.Tensor] = None,
|
| 160 |
+
structure_latents: Optional[torch.Tensor] = None,
|
| 161 |
+
appearance_latents: Optional[torch.Tensor] = None,
|
| 162 |
+
prompt_embeds: Optional[torch.Tensor] = None, # Positive prompt is concatenated with prompt, so no embeddings
|
| 163 |
+
structure_prompt_embeds: Optional[torch.Tensor] = None,
|
| 164 |
+
appearance_prompt_embeds: Optional[torch.Tensor] = None,
|
| 165 |
+
negative_prompt_embeds: Optional[torch.Tensor] = None,
|
| 166 |
+
pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
| 167 |
+
structure_pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
| 168 |
+
appearance_pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
| 169 |
+
negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
| 170 |
+
control_schedule: Optional[Dict] = None,
|
| 171 |
+
self_recurrence_schedule: Optional[List[int]] = [], # Format: [(start, end, num_repeat)]
|
| 172 |
+
decode_structure: Optional[bool] = True,
|
| 173 |
+
decode_appearance: Optional[bool] = True,
|
| 174 |
+
output_type: Optional[str] = "pil",
|
| 175 |
+
return_dict: bool = True,
|
| 176 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 177 |
+
guidance_rescale: float = 0.0,
|
| 178 |
+
original_size: Tuple[int, int] = None,
|
| 179 |
+
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 180 |
+
target_size: Tuple[int, int] = None,
|
| 181 |
+
clip_skip: Optional[int] = None,
|
| 182 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 183 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 184 |
+
**kwargs,
|
| 185 |
+
):
|
| 186 |
+
# TODO: Add function argument documentation
|
| 187 |
+
|
| 188 |
+
callback = kwargs.pop("callback", None)
|
| 189 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 190 |
+
|
| 191 |
+
if callback is not None:
|
| 192 |
+
deprecate(
|
| 193 |
+
"callback",
|
| 194 |
+
"1.0.0",
|
| 195 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 196 |
+
)
|
| 197 |
+
if callback_steps is not None:
|
| 198 |
+
deprecate(
|
| 199 |
+
"callback_steps",
|
| 200 |
+
"1.0.0",
|
| 201 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
# 0. Default height and width to U-Net
|
| 205 |
+
height = height or self.default_sample_size * self.vae_scale_factor
|
| 206 |
+
width = width or self.default_sample_size * self.vae_scale_factor
|
| 207 |
+
original_size = original_size or (height, width)
|
| 208 |
+
target_size = target_size or (height, width)
|
| 209 |
+
|
| 210 |
+
# 1. Check inputs. Raise error if not correct
|
| 211 |
+
self.check_inputs( # TODO: Custom check_inputs for our method
|
| 212 |
+
prompt,
|
| 213 |
+
None, # prompt_2
|
| 214 |
+
height,
|
| 215 |
+
width,
|
| 216 |
+
callback_steps,
|
| 217 |
+
negative_prompt = negative_prompt,
|
| 218 |
+
negative_prompt_2 = None, # negative_prompt_2
|
| 219 |
+
prompt_embeds = prompt_embeds,
|
| 220 |
+
negative_prompt_embeds = negative_prompt_embeds,
|
| 221 |
+
pooled_prompt_embeds = pooled_prompt_embeds,
|
| 222 |
+
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds,
|
| 223 |
+
callback_on_step_end_tensor_inputs = callback_on_step_end_tensor_inputs,
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
self._guidance_scale = guidance_scale
|
| 227 |
+
self._structure_guidance_scale = structure_guidance_scale
|
| 228 |
+
self._appearance_guidance_scale = appearance_guidance_scale
|
| 229 |
+
self._guidance_rescale = guidance_rescale
|
| 230 |
+
self._clip_skip = clip_skip
|
| 231 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 232 |
+
self._denoising_end = None # denoising_end
|
| 233 |
+
self._denoising_start = None # denoising_start
|
| 234 |
+
self._interrupt = False
|
| 235 |
+
|
| 236 |
+
# 2. Define call parameters
|
| 237 |
+
if prompt is not None and isinstance(prompt, str):
|
| 238 |
+
batch_size = 1
|
| 239 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 240 |
+
batch_size = len(prompt)
|
| 241 |
+
else:
|
| 242 |
+
batch_size = prompt_embeds.shape[0]
|
| 243 |
+
|
| 244 |
+
if batch_size * num_images_per_prompt != 1:
|
| 245 |
+
raise ValueError(
|
| 246 |
+
f"Pipeline currently does not support batch_size={batch_size} and num_images_per_prompt=1. "
|
| 247 |
+
"Effective batch size (batch_size * num_images_per_prompt) must be 1."
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
device = self._execution_device
|
| 251 |
+
|
| 252 |
+
# 3. Encode input prompt
|
| 253 |
+
text_encoder_lora_scale = (
|
| 254 |
+
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
if positive_prompt is not None and positive_prompt != "":
|
| 258 |
+
prompt = prompt + ", " + positive_prompt # Add positive prompt with comma
|
| 259 |
+
# By default, only add positive prompt to the appearance prompt and not the structure prompt
|
| 260 |
+
if appearance_prompt is not None and appearance_prompt != "":
|
| 261 |
+
appearance_prompt = appearance_prompt + ", " + positive_prompt
|
| 262 |
+
|
| 263 |
+
(
|
| 264 |
+
prompt_embeds_,
|
| 265 |
+
negative_prompt_embeds,
|
| 266 |
+
pooled_prompt_embeds_,
|
| 267 |
+
negative_pooled_prompt_embeds,
|
| 268 |
+
) = self.encode_prompt(
|
| 269 |
+
prompt = prompt,
|
| 270 |
+
prompt_2 = None, # prompt_2
|
| 271 |
+
device = device,
|
| 272 |
+
num_images_per_prompt = num_images_per_prompt,
|
| 273 |
+
do_classifier_free_guidance = True, # self.do_classifier_free_guidance, TODO: Support no CFG
|
| 274 |
+
negative_prompt = negative_prompt,
|
| 275 |
+
negative_prompt_2 = None, # negative_prompt_2
|
| 276 |
+
prompt_embeds = prompt_embeds,
|
| 277 |
+
negative_prompt_embeds = negative_prompt_embeds,
|
| 278 |
+
pooled_prompt_embeds = pooled_prompt_embeds,
|
| 279 |
+
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds,
|
| 280 |
+
lora_scale = text_encoder_lora_scale,
|
| 281 |
+
clip_skip = self.clip_skip,
|
| 282 |
+
)
|
| 283 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds_], dim=0).to(device)
|
| 284 |
+
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds_], dim=0).to(device)
|
| 285 |
+
|
| 286 |
+
# 3.1. Structure prompt embeddings
|
| 287 |
+
if structure_prompt is not None and structure_prompt != "":
|
| 288 |
+
(
|
| 289 |
+
structure_prompt_embeds,
|
| 290 |
+
negative_structure_prompt_embeds,
|
| 291 |
+
structure_pooled_prompt_embeds,
|
| 292 |
+
negative_structure_pooled_prompt_embeds,
|
| 293 |
+
) = self.encode_prompt(
|
| 294 |
+
prompt = structure_prompt,
|
| 295 |
+
prompt_2 = None, # prompt_2
|
| 296 |
+
device = device,
|
| 297 |
+
num_images_per_prompt = num_images_per_prompt,
|
| 298 |
+
do_classifier_free_guidance = True, # self.do_classifier_free_guidance, TODO: Support no CFG
|
| 299 |
+
negative_prompt = negative_prompt if structure_image is None else "",
|
| 300 |
+
negative_prompt_2 = None, # negative_prompt_2
|
| 301 |
+
prompt_embeds = structure_prompt_embeds,
|
| 302 |
+
negative_prompt_embeds = None, # negative_prompt_embeds
|
| 303 |
+
pooled_prompt_embeds = structure_pooled_prompt_embeds,
|
| 304 |
+
negative_pooled_prompt_embeds = None, # negative_pooled_prompt_embeds
|
| 305 |
+
lora_scale = text_encoder_lora_scale,
|
| 306 |
+
clip_skip = self.clip_skip,
|
| 307 |
+
)
|
| 308 |
+
structure_prompt_embeds = torch.cat(
|
| 309 |
+
[negative_structure_prompt_embeds, structure_prompt_embeds], dim=0
|
| 310 |
+
).to(device)
|
| 311 |
+
structure_add_text_embeds = torch.cat(
|
| 312 |
+
[negative_structure_pooled_prompt_embeds, structure_pooled_prompt_embeds], dim=0
|
| 313 |
+
).to(device)
|
| 314 |
+
else:
|
| 315 |
+
structure_prompt_embeds = prompt_embeds
|
| 316 |
+
structure_add_text_embeds = add_text_embeds
|
| 317 |
+
|
| 318 |
+
# 3.2. Appearance prompt embeddings
|
| 319 |
+
if appearance_prompt is not None and appearance_prompt != "":
|
| 320 |
+
(
|
| 321 |
+
appearance_prompt_embeds,
|
| 322 |
+
negative_appearance_prompt_embeds,
|
| 323 |
+
appearance_pooled_prompt_embeds,
|
| 324 |
+
negative_appearance_pooled_prompt_embeds,
|
| 325 |
+
) = self.encode_prompt(
|
| 326 |
+
prompt = appearance_prompt,
|
| 327 |
+
prompt_2 = None, # prompt_2
|
| 328 |
+
device = device,
|
| 329 |
+
num_images_per_prompt = num_images_per_prompt,
|
| 330 |
+
do_classifier_free_guidance = True, # self.do_classifier_free_guidance, TODO: Support no CFG
|
| 331 |
+
negative_prompt = negative_prompt if appearance_image is None else "",
|
| 332 |
+
negative_prompt_2 = None, # negative_prompt_2
|
| 333 |
+
prompt_embeds = appearance_prompt_embeds,
|
| 334 |
+
negative_prompt_embeds = None, # negative_prompt_embeds
|
| 335 |
+
pooled_prompt_embeds = appearance_pooled_prompt_embeds, # pooled_prompt_embeds
|
| 336 |
+
negative_pooled_prompt_embeds = None, # negative_pooled_prompt_embeds
|
| 337 |
+
lora_scale = text_encoder_lora_scale,
|
| 338 |
+
clip_skip = self.clip_skip,
|
| 339 |
+
)
|
| 340 |
+
appearance_prompt_embeds = torch.cat(
|
| 341 |
+
[negative_appearance_prompt_embeds, appearance_prompt_embeds], dim=0
|
| 342 |
+
).to(device)
|
| 343 |
+
appearance_add_text_embeds = torch.cat(
|
| 344 |
+
[negative_appearance_pooled_prompt_embeds, appearance_pooled_prompt_embeds], dim=0
|
| 345 |
+
).to(device)
|
| 346 |
+
else:
|
| 347 |
+
appearance_prompt_embeds = prompt_embeds
|
| 348 |
+
appearance_add_text_embeds = add_text_embeds
|
| 349 |
+
|
| 350 |
+
# 3.3. Prepare added time ids & embeddings, TODO: Support no CFG
|
| 351 |
+
if self.text_encoder_2 is None:
|
| 352 |
+
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
|
| 353 |
+
else:
|
| 354 |
+
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
|
| 355 |
+
|
| 356 |
+
add_time_ids = self._get_add_time_ids(
|
| 357 |
+
original_size,
|
| 358 |
+
crops_coords_top_left,
|
| 359 |
+
target_size,
|
| 360 |
+
dtype = prompt_embeds.dtype,
|
| 361 |
+
text_encoder_projection_dim = text_encoder_projection_dim,
|
| 362 |
+
)
|
| 363 |
+
negative_add_time_ids = add_time_ids
|
| 364 |
+
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0).to(device)
|
| 365 |
+
|
| 366 |
+
# 4. Prepare timesteps
|
| 367 |
+
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
| 368 |
+
|
| 369 |
+
# 5. Prepare latent variables
|
| 370 |
+
num_channels_latents = self.unet.config.in_channels
|
| 371 |
+
|
| 372 |
+
latents, _ = self.prepare_latents(
|
| 373 |
+
None, batch_size, num_images_per_prompt, num_channels_latents, height, width,
|
| 374 |
+
prompt_embeds.dtype, device, generator, latents
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
if structure_image is not None:
|
| 378 |
+
structure_image = preprocess( # Center crop + resize
|
| 379 |
+
structure_image, self.image_processor, height=height, width=width, resize_mode="crop"
|
| 380 |
+
)
|
| 381 |
+
_, clean_structure_latents = self.prepare_latents(
|
| 382 |
+
structure_image, batch_size, num_images_per_prompt, num_channels_latents, height, width,
|
| 383 |
+
prompt_embeds.dtype, device, generator, structure_latents,
|
| 384 |
+
)
|
| 385 |
+
else:
|
| 386 |
+
clean_structure_latents = None
|
| 387 |
+
structure_latents = latents if structure_latents is None else structure_latents
|
| 388 |
+
|
| 389 |
+
if appearance_image is not None:
|
| 390 |
+
appearance_image = preprocess( # Center crop + resize
|
| 391 |
+
appearance_image, self.image_processor, height=height, width=width, resize_mode="crop"
|
| 392 |
+
)
|
| 393 |
+
_, clean_appearance_latents = self.prepare_latents(
|
| 394 |
+
appearance_image, batch_size, num_images_per_prompt, num_channels_latents, height, width,
|
| 395 |
+
prompt_embeds.dtype, device, generator, appearance_latents,
|
| 396 |
+
)
|
| 397 |
+
else:
|
| 398 |
+
clean_appearance_latents = None
|
| 399 |
+
appearance_latents = latents if appearance_latents is None else appearance_latents
|
| 400 |
+
|
| 401 |
+
# 6. Prepare extra step kwargs
|
| 402 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 403 |
+
|
| 404 |
+
# 7. Denoising loop
|
| 405 |
+
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
| 406 |
+
|
| 407 |
+
# 7.1 Apply denoising_end
|
| 408 |
+
def denoising_value_valid(dnv):
|
| 409 |
+
return isinstance(self.denoising_end, float) and 0 < dnv < 1
|
| 410 |
+
|
| 411 |
+
if (
|
| 412 |
+
self.denoising_end is not None
|
| 413 |
+
and self.denoising_start is not None
|
| 414 |
+
and denoising_value_valid(self.denoising_end)
|
| 415 |
+
and denoising_value_valid(self.denoising_start)
|
| 416 |
+
and self.denoising_start >= self.denoising_end
|
| 417 |
+
):
|
| 418 |
+
raise ValueError(
|
| 419 |
+
f"`denoising_start`: {self.denoising_start} cannot be larger than or equal to `denoising_end`: "
|
| 420 |
+
+ f" {self.denoising_end} when using type float."
|
| 421 |
+
)
|
| 422 |
+
elif self.denoising_end is not None and denoising_value_valid(self.denoising_end):
|
| 423 |
+
discrete_timestep_cutoff = int(
|
| 424 |
+
round(
|
| 425 |
+
self.scheduler.config.num_train_timesteps
|
| 426 |
+
- (self.denoising_end * self.scheduler.config.num_train_timesteps)
|
| 427 |
+
)
|
| 428 |
+
)
|
| 429 |
+
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
|
| 430 |
+
timesteps = timesteps[:num_inference_steps]
|
| 431 |
+
|
| 432 |
+
# 7.2 Optionally get guidance scale embedding
|
| 433 |
+
timestep_cond = None
|
| 434 |
+
if self.unet.config.time_cond_proj_dim is not None: # TODO: Make guidance scale embedding work with batch_order
|
| 435 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
| 436 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 437 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 438 |
+
).to(device=device, dtype=latents.dtype)
|
| 439 |
+
|
| 440 |
+
# 7.3 Get batch order
|
| 441 |
+
batch_order = deepcopy(BATCH_ORDER)
|
| 442 |
+
if structure_image is not None: # If image is provided, not generating, so no CFG needed
|
| 443 |
+
batch_order.remove("structure_uncond")
|
| 444 |
+
if appearance_image is not None:
|
| 445 |
+
batch_order.remove("appearance_uncond")
|
| 446 |
+
|
| 447 |
+
structure_control_stop_i, appearance_control_stop_i = get_last_control_i(control_schedule, num_inference_steps)
|
| 448 |
+
if self_recurrence_schedule is None:
|
| 449 |
+
self_recurrence_schedule = [0] * num_inference_steps
|
| 450 |
+
|
| 451 |
+
self._num_timesteps = len(timesteps)
|
| 452 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 453 |
+
for i, t in enumerate(timesteps):
|
| 454 |
+
if self.interrupt:
|
| 455 |
+
continue
|
| 456 |
+
|
| 457 |
+
if i == structure_control_stop_i: # If not generating structure/appearance, drop after last control
|
| 458 |
+
if "structure_uncond" not in batch_order:
|
| 459 |
+
batch_order.remove("structure_cond")
|
| 460 |
+
if i == appearance_control_stop_i:
|
| 461 |
+
if "appearance_uncond" not in batch_order:
|
| 462 |
+
batch_order.remove("appearance_cond")
|
| 463 |
+
|
| 464 |
+
register_attr(self, t=t.item(), do_control=True, batch_order=batch_order)
|
| 465 |
+
|
| 466 |
+
# TODO: For now, assume we are doing classifier-free guidance, support no CF-guidance later
|
| 467 |
+
latent_model_input = self.scheduler.scale_model_input(latents, t)
|
| 468 |
+
structure_latent_model_input = self.scheduler.scale_model_input(structure_latents, t)
|
| 469 |
+
appearance_latent_model_input = self.scheduler.scale_model_input(appearance_latents, t)
|
| 470 |
+
|
| 471 |
+
all_latent_model_input = {
|
| 472 |
+
"structure_uncond": structure_latent_model_input[0:1],
|
| 473 |
+
"appearance_uncond": appearance_latent_model_input[0:1],
|
| 474 |
+
"uncond": latent_model_input[0:1],
|
| 475 |
+
"structure_cond": structure_latent_model_input[0:1],
|
| 476 |
+
"appearance_cond": appearance_latent_model_input[0:1],
|
| 477 |
+
"cond": latent_model_input[0:1],
|
| 478 |
+
}
|
| 479 |
+
all_prompt_embeds = {
|
| 480 |
+
"structure_uncond": structure_prompt_embeds[0:1],
|
| 481 |
+
"appearance_uncond": appearance_prompt_embeds[0:1],
|
| 482 |
+
"uncond": prompt_embeds[0:1],
|
| 483 |
+
"structure_cond": structure_prompt_embeds[1:2],
|
| 484 |
+
"appearance_cond": appearance_prompt_embeds[1:2],
|
| 485 |
+
"cond": prompt_embeds[1:2],
|
| 486 |
+
}
|
| 487 |
+
all_add_text_embeds = {
|
| 488 |
+
"structure_uncond": structure_add_text_embeds[0:1],
|
| 489 |
+
"appearance_uncond": appearance_add_text_embeds[0:1],
|
| 490 |
+
"uncond": add_text_embeds[0:1],
|
| 491 |
+
"structure_cond": structure_add_text_embeds[1:2],
|
| 492 |
+
"appearance_cond": appearance_add_text_embeds[1:2],
|
| 493 |
+
"cond": add_text_embeds[1:2],
|
| 494 |
+
}
|
| 495 |
+
all_time_ids = {
|
| 496 |
+
"structure_uncond": add_time_ids[0:1],
|
| 497 |
+
"appearance_uncond": add_time_ids[0:1],
|
| 498 |
+
"uncond": add_time_ids[0:1],
|
| 499 |
+
"structure_cond": add_time_ids[1:2],
|
| 500 |
+
"appearance_cond": add_time_ids[1:2],
|
| 501 |
+
"cond": add_time_ids[1:2],
|
| 502 |
+
}
|
| 503 |
+
|
| 504 |
+
concat_latent_model_input = batch_dict_to_tensor(all_latent_model_input, batch_order)
|
| 505 |
+
concat_prompt_embeds = batch_dict_to_tensor(all_prompt_embeds, batch_order)
|
| 506 |
+
concat_add_text_embeds = batch_dict_to_tensor(all_add_text_embeds, batch_order)
|
| 507 |
+
concat_add_time_ids = batch_dict_to_tensor(all_time_ids, batch_order)
|
| 508 |
+
|
| 509 |
+
# Predict the noise residual
|
| 510 |
+
added_cond_kwargs = {"text_embeds": concat_add_text_embeds, "time_ids": concat_add_time_ids}
|
| 511 |
+
|
| 512 |
+
concat_noise_pred = self.unet(
|
| 513 |
+
concat_latent_model_input,
|
| 514 |
+
t,
|
| 515 |
+
encoder_hidden_states = concat_prompt_embeds,
|
| 516 |
+
timestep_cond = timestep_cond,
|
| 517 |
+
cross_attention_kwargs = self.cross_attention_kwargs,
|
| 518 |
+
added_cond_kwargs = added_cond_kwargs,
|
| 519 |
+
).sample
|
| 520 |
+
all_noise_pred = batch_tensor_to_dict(concat_noise_pred, batch_order)
|
| 521 |
+
|
| 522 |
+
# Classifier-free guidance, TODO: Support no CFG
|
| 523 |
+
noise_pred = all_noise_pred["uncond"] +\
|
| 524 |
+
self.guidance_scale * (all_noise_pred["cond"] - all_noise_pred["uncond"])
|
| 525 |
+
|
| 526 |
+
structure_noise_pred = all_noise_pred["structure_cond"]\
|
| 527 |
+
if "structure_cond" in batch_order else noise_pred
|
| 528 |
+
if "structure_uncond" in all_noise_pred:
|
| 529 |
+
structure_noise_pred = all_noise_pred["structure_uncond"] +\
|
| 530 |
+
self.structure_guidance_scale * (structure_noise_pred - all_noise_pred["structure_uncond"])
|
| 531 |
+
|
| 532 |
+
appearance_noise_pred = all_noise_pred["appearance_cond"]\
|
| 533 |
+
if "appearance_cond" in batch_order else noise_pred
|
| 534 |
+
if "appearance_uncond" in all_noise_pred:
|
| 535 |
+
appearance_noise_pred = all_noise_pred["appearance_uncond"] +\
|
| 536 |
+
self.appearance_guidance_scale * (appearance_noise_pred - all_noise_pred["appearance_uncond"])
|
| 537 |
+
|
| 538 |
+
if self.guidance_rescale > 0.0:
|
| 539 |
+
noise_pred = rescale_noise_cfg(
|
| 540 |
+
noise_pred, all_noise_pred["cond"], guidance_rescale=self.guidance_rescale
|
| 541 |
+
)
|
| 542 |
+
if "structure_uncond" in all_noise_pred:
|
| 543 |
+
structure_noise_pred = rescale_noise_cfg(
|
| 544 |
+
structure_noise_pred, all_noise_pred["structure_cond"],
|
| 545 |
+
guidance_rescale=self.guidance_rescale
|
| 546 |
+
)
|
| 547 |
+
if "appearance_uncond" in all_noise_pred:
|
| 548 |
+
appearance_noise_pred = rescale_noise_cfg(
|
| 549 |
+
appearance_noise_pred, all_noise_pred["appearance_cond"],
|
| 550 |
+
guidance_rescale=self.guidance_rescale
|
| 551 |
+
)
|
| 552 |
+
|
| 553 |
+
# Compute the previous noisy sample x_t -> x_t-1
|
| 554 |
+
concat_noise_pred = torch.cat(
|
| 555 |
+
[structure_noise_pred, appearance_noise_pred, noise_pred], dim=0,
|
| 556 |
+
)
|
| 557 |
+
concat_latents = torch.cat(
|
| 558 |
+
[structure_latents, appearance_latents, latents], dim=0,
|
| 559 |
+
)
|
| 560 |
+
structure_latents, appearance_latents, latents = self.scheduler.step(
|
| 561 |
+
concat_noise_pred, t, concat_latents, **extra_step_kwargs,
|
| 562 |
+
).prev_sample.chunk(3)
|
| 563 |
+
|
| 564 |
+
if clean_structure_latents is not None:
|
| 565 |
+
structure_latents = noise_prev(self.scheduler, t, clean_structure_latents)
|
| 566 |
+
if clean_appearance_latents is not None:
|
| 567 |
+
appearance_latents = noise_prev(self.scheduler, t, clean_appearance_latents)
|
| 568 |
+
|
| 569 |
+
# Self-recurrence
|
| 570 |
+
for _ in range(self_recurrence_schedule[i]):
|
| 571 |
+
if hasattr(self.scheduler, "_step_index"): # For fancier schedulers
|
| 572 |
+
self.scheduler._step_index -= 1 # TODO: Does this actually work?
|
| 573 |
+
|
| 574 |
+
t_prev = 0 if i + 1 >= num_inference_steps else timesteps[i + 1]
|
| 575 |
+
latents = noise_t2t(self.scheduler, t_prev, t, latents)
|
| 576 |
+
latent_model_input = torch.cat([latents] * 2)
|
| 577 |
+
|
| 578 |
+
register_attr(self, t=t.item(), do_control=False, batch_order=["uncond", "cond"])
|
| 579 |
+
|
| 580 |
+
# Predict the noise residual
|
| 581 |
+
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
|
| 582 |
+
noise_pred_uncond, noise_pred_ = self.unet(
|
| 583 |
+
latent_model_input,
|
| 584 |
+
t,
|
| 585 |
+
encoder_hidden_states = prompt_embeds,
|
| 586 |
+
timestep_cond = timestep_cond,
|
| 587 |
+
cross_attention_kwargs = self.cross_attention_kwargs,
|
| 588 |
+
added_cond_kwargs = added_cond_kwargs,
|
| 589 |
+
).sample.chunk(2)
|
| 590 |
+
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_ - noise_pred_uncond)
|
| 591 |
+
|
| 592 |
+
if self.guidance_rescale > 0.0:
|
| 593 |
+
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_, guidance_rescale=self.guidance_rescale)
|
| 594 |
+
|
| 595 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
| 596 |
+
|
| 597 |
+
# Callbacks
|
| 598 |
+
if callback_on_step_end is not None:
|
| 599 |
+
callback_kwargs = {}
|
| 600 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 601 |
+
callback_kwargs[k] = locals()[k]
|
| 602 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 603 |
+
|
| 604 |
+
latents = callback_outputs.pop("latents", latents)
|
| 605 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 606 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 607 |
+
add_text_embeds = callback_outputs.pop("add_text_embeds", add_text_embeds)
|
| 608 |
+
negative_pooled_prompt_embeds = callback_outputs.pop(
|
| 609 |
+
"negative_pooled_prompt_embeds", negative_pooled_prompt_embeds
|
| 610 |
+
)
|
| 611 |
+
add_time_ids = callback_outputs.pop("add_time_ids", add_time_ids)
|
| 612 |
+
add_neg_time_ids = callback_outputs.pop("add_neg_time_ids", add_neg_time_ids)
|
| 613 |
+
|
| 614 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 615 |
+
progress_bar.update()
|
| 616 |
+
if callback is not None and i % callback_steps == 0:
|
| 617 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 618 |
+
callback(step_idx, t, latents)
|
| 619 |
+
|
| 620 |
+
# "Reconstruction"
|
| 621 |
+
if clean_structure_latents is not None:
|
| 622 |
+
structure_latents = clean_structure_latents
|
| 623 |
+
if clean_appearance_latents is not None:
|
| 624 |
+
appearance_latents = clean_appearance_latents
|
| 625 |
+
|
| 626 |
+
# For passing important information onto the refiner
|
| 627 |
+
self.refiner_args = {"latents": latents.detach(), "prompt": prompt, "negative_prompt": negative_prompt}
|
| 628 |
+
|
| 629 |
+
if not output_type == "latent":
|
| 630 |
+
# Make sure the VAE is in float32 mode, as it overflows in float16
|
| 631 |
+
if self.vae.config.force_upcast:
|
| 632 |
+
self.vae.to(torch.float32) # self.upcast_vae() is buggy
|
| 633 |
+
latents = latents.to(torch.float32)
|
| 634 |
+
structure_latents = structure_latents.to(torch.float32)
|
| 635 |
+
appearance_latents = appearance_latents.to(torch.float32)
|
| 636 |
+
|
| 637 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 638 |
+
image = self.image_processor.postprocess(image, output_type=output_type)
|
| 639 |
+
if decode_structure:
|
| 640 |
+
structure = self.vae.decode(structure_latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 641 |
+
structure = self.image_processor.postprocess(structure, output_type=output_type)
|
| 642 |
+
else:
|
| 643 |
+
structure = structure_latents
|
| 644 |
+
if decode_appearance:
|
| 645 |
+
appearance = self.vae.decode(appearance_latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 646 |
+
appearance = self.image_processor.postprocess(appearance, output_type=output_type)
|
| 647 |
+
else:
|
| 648 |
+
appearance = appearance_latents
|
| 649 |
+
|
| 650 |
+
# Cast back to fp16 if needed
|
| 651 |
+
if self.vae.config.force_upcast:
|
| 652 |
+
self.vae.to(dtype=torch.float16)
|
| 653 |
+
|
| 654 |
+
else:
|
| 655 |
+
return CtrlXStableDiffusionXLPipelineOutput(
|
| 656 |
+
images=latents, structures=structure_latents, appearances=appearance_latents
|
| 657 |
+
)
|
| 658 |
+
|
| 659 |
+
# Offload all models
|
| 660 |
+
self.maybe_free_model_hooks()
|
| 661 |
+
|
| 662 |
+
if not return_dict:
|
| 663 |
+
return (image, structure, appearance)
|
| 664 |
+
|
| 665 |
+
return CtrlXStableDiffusionXLPipelineOutput(images=image, structures=structure, appearances=appearance)
|
ctrl_x/utils/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .feature import *
|
| 2 |
+
from .media import *
|
| 3 |
+
from .utils import *
|
ctrl_x/utils/feature.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from .utils import *
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_schedule(timesteps, schedule):
|
| 9 |
+
end = round(len(timesteps) * schedule)
|
| 10 |
+
timesteps = timesteps[:end]
|
| 11 |
+
return timesteps
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_elem(l, i, default=0.0):
|
| 15 |
+
if i >= len(l):
|
| 16 |
+
return default
|
| 17 |
+
return l[i]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def pad_list(l_1, l_2, pad=0.0):
|
| 21 |
+
max_len = max(len(l_1), len(l_2))
|
| 22 |
+
l_1 = l_1 + [pad] * (max_len - len(l_1))
|
| 23 |
+
l_2 = l_2 + [pad] * (max_len - len(l_2))
|
| 24 |
+
return l_1, l_2
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def normalize(x, dim):
|
| 28 |
+
x_mean = x.mean(dim=dim, keepdim=True)
|
| 29 |
+
x_std = x.std(dim=dim, keepdim=True)
|
| 30 |
+
x_normalized = (x - x_mean) / x_std
|
| 31 |
+
return x_normalized
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html
|
| 35 |
+
def appearance_mean_std(q_c_normed, k_s_normed, v_s): # c: content, s: style
|
| 36 |
+
q_c = q_c_normed # q_c and k_s must be projected from normalized features
|
| 37 |
+
k_s = k_s_normed
|
| 38 |
+
scale_factor = 1 / math.sqrt(q_c.shape[-1])
|
| 39 |
+
|
| 40 |
+
# My notation below is very jank: D = (H W) is number of tokens, and C is token dimension
|
| 41 |
+
# Horrible notation coming from how self-attention dimensions work in Stable Diffusion
|
| 42 |
+
A = q_c @ k_s.mT # (B H D C/H) (B H C/H D)^T -> (B H D D)
|
| 43 |
+
A = F.softmax(A * scale_factor, dim=-1) # Softmax on last D in (B H D D)
|
| 44 |
+
mean = A @ v_s # (B H D D) (B H D C/H) -> (B H D C/H)
|
| 45 |
+
std = (A @ v_s.square() - mean.square()).relu().sqrt()
|
| 46 |
+
|
| 47 |
+
return mean, std
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def feature_injection(features, batch_order):
|
| 51 |
+
assert features.shape[0] % len(batch_order) == 0
|
| 52 |
+
features_dict = batch_tensor_to_dict(features, batch_order)
|
| 53 |
+
features_dict["cond"] = features_dict["structure_cond"]
|
| 54 |
+
features = batch_dict_to_tensor(features_dict, batch_order)
|
| 55 |
+
return features
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def appearance_transfer(features, q_normed, k_normed, batch_order, v=None, reshape_fn=None):
|
| 59 |
+
assert features.shape[0] % len(batch_order) == 0
|
| 60 |
+
|
| 61 |
+
features_dict = batch_tensor_to_dict(features, batch_order)
|
| 62 |
+
q_normed_dict = batch_tensor_to_dict(q_normed, batch_order)
|
| 63 |
+
k_normed_dict = batch_tensor_to_dict(k_normed, batch_order)
|
| 64 |
+
v_dict = features_dict
|
| 65 |
+
if v is not None:
|
| 66 |
+
v_dict = batch_tensor_to_dict(v, batch_order)
|
| 67 |
+
|
| 68 |
+
mean_cond, std_cond = appearance_mean_std(
|
| 69 |
+
q_normed_dict["cond"], k_normed_dict["appearance_cond"], v_dict["appearance_cond"],
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if reshape_fn is not None:
|
| 73 |
+
mean_cond = reshape_fn(mean_cond)
|
| 74 |
+
std_cond = reshape_fn(std_cond)
|
| 75 |
+
|
| 76 |
+
features_dict["cond"] = std_cond * normalize(features_dict["cond"], dim=-2) + mean_cond
|
| 77 |
+
|
| 78 |
+
features = batch_dict_to_tensor(features_dict, batch_order)
|
| 79 |
+
return features
|
ctrl_x/utils/media.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torchvision.transforms.functional as vF
|
| 4 |
+
import PIL
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
JPEG_QUALITY = 95
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def preprocess(image, processor, **kwargs):
|
| 11 |
+
if isinstance(image, PIL.Image.Image):
|
| 12 |
+
pass
|
| 13 |
+
elif isinstance(image, np.ndarray):
|
| 14 |
+
image = PIL.Image.fromarray(image)
|
| 15 |
+
elif isinstance(image, torch.Tensor):
|
| 16 |
+
image = vF.to_pil_image(image)
|
| 17 |
+
else:
|
| 18 |
+
raise TypeError(f"Image must be of type PIL.Image, np.ndarray, or torch.Tensor, got {type(image)} instead.")
|
| 19 |
+
|
| 20 |
+
image = processor.preprocess(image, **kwargs)
|
| 21 |
+
return image
|
ctrl_x/utils/sdxl.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from types import MethodType
|
| 2 |
+
from typing import Optional
|
| 3 |
+
|
| 4 |
+
from diffusers.models.attention_processor import Attention
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .feature import *
|
| 9 |
+
from .utils import *
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def convolution_forward( # From <class 'diffusers.models.resnet.ResnetBlock2D'>, forward (diffusers==0.28.0)
|
| 13 |
+
self,
|
| 14 |
+
input_tensor: torch.Tensor,
|
| 15 |
+
temb: torch.Tensor,
|
| 16 |
+
*args,
|
| 17 |
+
**kwargs,
|
| 18 |
+
) -> torch.Tensor:
|
| 19 |
+
do_structure_control = self.do_control and self.t in self.structure_schedule
|
| 20 |
+
|
| 21 |
+
hidden_states = input_tensor
|
| 22 |
+
|
| 23 |
+
hidden_states = self.norm1(hidden_states)
|
| 24 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 25 |
+
|
| 26 |
+
if self.upsample is not None:
|
| 27 |
+
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
|
| 28 |
+
if hidden_states.shape[0] >= 64:
|
| 29 |
+
input_tensor = input_tensor.contiguous()
|
| 30 |
+
hidden_states = hidden_states.contiguous()
|
| 31 |
+
input_tensor = self.upsample(input_tensor)
|
| 32 |
+
hidden_states = self.upsample(hidden_states)
|
| 33 |
+
elif self.downsample is not None:
|
| 34 |
+
input_tensor = self.downsample(input_tensor)
|
| 35 |
+
hidden_states = self.downsample(hidden_states)
|
| 36 |
+
|
| 37 |
+
hidden_states = self.conv1(hidden_states)
|
| 38 |
+
|
| 39 |
+
if self.time_emb_proj is not None:
|
| 40 |
+
if not self.skip_time_act:
|
| 41 |
+
temb = self.nonlinearity(temb)
|
| 42 |
+
temb = self.time_emb_proj(temb)[:, :, None, None]
|
| 43 |
+
|
| 44 |
+
if self.time_embedding_norm == "default":
|
| 45 |
+
if temb is not None:
|
| 46 |
+
hidden_states = hidden_states + temb
|
| 47 |
+
hidden_states = self.norm2(hidden_states)
|
| 48 |
+
elif self.time_embedding_norm == "scale_shift":
|
| 49 |
+
if temb is None:
|
| 50 |
+
raise ValueError(
|
| 51 |
+
f" `temb` should not be None when `time_embedding_norm` is {self.time_embedding_norm}"
|
| 52 |
+
)
|
| 53 |
+
time_scale, time_shift = torch.chunk(temb, 2, dim=1)
|
| 54 |
+
hidden_states = self.norm2(hidden_states)
|
| 55 |
+
hidden_states = hidden_states * (1 + time_scale) + time_shift
|
| 56 |
+
else:
|
| 57 |
+
hidden_states = self.norm2(hidden_states)
|
| 58 |
+
|
| 59 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 60 |
+
|
| 61 |
+
hidden_states = self.dropout(hidden_states)
|
| 62 |
+
hidden_states = self.conv2(hidden_states)
|
| 63 |
+
|
| 64 |
+
# Feature injection and AdaIN (hidden_states)
|
| 65 |
+
if do_structure_control and "hidden_states" in self.structure_target:
|
| 66 |
+
hidden_states = feature_injection(hidden_states, batch_order=self.batch_order)
|
| 67 |
+
|
| 68 |
+
if self.conv_shortcut is not None:
|
| 69 |
+
input_tensor = self.conv_shortcut(input_tensor)
|
| 70 |
+
|
| 71 |
+
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
|
| 72 |
+
|
| 73 |
+
# Feature injection and AdaIN (output_tensor)
|
| 74 |
+
if do_structure_control and "output_tensor" in self.structure_target:
|
| 75 |
+
output_tensor = feature_injection(output_tensor, batch_order=self.batch_order)
|
| 76 |
+
|
| 77 |
+
return output_tensor
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class AttnProcessor2_0: # From <class 'diffusers.models.attention_processor.AttnProcessor2_0'> (diffusers==0.28.0)
|
| 81 |
+
|
| 82 |
+
def __init__(self):
|
| 83 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 84 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 85 |
+
|
| 86 |
+
def __call__(
|
| 87 |
+
self,
|
| 88 |
+
attn: Attention,
|
| 89 |
+
hidden_states: torch.FloatTensor,
|
| 90 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 91 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 92 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 93 |
+
*args,
|
| 94 |
+
**kwargs,
|
| 95 |
+
) -> torch.FloatTensor:
|
| 96 |
+
do_structure_control = attn.do_control and attn.t in attn.structure_schedule
|
| 97 |
+
do_appearance_control = attn.do_control and attn.t in attn.appearance_schedule
|
| 98 |
+
|
| 99 |
+
residual = hidden_states
|
| 100 |
+
if attn.spatial_norm is not None:
|
| 101 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 102 |
+
|
| 103 |
+
input_ndim = hidden_states.ndim
|
| 104 |
+
|
| 105 |
+
if input_ndim == 4:
|
| 106 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 107 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 108 |
+
|
| 109 |
+
batch_size, sequence_length, _ = (
|
| 110 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
if attention_mask is not None:
|
| 114 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 115 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 116 |
+
# (batch, heads, source_length, target_length)
|
| 117 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 118 |
+
|
| 119 |
+
if attn.group_norm is not None:
|
| 120 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 121 |
+
|
| 122 |
+
no_encoder_hidden_states = encoder_hidden_states is None
|
| 123 |
+
if no_encoder_hidden_states:
|
| 124 |
+
encoder_hidden_states = hidden_states
|
| 125 |
+
elif attn.norm_cross:
|
| 126 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 127 |
+
|
| 128 |
+
if do_appearance_control: # Assume we only have this for self attention
|
| 129 |
+
hidden_states_normed = normalize(hidden_states, dim=-2) # B H D C
|
| 130 |
+
encoder_hidden_states_normed = normalize(encoder_hidden_states, dim=-2)
|
| 131 |
+
|
| 132 |
+
query_normed = attn.to_q(hidden_states_normed)
|
| 133 |
+
key_normed = attn.to_k(encoder_hidden_states_normed)
|
| 134 |
+
|
| 135 |
+
inner_dim = key_normed.shape[-1]
|
| 136 |
+
head_dim = inner_dim // attn.heads
|
| 137 |
+
query_normed = query_normed.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 138 |
+
key_normed = key_normed.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 139 |
+
|
| 140 |
+
# Match query and key injection with structure injection (if injection is happening this layer)
|
| 141 |
+
if do_structure_control:
|
| 142 |
+
if "query" in attn.structure_target:
|
| 143 |
+
query_normed = feature_injection(query_normed, batch_order=attn.batch_order)
|
| 144 |
+
if "key" in attn.structure_target:
|
| 145 |
+
key_normed = feature_injection(key_normed, batch_order=attn.batch_order)
|
| 146 |
+
|
| 147 |
+
# Appearance transfer (before)
|
| 148 |
+
if do_appearance_control and "before" in attn.appearance_target:
|
| 149 |
+
hidden_states = hidden_states.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 150 |
+
hidden_states = appearance_transfer(hidden_states, query_normed, key_normed, batch_order=attn.batch_order)
|
| 151 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 152 |
+
|
| 153 |
+
if no_encoder_hidden_states:
|
| 154 |
+
encoder_hidden_states = hidden_states
|
| 155 |
+
elif attn.norm_cross:
|
| 156 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 157 |
+
|
| 158 |
+
query = attn.to_q(hidden_states)
|
| 159 |
+
|
| 160 |
+
key = attn.to_k(encoder_hidden_states)
|
| 161 |
+
value = attn.to_v(encoder_hidden_states)
|
| 162 |
+
|
| 163 |
+
inner_dim = key.shape[-1]
|
| 164 |
+
head_dim = inner_dim // attn.heads
|
| 165 |
+
|
| 166 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 167 |
+
|
| 168 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 169 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 170 |
+
|
| 171 |
+
# Feature injection (query, key, and/or value)
|
| 172 |
+
if do_structure_control:
|
| 173 |
+
if "query" in attn.structure_target:
|
| 174 |
+
query = feature_injection(query, batch_order=attn.batch_order)
|
| 175 |
+
if "key" in attn.structure_target:
|
| 176 |
+
key = feature_injection(key, batch_order=attn.batch_order)
|
| 177 |
+
if "value" in attn.structure_target:
|
| 178 |
+
value = feature_injection(value, batch_order=attn.batch_order)
|
| 179 |
+
|
| 180 |
+
# Appearance transfer (value)
|
| 181 |
+
if do_appearance_control and "value" in attn.appearance_target:
|
| 182 |
+
value = appearance_transfer(value, query_normed, key_normed, batch_order=attn.batch_order)
|
| 183 |
+
|
| 184 |
+
# The output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 185 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 186 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 187 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
# Appearance transfer (after)
|
| 191 |
+
if do_appearance_control and "after" in attn.appearance_target:
|
| 192 |
+
hidden_states = appearance_transfer(hidden_states, query_normed, key_normed, batch_order=attn.batch_order)
|
| 193 |
+
|
| 194 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 195 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 196 |
+
|
| 197 |
+
# Linear projection
|
| 198 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 199 |
+
# Dropout
|
| 200 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 201 |
+
|
| 202 |
+
if input_ndim == 4:
|
| 203 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 204 |
+
|
| 205 |
+
if attn.residual_connection:
|
| 206 |
+
hidden_states = hidden_states + residual
|
| 207 |
+
|
| 208 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 209 |
+
|
| 210 |
+
return hidden_states
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def register_control(
|
| 214 |
+
model,
|
| 215 |
+
timesteps,
|
| 216 |
+
control_schedule, # structure_conv, structure_attn, appearance_attn
|
| 217 |
+
control_target = [["output_tensor"], ["query", "key"], ["before"]],
|
| 218 |
+
):
|
| 219 |
+
# Assume timesteps in reverse order (T -> 0)
|
| 220 |
+
for block_type in ["encoder", "decoder", "middle"]:
|
| 221 |
+
blocks = {
|
| 222 |
+
"encoder": model.unet.down_blocks,
|
| 223 |
+
"decoder": model.unet.up_blocks,
|
| 224 |
+
"middle": [model.unet.mid_block],
|
| 225 |
+
}[block_type]
|
| 226 |
+
|
| 227 |
+
control_schedule_block = control_schedule[block_type]
|
| 228 |
+
if block_type == "middle":
|
| 229 |
+
control_schedule_block = [control_schedule_block]
|
| 230 |
+
|
| 231 |
+
for layer in range(len(control_schedule_block)):
|
| 232 |
+
# Convolution
|
| 233 |
+
num_blocks = len(blocks[layer].resnets) if hasattr(blocks[layer], "resnets") else 0
|
| 234 |
+
for block in range(num_blocks):
|
| 235 |
+
convolution = blocks[layer].resnets[block]
|
| 236 |
+
convolution.structure_target = control_target[0]
|
| 237 |
+
convolution.structure_schedule = get_schedule(
|
| 238 |
+
timesteps, get_elem(control_schedule_block[layer][0], block)
|
| 239 |
+
)
|
| 240 |
+
convolution.forward = MethodType(convolution_forward, convolution)
|
| 241 |
+
|
| 242 |
+
# Self-attention
|
| 243 |
+
num_blocks = len(blocks[layer].attentions) if hasattr(blocks[layer], "attentions") else 0
|
| 244 |
+
for block in range(num_blocks):
|
| 245 |
+
for transformer_block in blocks[layer].attentions[block].transformer_blocks:
|
| 246 |
+
attention = transformer_block.attn1
|
| 247 |
+
attention.structure_target = control_target[1]
|
| 248 |
+
attention.structure_schedule = get_schedule(
|
| 249 |
+
timesteps, get_elem(control_schedule_block[layer][1], block)
|
| 250 |
+
)
|
| 251 |
+
attention.appearance_target = control_target[2]
|
| 252 |
+
attention.appearance_schedule = get_schedule(
|
| 253 |
+
timesteps, get_elem(control_schedule_block[layer][2], block)
|
| 254 |
+
)
|
| 255 |
+
attention.processor = AttnProcessor2_0()
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def register_attr(model, t, do_control, batch_order):
|
| 259 |
+
for layer_type in ["encoder", "decoder", "middle"]:
|
| 260 |
+
blocks = {"encoder": model.unet.down_blocks, "decoder": model.unet.up_blocks,
|
| 261 |
+
"middle": [model.unet.mid_block]}[layer_type]
|
| 262 |
+
for layer in blocks:
|
| 263 |
+
# Convolution
|
| 264 |
+
for module in layer.resnets:
|
| 265 |
+
module.t = t
|
| 266 |
+
module.do_control = do_control
|
| 267 |
+
module.batch_order = batch_order
|
| 268 |
+
# Self-attention
|
| 269 |
+
if hasattr(layer, "attentions"):
|
| 270 |
+
for block in layer.attentions:
|
| 271 |
+
for module in block.transformer_blocks:
|
| 272 |
+
module.attn1.t = t
|
| 273 |
+
module.attn1.do_control = do_control
|
| 274 |
+
module.attn1.batch_order = batch_order
|
ctrl_x/utils/utils.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
JPEG_QUALITY = 95
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def exists(x):
|
| 8 |
+
return x is not None
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get(x, default):
|
| 12 |
+
if exists(x):
|
| 13 |
+
return x
|
| 14 |
+
return default
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_self_recurrence_schedule(schedule, num_inference_steps):
|
| 18 |
+
self_recurrence_schedule = [0] * num_inference_steps
|
| 19 |
+
for schedule_current in reversed(schedule):
|
| 20 |
+
if schedule_current is None or len(schedule_current) == 0:
|
| 21 |
+
continue
|
| 22 |
+
[start, end, repeat] = schedule_current
|
| 23 |
+
start_i = round(num_inference_steps * start)
|
| 24 |
+
end_i = round(num_inference_steps * end)
|
| 25 |
+
for i in range(start_i, end_i):
|
| 26 |
+
self_recurrence_schedule[i] = repeat
|
| 27 |
+
return self_recurrence_schedule
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def batch_dict_to_tensor(batch_dict, batch_order):
|
| 31 |
+
batch_tensor = []
|
| 32 |
+
for batch_type in batch_order:
|
| 33 |
+
batch_tensor.append(batch_dict[batch_type])
|
| 34 |
+
batch_tensor = torch.cat(batch_tensor, dim=0)
|
| 35 |
+
return batch_tensor
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def batch_tensor_to_dict(batch_tensor, batch_order):
|
| 39 |
+
batch_tensor_chunk = batch_tensor.chunk(len(batch_order))
|
| 40 |
+
batch_dict = {}
|
| 41 |
+
for i, batch_type in enumerate(batch_order):
|
| 42 |
+
batch_dict[batch_type] = batch_tensor_chunk[i]
|
| 43 |
+
return batch_dict
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def noise_prev(scheduler, timestep, x_0, noise=None):
|
| 47 |
+
if scheduler.num_inference_steps is None:
|
| 48 |
+
raise ValueError(
|
| 49 |
+
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
if noise is None:
|
| 53 |
+
noise = torch.randn_like(x_0).to(x_0)
|
| 54 |
+
|
| 55 |
+
# From DDIMScheduler step function (hopefully this works)
|
| 56 |
+
timestep_i = (scheduler.timesteps == timestep).nonzero(as_tuple=True)[0][0].item()
|
| 57 |
+
if timestep_i + 1 >= scheduler.timesteps.shape[0]: # We are at t = 0 (ish)
|
| 58 |
+
return x_0
|
| 59 |
+
prev_timestep = scheduler.timesteps[timestep_i + 1:timestep_i + 2] # Make sure t is not 0-dim
|
| 60 |
+
|
| 61 |
+
x_t_prev = scheduler.add_noise(x_0, noise, prev_timestep)
|
| 62 |
+
return x_t_prev
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def noise_t2t(scheduler, timestep, timestep_target, x_t, noise=None):
|
| 66 |
+
assert timestep_target >= timestep
|
| 67 |
+
if noise is None:
|
| 68 |
+
noise = torch.randn_like(x_t).to(x_t)
|
| 69 |
+
|
| 70 |
+
alphas_cumprod = scheduler.alphas_cumprod.to(device=x_t.device, dtype=x_t.dtype)
|
| 71 |
+
|
| 72 |
+
timestep = timestep.to(torch.long)
|
| 73 |
+
timestep_target = timestep_target.to(torch.long)
|
| 74 |
+
|
| 75 |
+
alpha_prod_t = alphas_cumprod[timestep]
|
| 76 |
+
alpha_prod_tt = alphas_cumprod[timestep_target]
|
| 77 |
+
alpha_prod = alpha_prod_tt / alpha_prod_t
|
| 78 |
+
|
| 79 |
+
sqrt_alpha_prod = (alpha_prod ** 0.5).flatten()
|
| 80 |
+
while len(sqrt_alpha_prod.shape) < len(x_t.shape):
|
| 81 |
+
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
|
| 82 |
+
|
| 83 |
+
sqrt_one_minus_alpha_prod = ((1 - alpha_prod) ** 0.5).flatten()
|
| 84 |
+
while len(sqrt_one_minus_alpha_prod.shape) < len(x_t.shape):
|
| 85 |
+
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
|
| 86 |
+
|
| 87 |
+
x_tt = sqrt_alpha_prod * x_t + sqrt_one_minus_alpha_prod * noise
|
| 88 |
+
return x_tt
|
docs/assets/bootstrap.min.css
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
docs/assets/cross_image_attention.jpg
ADDED

|
Git LFS Details
|
docs/assets/ctrl-x.jpg
ADDED

|
Git LFS Details
|
docs/assets/font.css
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Homepage Font */
|
| 2 |
+
|
| 3 |
+
/* latin-ext */
|
| 4 |
+
@font-face {
|
| 5 |
+
font-family: 'Lato';
|
| 6 |
+
font-style: normal;
|
| 7 |
+
font-weight: 400;
|
| 8 |
+
src: local('Lato Regular'), local('Lato-Regular'), url(https://fonts.gstatic.com/s/lato/v16/S6uyw4BMUTPHjxAwXjeu.woff2) format('woff2');
|
| 9 |
+
unicode-range: U+0100-024F, U+0259, U+1E00-1EFF, U+2020, U+20A0-20AB, U+20AD-20CF, U+2113, U+2C60-2C7F, U+A720-A7FF;
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
/* latin */
|
| 13 |
+
@font-face {
|
| 14 |
+
font-family: 'Lato';
|
| 15 |
+
font-style: normal;
|
| 16 |
+
font-weight: 400;
|
| 17 |
+
src: local('Lato Regular'), local('Lato-Regular'), url(https://fonts.gstatic.com/s/lato/v16/S6uyw4BMUTPHjx4wXg.woff2) format('woff2');
|
| 18 |
+
unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02BB-02BC, U+02C6, U+02DA, U+02DC, U+2000-206F, U+2074, U+20AC, U+2122, U+2191, U+2193, U+2212, U+2215, U+FEFF, U+FFFD;
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
/* latin-ext */
|
| 22 |
+
@font-face {
|
| 23 |
+
font-family: 'Lato';
|
| 24 |
+
font-style: normal;
|
| 25 |
+
font-weight: 700;
|
| 26 |
+
src: local('Lato Bold'), local('Lato-Bold'), url(https://fonts.gstatic.com/s/lato/v16/S6u9w4BMUTPHh6UVSwaPGR_p.woff2) format('woff2');
|
| 27 |
+
unicode-range: U+0100-024F, U+0259, U+1E00-1EFF, U+2020, U+20A0-20AB, U+20AD-20CF, U+2113, U+2C60-2C7F, U+A720-A7FF;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
/* latin */
|
| 31 |
+
@font-face {
|
| 32 |
+
font-family: 'Lato';
|
| 33 |
+
font-style: normal;
|
| 34 |
+
font-weight: 700;
|
| 35 |
+
src: local('Lato Bold'), local('Lato-Bold'), url(https://fonts.gstatic.com/s/lato/v16/S6u9w4BMUTPHh6UVSwiPGQ.woff2) format('woff2');
|
| 36 |
+
unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02BB-02BC, U+02C6, U+02DA, U+02DC, U+2000-206F, U+2074, U+20AC, U+2122, U+2191, U+2193, U+2212, U+2215, U+FEFF, U+FFFD;
|
| 37 |
+
}
|
docs/assets/freecontrol.jpg
ADDED

|
Git LFS Details
|
docs/assets/genforce.png
ADDED

|
docs/assets/pipeline.jpg
ADDED
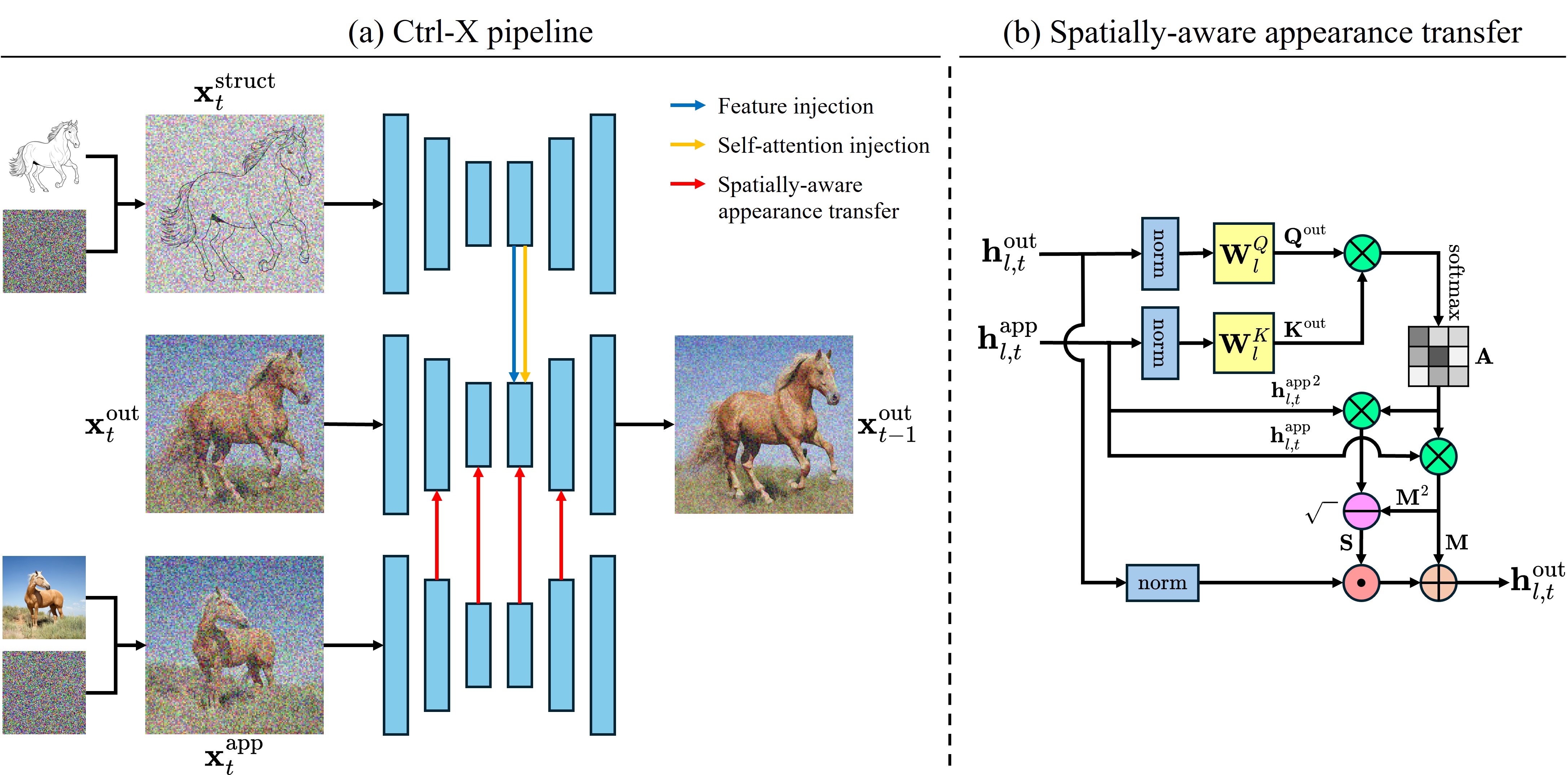
|
Git LFS Details
|
docs/assets/results_animatediff.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:43e29629924da2f368048016b2bb4ee973d0d38dc6f868098b0d9fbd6ac2e8ea
|
| 3 |
+
size 20573323
|
docs/assets/results_multi_subject.jpg
ADDED

|
Git LFS Details
|
docs/assets/results_struct+app.jpg
ADDED

|
Git LFS Details
|
docs/assets/results_struct+app_2.jpg
ADDED

|
Git LFS Details
|
docs/assets/results_struct+prompt.jpg
ADDED

|
Git LFS Details
|
docs/assets/style.css
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Body */
|
| 2 |
+
body {
|
| 3 |
+
background: #e3e5e8;
|
| 4 |
+
color: #ffffff;
|
| 5 |
+
font-family: 'Lato', Verdana, Helvetica, sans-serif;
|
| 6 |
+
font-weight: 300;
|
| 7 |
+
font-size: 14pt;
|
| 8 |
+
}
|
| 9 |
+
|
| 10 |
+
/* Hyperlinks */
|
| 11 |
+
a {text-decoration: none;}
|
| 12 |
+
a:link {color: #1772d0;}
|
| 13 |
+
a:visited {color: #1772d0;}
|
| 14 |
+
a:active {color: red;}
|
| 15 |
+
a:hover {color: #f09228;}
|
| 16 |
+
|
| 17 |
+
/* Pre-formatted Text */
|
| 18 |
+
pre {
|
| 19 |
+
margin: 5pt 0;
|
| 20 |
+
border: 0;
|
| 21 |
+
font-size: 12pt;
|
| 22 |
+
background: #fcfcfc;
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
/* Project Page Style */
|
| 26 |
+
/* Section */
|
| 27 |
+
.section {
|
| 28 |
+
width: 768pt;
|
| 29 |
+
min-height: 100pt;
|
| 30 |
+
margin: 15pt auto;
|
| 31 |
+
padding: 20pt 30pt;
|
| 32 |
+
border: 1pt hidden #000;
|
| 33 |
+
text-align: justify;
|
| 34 |
+
color: #000000;
|
| 35 |
+
background: #ffffff;
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
/* Header (Title and Logo) */
|
| 39 |
+
.section .header {
|
| 40 |
+
min-height: 80pt;
|
| 41 |
+
margin-top: 30pt;
|
| 42 |
+
}
|
| 43 |
+
.section .header .logo {
|
| 44 |
+
width: 80pt;
|
| 45 |
+
margin-left: 10pt;
|
| 46 |
+
float: left;
|
| 47 |
+
}
|
| 48 |
+
.section .header .logo img {
|
| 49 |
+
width: 80pt;
|
| 50 |
+
object-fit: cover;
|
| 51 |
+
}
|
| 52 |
+
.section .header .title {
|
| 53 |
+
margin: 0 120pt;
|
| 54 |
+
text-align: center;
|
| 55 |
+
font-size: 22pt;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
/* Author */
|
| 59 |
+
.section .author {
|
| 60 |
+
margin: 5pt 0;
|
| 61 |
+
text-align: center;
|
| 62 |
+
font-size: 16pt;
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
/* Institution */
|
| 66 |
+
.section .institution {
|
| 67 |
+
margin: 5pt 0;
|
| 68 |
+
text-align: center;
|
| 69 |
+
font-size: 16pt;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
/* Note */
|
| 73 |
+
.section .note {
|
| 74 |
+
margin: 5pt 0;
|
| 75 |
+
text-align: center;
|
| 76 |
+
font-size: 12pt;
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
/* Hyperlink (such as Paper and Code) */
|
| 80 |
+
.section .link {
|
| 81 |
+
margin: 5pt 0;
|
| 82 |
+
text-align: center;
|
| 83 |
+
font-size: 16pt;
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
/* Teaser */
|
| 87 |
+
.section .teaser {
|
| 88 |
+
margin: 20pt 0;
|
| 89 |
+
text-align: center;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
/* Section Title */
|
| 93 |
+
.section .title {
|
| 94 |
+
text-align: center;
|
| 95 |
+
font-size: 22pt;
|
| 96 |
+
margin: 5pt 0 15pt 0; /* top right bottom left */
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
/* Section Body */
|
| 100 |
+
.section .body {
|
| 101 |
+
margin-bottom: 15pt;
|
| 102 |
+
text-align: justify;
|
| 103 |
+
font-size: 14pt;
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
/* BibTeX */
|
| 107 |
+
.section .bibtex {
|
| 108 |
+
margin: 5pt 0;
|
| 109 |
+
text-align: left;
|
| 110 |
+
font-size: 22pt;
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
/* Related Work */
|
| 114 |
+
.section .ref {
|
| 115 |
+
margin: 20pt 0 10pt 0; /* top right bottom left */
|
| 116 |
+
text-align: left;
|
| 117 |
+
font-size: 18pt;
|
| 118 |
+
font-weight: bold;
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
/* Citation */
|
| 122 |
+
.section .citation {
|
| 123 |
+
min-height: 60pt;
|
| 124 |
+
margin: 10pt 0;
|
| 125 |
+
}
|
| 126 |
+
.section .citation .image {
|
| 127 |
+
width: 120pt;
|
| 128 |
+
float: left;
|
| 129 |
+
}
|
| 130 |
+
.section .citation .image img {
|
| 131 |
+
max-height: 60pt;
|
| 132 |
+
width: 120pt;
|
| 133 |
+
object-fit: cover;
|
| 134 |
+
}
|
| 135 |
+
.section .citation .comment{
|
| 136 |
+
margin-left: 130pt;
|
| 137 |
+
text-align: left;
|
| 138 |
+
font-size: 14pt;
|
| 139 |
+
}
|
docs/assets/teaser_github.jpg
ADDED

|
Git LFS Details
|
docs/assets/teaser_small.jpg
ADDED

|
Git LFS Details
|
docs/index.html
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!doctype html>
|
| 2 |
+
<html lang="en">
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
<!-- === Header Starts === -->
|
| 6 |
+
<head>
|
| 7 |
+
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
|
| 8 |
+
|
| 9 |
+
<title>Ctrl-X</title>
|
| 10 |
+
|
| 11 |
+
<link href="./assets/bootstrap.min.css" rel="stylesheet">
|
| 12 |
+
<link href="./assets/font.css" rel="stylesheet" type="text/css">
|
| 13 |
+
<link href="./assets/style.css" rel="stylesheet" type="text/css">
|
| 14 |
+
</head>
|
| 15 |
+
<!-- === Header Ends === -->
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
<body>
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
<!-- === Home Section Starts === -->
|
| 22 |
+
<div class="section">
|
| 23 |
+
<!-- === Title Starts === -->
|
| 24 |
+
<div class="header">
|
| 25 |
+
<div class="logo">
|
| 26 |
+
<a href="https://genforce.github.io/" target="_blank"><img src="./assets/genforce.png"></a>
|
| 27 |
+
</div>
|
| 28 |
+
<div class="title", style="padding-top: 25pt;"> <!-- Set padding as 10 if title is with two lines. -->
|
| 29 |
+
Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance
|
| 30 |
+
</div>
|
| 31 |
+
</div>
|
| 32 |
+
<!-- === Title Ends === -->
|
| 33 |
+
<div class="author">
|
| 34 |
+
<a href="https://kuanhenglin.github.io" target="_blank">Kuan Heng Lin</a><sup>1</sup>*
|
| 35 |
+
<a href="https://sichengmo.github.io/" target="_blank">Sicheng Mo</a><sup>1</sup>*
|
| 36 |
+
<a href="https://bklingher.github.io" target="_blank">Ben Klingher</a><sup>1</sup>
|
| 37 |
+
<a href="https://pages.cs.wisc.edu/~fmu/" target="_blank">Fangzhou Mu</a><sup>2</sup>
|
| 38 |
+
<a href="https://boleizhou.github.io/" target="_blank">Bolei Zhou</a><sup>1</sup>
|
| 39 |
+
</div>
|
| 40 |
+
<div class="institution">
|
| 41 |
+
<sup>1</sup>UCLA
|
| 42 |
+
<sup>2</sup>NVIDIA
|
| 43 |
+
</div>
|
| 44 |
+
<div class="note">
|
| 45 |
+
*Equal contribution
|
| 46 |
+
</div>
|
| 47 |
+
<div class="title" style="font-size: 18pt;margin: 15pt 0 15pt 0">
|
| 48 |
+
NeurIPS 2024
|
| 49 |
+
</div>
|
| 50 |
+
<div class="link">
|
| 51 |
+
[<a href="https://arxiv.org/abs/2406.07540" target="_blank">Paper</a>]
|
| 52 |
+
[<a href="https://github.com/genforce/ctrl-x" target="_blank">Code</a>]
|
| 53 |
+
</div>
|
| 54 |
+
<div class="teaser">
|
| 55 |
+
<img src="assets/ctrl-x.jpg" width="85%">
|
| 56 |
+
</div>
|
| 57 |
+
</div>
|
| 58 |
+
<!-- === Home Section Ends === -->
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
<!-- === Overview Section Starts === -->
|
| 62 |
+
<div class="section">
|
| 63 |
+
<div class="title">Overview</div>
|
| 64 |
+
<div class="body">
|
| 65 |
+
We present <b>Ctrl-X</b>, a simple <i>training-free</i> and <i>guidance-free</i> framework for text-to-image (T2I) generation with structure and appearance control. Given user-provided structure and appearance images, Ctrl-X designs feedforward structure control to enable structure alignment with the structure image and semantic-aware appearance transfer to facilitate the appearance transfer from the appearance image. Ctrl-X supports novel structure control with arbitrary condition images of any modality, is significantly faster than prior training-free appearance transfer methods, and provides instant plug-and-play to any T2I and text-to-video (T2V) diffusion model.
|
| 66 |
+
<table width="100%" style="margin: 20pt 0; text-align: center;">
|
| 67 |
+
<tr>
|
| 68 |
+
<td><img src="assets/pipeline.jpg" width="85%"></td>
|
| 69 |
+
</tr>
|
| 70 |
+
</table>
|
| 71 |
+
|
| 72 |
+
<b>How does it work?</b> Given clean structure and appearance latents, we first obtain noised structure and appearance latents via the diffusion forward process, then extracting their U-Net features from a pretrained T2I diffusion model. When denoising the output latent, we inject convolution and self-attention features from the structure latent and leverage self-attention correspondence to transfer spatially-aware appearance statistics from the appearance latent to achieve structure and appearance control. We name our method "Ctrl-X" because we reformulate the controllable generation problem by 'cutting' (and 'pasting') structure preservation and semantic-aware stylization together.
|
| 73 |
+
</div>
|
| 74 |
+
</div>
|
| 75 |
+
<!-- === Overview Section Ends === -->
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
<!-- === Result Section Starts === -->
|
| 79 |
+
<div class="section">
|
| 80 |
+
<div class="title">Results: Structure and appearance control</div>
|
| 81 |
+
<div class="body">
|
| 82 |
+
Results of training-free and guidance-free T2I diffusion with structure and appearance control, where Ctrl-X supports a diverse variety of structure images, including natural images, ControlNet-supported conditions (e.g., canny maps, normal maps), and in-the-wild conditions (e.g., wireframes, 3D meshes). The base model here is <a href="https://arxiv.org/abs/2307.01952" target="_blank">Stable Diffusion XL v1.0</a>.
|
| 83 |
+
|
| 84 |
+
<!-- Adjust the number of rows and columns (EVERY project differs). -->
|
| 85 |
+
<table width="100%" style="margin: 20pt 0; text-align: center;">
|
| 86 |
+
<tr>
|
| 87 |
+
<td><img src="assets/results_struct+app.jpg" width="100%"></td>
|
| 88 |
+
</tr>
|
| 89 |
+
</table>
|
| 90 |
+
<table width="100%" style="margin: 20pt 0; text-align: center;">
|
| 91 |
+
<tr>
|
| 92 |
+
<td><img src="assets/results_struct+app_2.jpg" width="85%"></td>
|
| 93 |
+
</tr>
|
| 94 |
+
</table>
|
| 95 |
+
</div>
|
| 96 |
+
</div>
|
| 97 |
+
|
| 98 |
+
<div class="section">
|
| 99 |
+
<div class="title">Results: Multi-subject structure and appearance control</div>
|
| 100 |
+
<div class="body">
|
| 101 |
+
Ctrl-X is capable of multi-subject generation with semantic correspondence between appearance and structure images across both subjects and backgrounds. In comparison, <a href="https://arxiv.org/abs/2302.05543" target="_blank">ControlNet</a> + <a href="https://arxiv.org/abs/2308.06721" target="_blank">IP-Adapter</a> often fails at transferring all subject and background appearances.
|
| 102 |
+
|
| 103 |
+
<!-- Adjust the number of rows and columns (EVERY project differs). -->
|
| 104 |
+
<table width="100%" style="margin: 20pt 0; text-align: center;">
|
| 105 |
+
<tr>
|
| 106 |
+
<td><img src="assets/results_multi_subject.jpg" width="90%"></td>
|
| 107 |
+
</tr>
|
| 108 |
+
</table>
|
| 109 |
+
</div>
|
| 110 |
+
</div>
|
| 111 |
+
|
| 112 |
+
<div class="section">
|
| 113 |
+
<div class="title">Results: Prompt-driven conditional generation</div>
|
| 114 |
+
<div class="body">
|
| 115 |
+
Ctrl-X also supports prompt-driven conditional generation, where it generates an output image complying with the given text prompt while aligning with the structure of the structure image. Ctrl-X continues to support any structure image/condition type here as well. The base model here is <a href="https://arxiv.org/abs/2307.01952" target="_blank">Stable Diffusion XL v1.0</a>.
|
| 116 |
+
|
| 117 |
+
<!-- Adjust the number of rows and columns (EVERY project differs). -->
|
| 118 |
+
<table width="100%" style="margin: 20pt 0; text-align: center;">
|
| 119 |
+
<tr>
|
| 120 |
+
<td><img src="assets/results_struct+prompt.jpg" width="100%"></td>
|
| 121 |
+
</tr>
|
| 122 |
+
</table>
|
| 123 |
+
</div>
|
| 124 |
+
</div>
|
| 125 |
+
|
| 126 |
+
<div class="section">
|
| 127 |
+
<div class="title">Results: Extension to video generation</div>
|
| 128 |
+
<div class="body">
|
| 129 |
+
We can directly apply Ctrl-X to text-to-video (T2V) models. We show results of <a href="https://animatediff.github.io/" target="_blank">AnimateDiff v1.5.3</a> (with base model <a href="https://huggingface.co/SG161222/Realistic_Vision_V5.1_noVAE" target="_blank">Realistic Vision v5.1</a>) here.
|
| 130 |
+
|
| 131 |
+
<!-- Demo video here. Adjust the frame size based on the demo (EVERY project differs). -->
|
| 132 |
+
<div style="position: relative; padding-top: 50%; margin: 20pt 0; text-align: center;">
|
| 133 |
+
<iframe src="assets/results_animatediff.mp4" frameborder=0
|
| 134 |
+
style="position: absolute; top: 2.5%; left: 0%; width: 100%; height: 100%;"
|
| 135 |
+
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
|
| 136 |
+
allowfullscreen></iframe>
|
| 137 |
+
</div>
|
| 138 |
+
</div>
|
| 139 |
+
</div>
|
| 140 |
+
|
| 141 |
+
<!-- === Result Section Ends === -->
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
<!-- === Reference Section Starts === -->
|
| 145 |
+
<div class="section">
|
| 146 |
+
<div class="bibtex">BibTeX</div>
|
| 147 |
+
<pre>
|
| 148 |
+
@inproceedings{lin2024ctrlx,
|
| 149 |
+
author = {Lin, {Kuan Heng} and Mo, Sicheng and Klingher, Ben and Mu, Fangzhou and Zhou, Bolei},
|
| 150 |
+
booktitle = {Advances in Neural Information Processing Systems},
|
| 151 |
+
title = {Ctrl-X: Controlling Structure and Appearance for Text-To-Image Generation Without Guidance},
|
| 152 |
+
year = {2024}
|
| 153 |
+
}
|
| 154 |
+
</pre>
|
| 155 |
+
|
| 156 |
+
<!-- BZ: we should give other related work enough credits, -->
|
| 157 |
+
<!-- so please include some most relevant work and leave some comment to summarize work and the difference. -->
|
| 158 |
+
<div class="ref">Related Work</div>
|
| 159 |
+
<div class="citation">
|
| 160 |
+
<div class="image"><img src="assets/freecontrol.jpg"></div>
|
| 161 |
+
<div class="comment">
|
| 162 |
+
<a href="https://genforce.github.io/freecontrol/" target="_blank">
|
| 163 |
+
Sicheng Mo, Fangzhou Mu, Kuan Heng Lin, Yanli Liu, Bochen Guan, Yin Li, Bolei Zhou.
|
| 164 |
+
FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition.
|
| 165 |
+
CVPR 2024.</a><br>
|
| 166 |
+
<b>Comment:</b>
|
| 167 |
+
Training-free conditional generation by guidance in diffusion U-Net subspaces for structure control and appearance regularization.
|
| 168 |
+
</div>
|
| 169 |
+
</div>
|
| 170 |
+
<div class="citation">
|
| 171 |
+
<div class="image"><img src="assets/cross_image_attention.jpg"></div>
|
| 172 |
+
<div class="comment">
|
| 173 |
+
<a href="https://garibida.github.io/cross-image-attention/" target="_blank">
|
| 174 |
+
Yuval Alaluf, Daniel Garibi, Or Patashnik, Hadar Averbuch-Elor, Daniel Cohen-Or.
|
| 175 |
+
Cross-Image Attention for Zero-Shot Appearance Transfer.
|
| 176 |
+
SIGGRAPH 2024.</a><br>
|
| 177 |
+
<b>Comment:</b>
|
| 178 |
+
Guidance-free appearance transfer to natural images with self-attention key + value swaps via cross-image correspondence.
|
| 179 |
+
</div>
|
| 180 |
+
</div>
|
| 181 |
+
</div>
|
| 182 |
+
<!-- === Reference Section Ends === -->
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
</body>
|
| 186 |
+
</html>
|
environment.yaml
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ctrlx
|
| 2 |
+
channels:
|
| 3 |
+
- defaults
|
| 4 |
+
dependencies:
|
| 5 |
+
- _libgcc_mutex=0.1=main
|
| 6 |
+
- _openmp_mutex=5.1=1_gnu
|
| 7 |
+
- bzip2=1.0.8=h5eee18b_6
|
| 8 |
+
- ca-certificates=2024.3.11=h06a4308_0
|
| 9 |
+
- ld_impl_linux-64=2.38=h1181459_1
|
| 10 |
+
- libffi=3.4.4=h6a678d5_1
|
| 11 |
+
- libgcc-ng=11.2.0=h1234567_1
|
| 12 |
+
- libgomp=11.2.0=h1234567_1
|
| 13 |
+
- libstdcxx-ng=11.2.0=h1234567_1
|
| 14 |
+
- libuuid=1.41.5=h5eee18b_0
|
| 15 |
+
- ncurses=6.4=h6a678d5_0
|
| 16 |
+
- openssl=3.0.13=h7f8727e_2
|
| 17 |
+
- pip=24.0=py310h06a4308_0
|
| 18 |
+
- python=3.10.14=h955ad1f_1
|
| 19 |
+
- readline=8.2=h5eee18b_0
|
| 20 |
+
- setuptools=69.5.1=py310h06a4308_0
|
| 21 |
+
- sqlite=3.45.3=h5eee18b_0
|
| 22 |
+
- tk=8.6.14=h39e8969_0
|
| 23 |
+
- wheel=0.43.0=py310h06a4308_0
|
| 24 |
+
- xz=5.4.6=h5eee18b_1
|
| 25 |
+
- zlib=1.2.13=h5eee18b_1
|
| 26 |
+
- pip:
|
| 27 |
+
- aiofiles==23.2.1
|
| 28 |
+
- altair==5.3.0
|
| 29 |
+
- annotated-types==0.7.0
|
| 30 |
+
- anyio==4.4.0
|
| 31 |
+
- attrs==23.2.0
|
| 32 |
+
- certifi==2024.2.2
|
| 33 |
+
- charset-normalizer==3.3.2
|
| 34 |
+
- click==8.1.7
|
| 35 |
+
- contourpy==1.2.1
|
| 36 |
+
- cycler==0.12.1
|
| 37 |
+
- diffusers==0.28.0
|
| 38 |
+
- dnspython==2.6.1
|
| 39 |
+
- einops==0.8.0
|
| 40 |
+
- email-validator==2.1.1
|
| 41 |
+
- exceptiongroup==1.2.1
|
| 42 |
+
- fastapi==0.111.0
|
| 43 |
+
- fastapi-cli==0.0.4
|
| 44 |
+
- ffmpy==0.3.2
|
| 45 |
+
- filelock==3.14.0
|
| 46 |
+
- fonttools==4.52.4
|
| 47 |
+
- fsspec==2024.5.0
|
| 48 |
+
- gradio==4.31.5
|
| 49 |
+
- gradio-client==0.16.4
|
| 50 |
+
- h11==0.14.0
|
| 51 |
+
- httpcore==1.0.5
|
| 52 |
+
- httptools==0.6.1
|
| 53 |
+
- httpx==0.27.0
|
| 54 |
+
- huggingface-hub==0.23.2
|
| 55 |
+
- idna==3.7
|
| 56 |
+
- importlib-metadata==7.1.0
|
| 57 |
+
- importlib-resources==6.4.0
|
| 58 |
+
- jinja2==3.1.4
|
| 59 |
+
- jsonschema==4.22.0
|
| 60 |
+
- jsonschema-specifications==2023.12.1
|
| 61 |
+
- kiwisolver==1.4.5
|
| 62 |
+
- markdown-it-py==3.0.0
|
| 63 |
+
- markupsafe==2.1.5
|
| 64 |
+
- matplotlib==3.9.0
|
| 65 |
+
- mdurl==0.1.2
|
| 66 |
+
- mpmath==1.3.0
|
| 67 |
+
- networkx==3.3
|
| 68 |
+
- numpy==1.26.4
|
| 69 |
+
- nvidia-cublas-cu12==12.1.3.1
|
| 70 |
+
- nvidia-cuda-cupti-cu12==12.1.105
|
| 71 |
+
- nvidia-cuda-nvrtc-cu12==12.1.105
|
| 72 |
+
- nvidia-cuda-runtime-cu12==12.1.105
|
| 73 |
+
- nvidia-cudnn-cu12==8.9.2.26
|
| 74 |
+
- nvidia-cufft-cu12==11.0.2.54
|
| 75 |
+
- nvidia-curand-cu12==10.3.2.106
|
| 76 |
+
- nvidia-cusolver-cu12==11.4.5.107
|
| 77 |
+
- nvidia-cusparse-cu12==12.1.0.106
|
| 78 |
+
- nvidia-nccl-cu12==2.20.5
|
| 79 |
+
- nvidia-nvjitlink-cu12==12.5.40
|
| 80 |
+
- nvidia-nvtx-cu12==12.1.105
|
| 81 |
+
- orjson==3.10.3
|
| 82 |
+
- packaging==24.0
|
| 83 |
+
- pandas==2.2.2
|
| 84 |
+
- pillow==10.3.0
|
| 85 |
+
- pydantic==2.7.2
|
| 86 |
+
- pydantic-core==2.18.3
|
| 87 |
+
- pydub==0.25.1
|
| 88 |
+
- pygments==2.18.0
|
| 89 |
+
- pyparsing==3.1.2
|
| 90 |
+
- python-dateutil==2.9.0.post0
|
| 91 |
+
- python-dotenv==1.0.1
|
| 92 |
+
- python-multipart==0.0.9
|
| 93 |
+
- pytz==2024.1
|
| 94 |
+
- pyyaml==6.0.1
|
| 95 |
+
- referencing==0.35.1
|
| 96 |
+
- regex==2024.5.15
|
| 97 |
+
- requests==2.32.2
|
| 98 |
+
- rich==13.7.1
|
| 99 |
+
- rpds-py==0.18.1
|
| 100 |
+
- ruff==0.4.6
|
| 101 |
+
- safetensors==0.4.3
|
| 102 |
+
- semantic-version==2.10.0
|
| 103 |
+
- shellingham==1.5.4
|
| 104 |
+
- six==1.16.0
|
| 105 |
+
- sniffio==1.3.1
|
| 106 |
+
- starlette==0.37.2
|
| 107 |
+
- sympy==1.12
|
| 108 |
+
- tokenizers==0.19.1
|
| 109 |
+
- tomlkit==0.12.0
|
| 110 |
+
- toolz==0.12.1
|
| 111 |
+
- torch==2.3.0
|
| 112 |
+
- torchvision==0.18.0
|
| 113 |
+
- tqdm==4.66.4
|
| 114 |
+
- transformers==4.41.1
|
| 115 |
+
- triton==2.3.0
|
| 116 |
+
- typer==0.12.3
|
| 117 |
+
- typing-extensions==4.12.0
|
| 118 |
+
- tzdata==2024.1
|
| 119 |
+
- ujson==5.10.0
|
| 120 |
+
- urllib3==2.2.1
|
| 121 |
+
- uvicorn==0.30.0
|
| 122 |
+
- uvloop==0.19.0
|
| 123 |
+
- watchfiles==0.22.0
|
| 124 |
+
- websockets==11.0.3
|
| 125 |
+
- zipp==3.19.0
|