
abhai
#14
by
Abhai121
- opened
- README.md +18 -18
- tokenizer_config.json +1 -1
README.md
CHANGED
|
@@ -28,7 +28,7 @@ We are seeing strong performance in terms of both parameter efficiency and infer
|
|
| 28 |
|
| 29 |
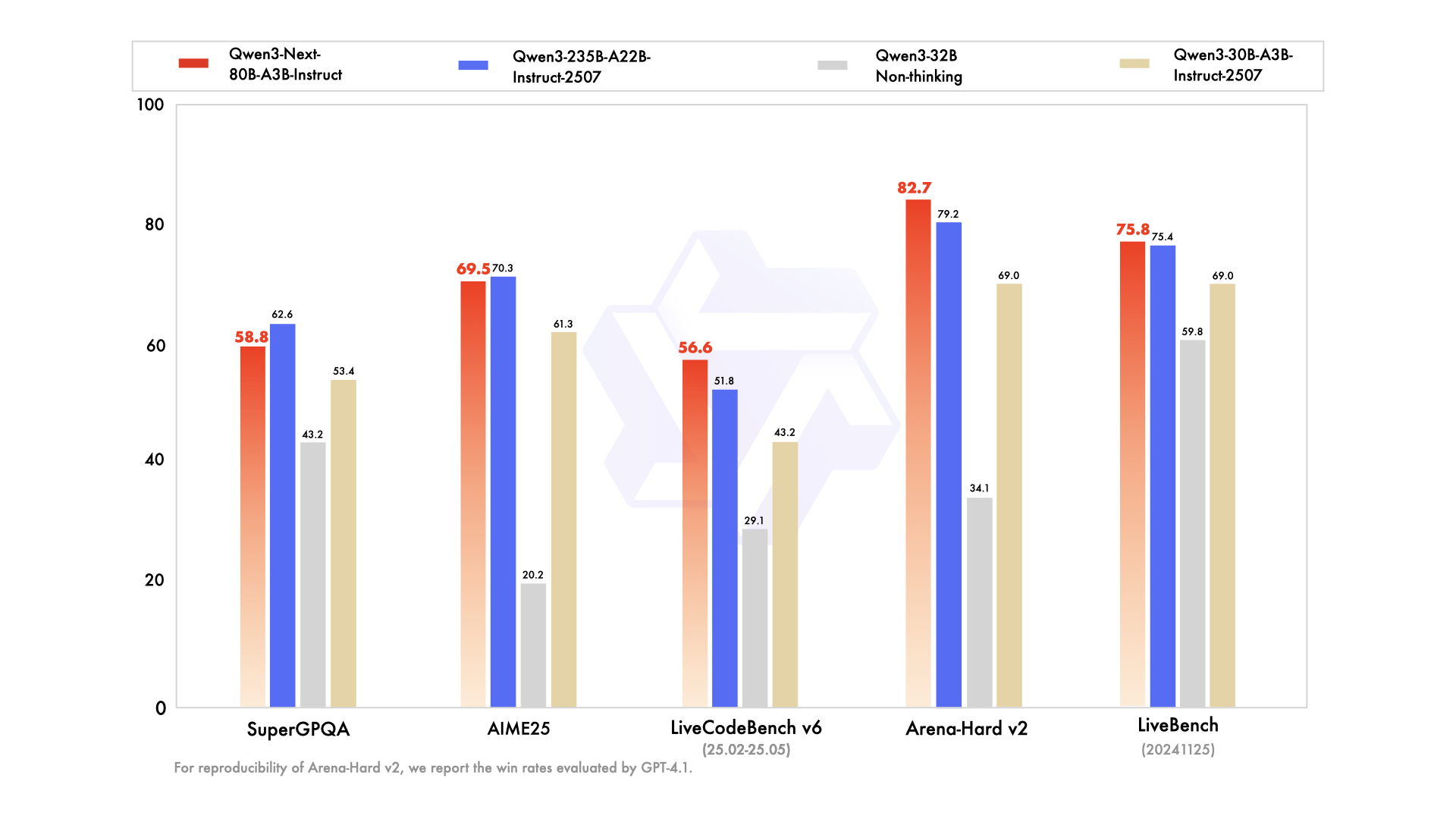
|
| 30 |
|
| 31 |
-
For more details, please refer to our blog post [Qwen3-Next](https://
|
| 32 |
|
| 33 |
## Model Overview
|
| 34 |
|
|
@@ -40,9 +40,9 @@ For more details, please refer to our blog post [Qwen3-Next](https://qwen.ai/blo
|
|
| 40 |
- Training Stage: Pretraining (15T tokens) & Post-training
|
| 41 |
- Number of Parameters: 80B in total and 3B activated
|
| 42 |
- Number of Paramaters (Non-Embedding): 79B
|
| 43 |
-
- Hidden Dimension: 2048
|
| 44 |
- Number of Layers: 48
|
| 45 |
-
|
|
|
|
| 46 |
- Gated Attention:
|
| 47 |
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 48 |
- Head Dimension: 256
|
|
@@ -157,7 +157,7 @@ print("content:", content)
|
|
| 157 |
|
| 158 |
> [!Tip]
|
| 159 |
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
|
| 160 |
-
> See the links for detailed instructions and requirements.
|
| 161 |
|
| 162 |
|
| 163 |
## Deployment
|
|
@@ -169,52 +169,52 @@ For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-co
|
|
| 169 |
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 170 |
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 171 |
|
| 172 |
-
|
| 173 |
```shell
|
| 174 |
-
pip install 'sglang[all]
|
| 175 |
```
|
| 176 |
-
See [its documentation](https://docs.sglang.ai/get_started/install.html) for more details.
|
| 177 |
|
| 178 |
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 179 |
```shell
|
| 180 |
-
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
|
| 181 |
```
|
| 182 |
|
| 183 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 184 |
```shell
|
| 185 |
-
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
|
| 186 |
```
|
| 187 |
|
| 188 |
> [!Note]
|
| 189 |
-
> The
|
| 190 |
|
| 191 |
-
|
|
|
|
| 192 |
|
| 193 |
### vLLM
|
| 194 |
|
| 195 |
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 196 |
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 197 |
|
| 198 |
-
|
| 199 |
```shell
|
| 200 |
-
pip install
|
| 201 |
```
|
| 202 |
-
See [its documentation](https://docs.vllm.ai/en/stable/getting_started/installation/index.html) for more details.
|
| 203 |
|
| 204 |
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 205 |
```shell
|
| 206 |
-
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
|
| 207 |
```
|
| 208 |
|
| 209 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 210 |
```shell
|
| 211 |
-
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
|
| 212 |
```
|
| 213 |
|
| 214 |
> [!Note]
|
| 215 |
-
> The
|
| 216 |
|
| 217 |
-
|
|
|
|
| 218 |
|
| 219 |
## Agentic Use
|
| 220 |
|
|
|
|
| 28 |
|
| 29 |

|
| 30 |
|
| 31 |
+
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
|
| 32 |
|
| 33 |
## Model Overview
|
| 34 |
|
|
|
|
| 40 |
- Training Stage: Pretraining (15T tokens) & Post-training
|
| 41 |
- Number of Parameters: 80B in total and 3B activated
|
| 42 |
- Number of Paramaters (Non-Embedding): 79B
|
|
|
|
| 43 |
- Number of Layers: 48
|
| 44 |
+
- Hidden Dimension: 2048
|
| 45 |
+
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
|
| 46 |
- Gated Attention:
|
| 47 |
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 48 |
- Head Dimension: 256
|
|
|
|
| 157 |
|
| 158 |
> [!Tip]
|
| 159 |
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
|
| 160 |
+
> See the above links for detailed instructions and requirements.
|
| 161 |
|
| 162 |
|
| 163 |
## Deployment
|
|
|
|
| 169 |
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 170 |
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 171 |
|
| 172 |
+
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
|
| 173 |
```shell
|
| 174 |
+
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
|
| 175 |
```
|
|
|
|
| 176 |
|
| 177 |
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 178 |
```shell
|
| 179 |
+
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
|
| 180 |
```
|
| 181 |
|
| 182 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 183 |
```shell
|
| 184 |
+
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
|
| 185 |
```
|
| 186 |
|
| 187 |
> [!Note]
|
| 188 |
+
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
|
| 189 |
|
| 190 |
+
> [!Note]
|
| 191 |
+
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
|
| 192 |
|
| 193 |
### vLLM
|
| 194 |
|
| 195 |
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 196 |
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 197 |
|
| 198 |
+
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
|
| 199 |
```shell
|
| 200 |
+
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
|
| 201 |
```
|
|
|
|
| 202 |
|
| 203 |
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 204 |
```shell
|
| 205 |
+
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
|
| 206 |
```
|
| 207 |
|
| 208 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 209 |
```shell
|
| 210 |
+
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
|
| 211 |
```
|
| 212 |
|
| 213 |
> [!Note]
|
| 214 |
+
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
|
| 215 |
|
| 216 |
+
> [!Note]
|
| 217 |
+
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
|
| 218 |
|
| 219 |
## Agentic Use
|
| 220 |
|
tokenizer_config.json
CHANGED
|
@@ -226,7 +226,7 @@
|
|
| 226 |
"<|video_pad|>"
|
| 227 |
],
|
| 228 |
"bos_token": null,
|
| 229 |
-
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}",
|
| 230 |
"clean_up_tokenization_spaces": false,
|
| 231 |
"eos_token": "<|im_end|>",
|
| 232 |
"errors": "replace",
|
|
|
|
| 226 |
"<|video_pad|>"
|
| 227 |
],
|
| 228 |
"bos_token": null,
|
| 229 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is string %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}",
|
| 230 |
"clean_up_tokenization_spaces": false,
|
| 231 |
"eos_token": "<|im_end|>",
|
| 232 |
"errors": "replace",
|