
{kind=link}
Most of my models - in order
Collection
31 items
•
Updated
•
17

This repo was created on September 1st; it's the end of December now. But on the bright side, you guys get not one, but two models! 🙂
(For the "boring technical stuff", you can go to the training details section. In short, I needed to make an adapter, so while at it, I decided to test how far Nemo 12B can be pushed while doing only a deep LoRA, and it turns out quite a lot was possible!)
This is a double release, since I worked on several different things simultaneously. So even though this took more time than I'd like, 2 models instead of one, totally worth it the 4-month wait, eh? and these two piles of tensors couldn't be more different from each other— they are complete opposites. They do share a similar core though, but branched in very different directions.
The "sane and pure one" is Angelic_Eclipse_12B, superb at 'slow-burn'. Production-ready, with robust safety (arguably even safer than stock Mistral Nemo), while retaining full roleplay and creative writing capabilities. In other words, it will give you roleplay freedom, but would steer towards SFW, and would not tell you how to make... some stuff.
Unlike this model.
This is one of the most 'Impish' models of the whole Impish line. Ironically, it might even be more 'Impish' than Impish_Nemo_12B. Imagine that.
Impish_Bloodmoon_12B is an especially wicked one, as I turned the heat to 11 for its innate personality. It has some very interesting capabilities besides just story writing, adventure and roleplay. For example, it could be used to 1-shot roleplay datasets in JSON form directly, and lots of other cool stuff (robust GEC, powerful synonym engine, and many more features that are too many to list, in short, it's a very powerful assistant, specifically for creative tasks). The one-shot dataset creation would prove especially useful for beginner model tuners. This specific capability, along with some others, is only available for this model specifically, and not for its "saner" sister-model.
Impish_Bloodmoon_12B was named this way, in part because I thought: "sheesh, this will probably take a long time to make, probably like... a month or so!", so anyway, 4 months later... (Well, at least the blood part was accurate— 'blood, sweat and tears' and all of that...)
As per usual- improvements to logic, dataset quality, deslopping, more Morrowind, more Fallout, and so on and so forth. In short, it's an absolutely monstrous dataset in terms of tokens trained, it's a generalist with fire flowing throughout its neurons, added multi-lingual support (Russian, Hebrew, Japanese), tons of features, and an innate spicy personality.
A complete overhaul and refinement was undertaken to vastly improve the dataset in:
Oh, and I let a friend meticulously check these capabilities by hand. This example is fully available here. So don't just take my word for it. Do like the Soviets- trust, but verify ☭ (The example was made using the included adventure card, with these Silly Tavern settings)
No editing was done to any of the replies. For the entire run, only up to 5 regens were allowed, start to finish. (in other words, what you see is what you'll get, let's be transparent, dammit 😄)
Have fun! 😈
I am of the firm belief that each model has an innate character, a vibe, and a moral perspective. Not to be fully tinfoil, let us use the proper terms: "World model", through it, the model has an innate understanding of what is reasonable, and this neural wiring directly dictates its tendencies. This behaviour becomes clear at scale, for example, Deepseek V3 is known (in the roleplay community) to be crazy and unhinged (in a good way— for most), Gemma is known to be completely clueless about love and intimate relations. While a certain behaviour can somewhat be prompted, nothing will make Gemma as crazy and unhinged as Deepseek, and vice versa.
Why do I mention this?
In the roleplay and creative writing community, many prefer the 'slow-burn' experience, asking for what cards \ prompts would achieve this. Others ask the opposite: "Why X model is so prude? I tried...", I want fire!
Truth is, while a prompt can nudge here or there, they cannot change the model's innate workins, aka- character, "world model", or whatever you choose to call it. While many like to use the "skill issue" phrase (many times it actually is), in this case, it is not a skill issue. With truly giant models like Kimi K2 or DSV3, due to their sheer scale and generalizing power the prompting can be taken quite far, but even in this case, some "artifacts" of the neural wiring would still be felt, and for sane size models (like in the 4B - 70B range) the prompting for specific behaviour is orders of magnitude both more limited, and harder to do.
With fighting RP, people asked the same, "how can I make a model actually hit me?", and Has anyone had any actual good fight- RP’s?" Same issue. It's the model, not the prompt \ character-card, and in this case, there simply was no model (at a locally sane size, not a 600B moe) that could do this, so I made Impish_Magic_24B.
The same goes for 'slow-burn', you could put a plaster on it, and it will 'sort-of-work-but-not-really'. Some people like to take it slow, some want to go all in; LLMs, trained on "speaking" like humans, are quite similar. The beauty in it is that if someone has a character card he really likes, and one day he wants to go 'all in' with it, and on another day, wants to go all platonic, he can simply use the same character card he is fond of, with no change, and just change the model. Simple (no need to edit anything), and it works far better (even with editing the character card).
Using the same card (whether adventure or roleplay) would produce VASTLY different direction of plot development; It's not merely 'oh, this one uses different words', the whole plot direction (similarly to abliteration) is almost opposite of each other.
Impish_Nemo_12B was a very interesting model (no need to elaborate here; you can read about it in its respective model card), but I got several requests to turn it into an adapter. Problem was, it wasn't a LoRA, and the process of making it was more akin to "sculpting", changing individual layers, merging, CPT, FFT specific projection layers, LoRA...
So, it wasn't possible. I could've used the same data, but the result would be a different model. But if I'm already making a new model, I wanted to recreate many of the things that made Impish_Nemo so loved by the community:
And wanted to add this:
I initially did a DoRA at R=128 (supposedly FFT-like), but I felt like it simply wasn't enough, there was too much stuff to cram into R=128 (multiple languages, new fandoms knowledge), so eventually I settled for RsLoRA at R=256. (Note: from my early experiments, RsLoRA is quite similar to DoRA at R=128, but RsLoRA gets better with higher rank).
The dataset size was absolutely monstrous, about 1.5B - 2B tokens, the most I've trained so far (mainly due to the extra languages, it ate the whole Hebrew Wikipedia, all of it!)
Since I was going for breadth, I needed to make sure that all of this time and compute would work, so I tried to synergize my workflow and the general plan. Was R=256 even enough?
For this, I first trained Hebrew_Nemo, and requested an independent evaluation from the NGO that runs the Hebrew leaderboard. It achieved SoTA status across Hebrew models of similar and \ or larger size (even outperforming models x4 larger by known AI labs, see benchmarks for details), so I knew the learning capacity and scope were possible for the specifications I had in mind. I wasn't completely sure, but... fairly sure. Only one way to find out for certain!
The new language training meant that there 100% will be degradation of instruct and general knowledge, hence the monstrous dataset. (massive amounts of tokens to teach a new language, massive amounts of instruct to compensate for capability loss- because of learning a new language, quite similar to the rocket equation nastyness), I needed to reintroduce solid instruct so the model stays smart. As always, massive amounts of human data were used, my 4chan dataset, and some very old, ah... naughty writings from websites that no longer exist.
It is HIGHLY RECOMMENDED to use the Roleplay \ Adventure format the model was trained on, see the examples below for syntax. It allows for a very fast and easy writing of character cards with minimal amount of tokens. It's a modification of an old-skool CAI style format I call SICAtxt (Simple, Inexpensive Character Attributes plain-text):
X's Persona: X is a .....
Traits:
Likes:
Dislikes:
Quirks:
Goals:
Dialogue example
Adventure: <short description>
$World_Setting:
$Scenario:
Intended use: Role-Play, Adventure, Creative Writing, General Tasks.
Censorship level: Low - Medium
6.5 / 10 (10 completely uncensored)

Recommended settings for assistant mode:
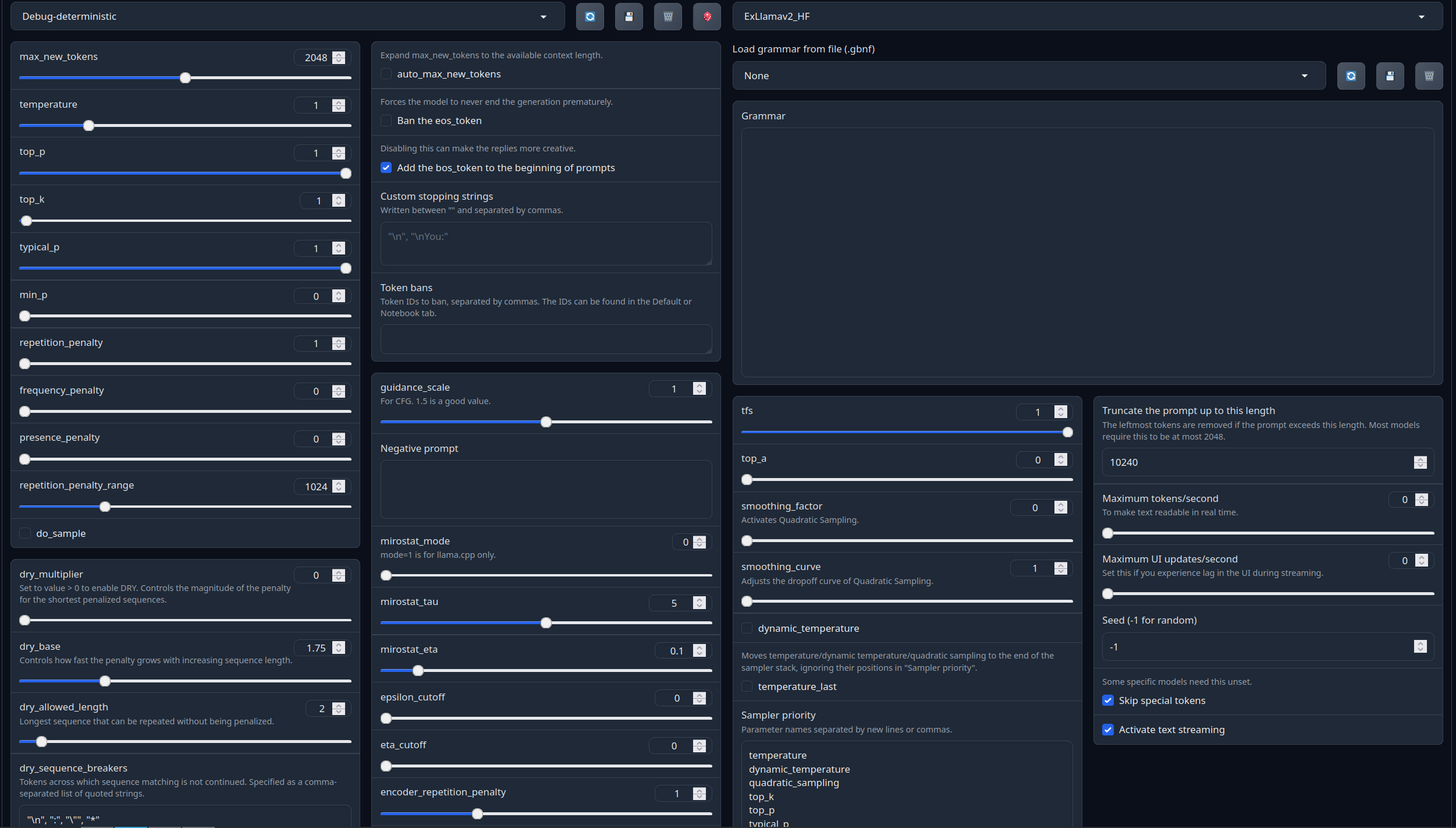
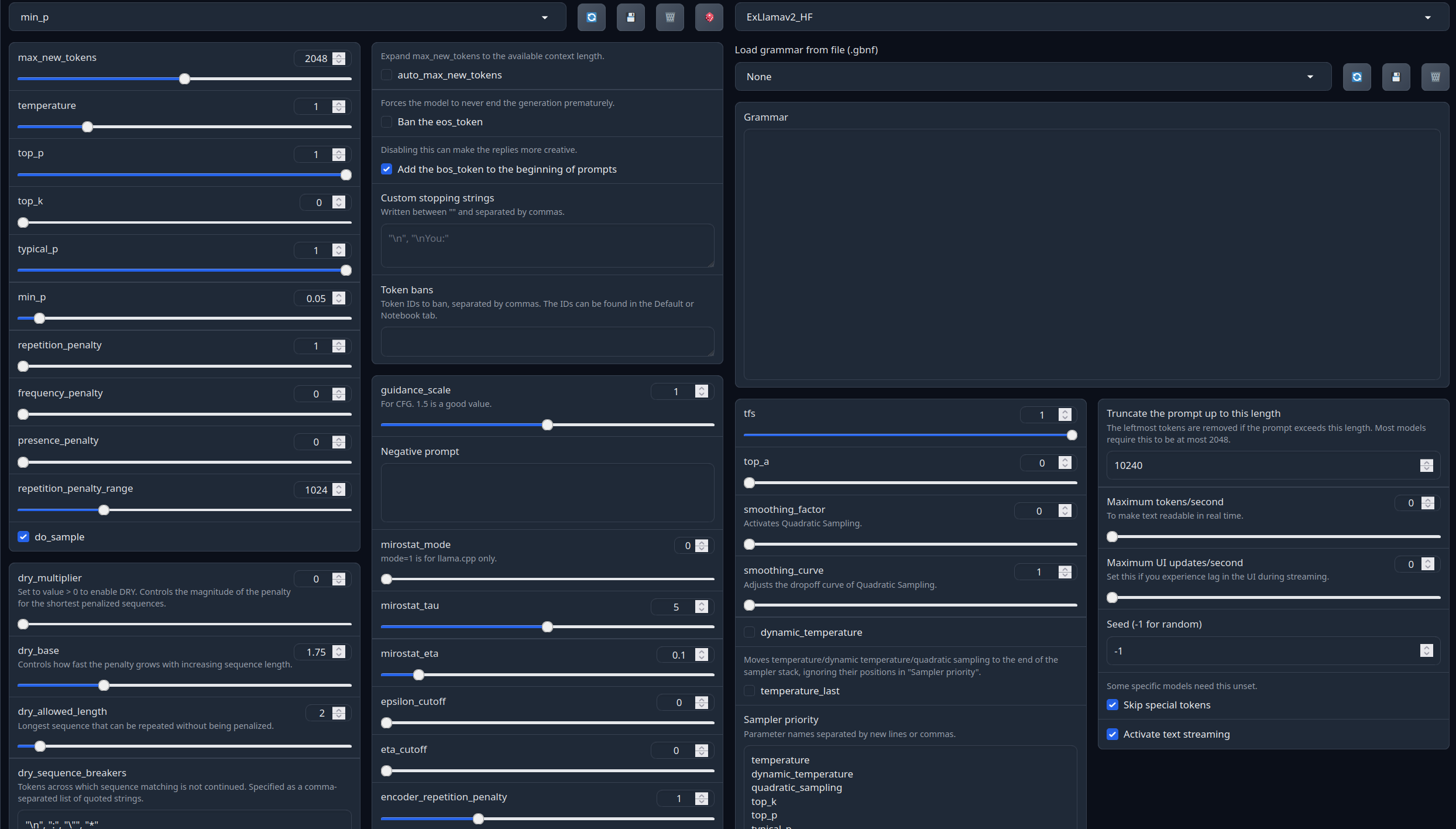

<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
@llm{Impish_Bloodmoon_12B,
author = {SicariusSicariiStuff},
title = {Impish_Bloodmoon_12B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Impish_Bloodmoon_12B}
}
Base model
mistralai/Mistral-Nemo-Base-2407