
Pelican-VL 1.0
Collection
A new family of open-source embodied brain models. • 3 items • Updated
• 2
![]()
📖 Pelican-VL 1.0 Report
| 🤗 Hugging Face
| 🤖 ModelScope
🧰 Quick Start
| 🌐 Project Website
| 🛠️ Evaluation
2025-11-13: Pelican1.0-VL-7B and Pelican1.0-VL-72B model checkpoint has been released in 🤗 Hugging Face Link and 🤖 ModelScope Link.
2025-10-30: We have released the Pelican-VL 1.0 Report. The 7B、72B model for open source is coming soon. For more details, please check our report!
We presents Pelican-VL 1.0, a new family of open-source embodied brain models with parameter scales ranging from 7B to 72B. Pelican-VL 1.0 is currently the largest-scale open-source embodied multimodal brain model. Its core advantage lies in the in-depth integration of data power and intelligent adaptive learning mechanisms.

Multimodal Understanding and Reasoning: Pelican-VL processes both visual and textual inputs, trained on massive datasets of images, videos, and cross-modal annotations. It not only recognizes objects accurately but also performs physical reasoning, spatial relationship understanding, and functional prediction based on scene context. For example, in closed environments like kitchens or supermarkets, it can distinguish the placement of fruits and vegetables, counter locations, and plan picking or placing actions accordingly.
Spatio-Temporal Cognition: The model’s training includes tens of thousands of hours of video and dynamic scene question-answering, enabling it to understand continuous temporal sequences. When processing video frames, Pelican-VL captures object motion and the temporal order of actions, allowing it to make coherent inferences about complex sequential tasks—for instance, determining “which item should be moved first before operating the next.”
Embodied Interaction Capabilities: In robotic tasks such as object grasping, navigation, and collaborative manipulation, Pelican-VL not only understands high-level task goals but also produces detailed action sequences along with feasibility assessments for each step. This means that upon receiving an instruction, the model can determine appropriate grasp points and devise corresponding manipulation strategies. Its multi-task proficiency spans grasping, navigation, and human–robot interaction, demonstrating strong cross-task generalization.
Self-Correction and Iterative Learning: Through DPPO cyclic training, Pelican-VL exhibits a “self-correcting” capability. After each reinforcement learning cycle, the model automatically generates new challenging samples for retraining—similar to repeated practice and reflection. Over time, its weaknesses are gradually addressed, and its abilities continuously improve. This process mirrors the concept of “deliberate practice,” allowing Pelican-VL to advance iteratively and achieve performance on par with top-tier proprietary systems.
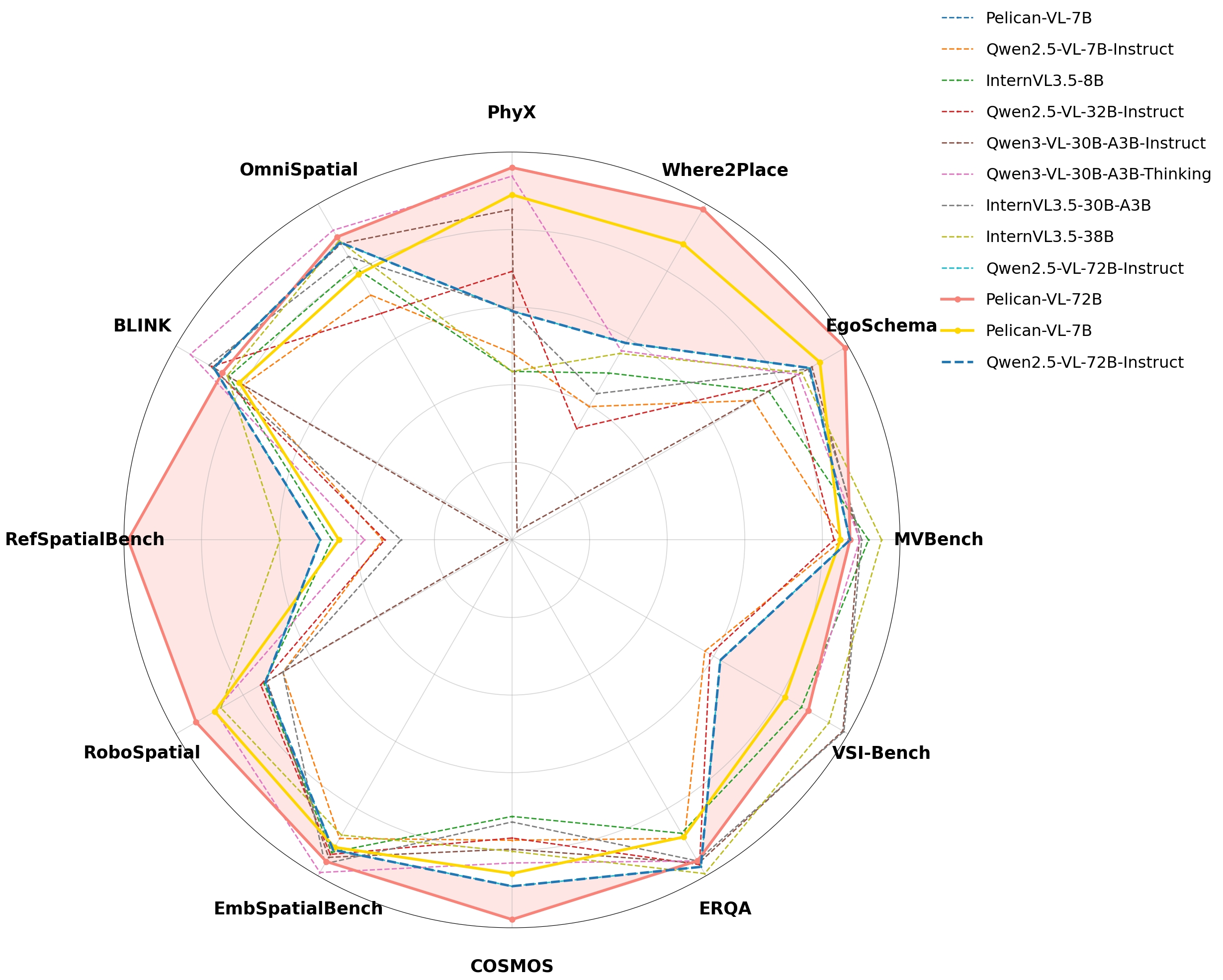
 Performance comparison of Pelican-VL1.0. (Left) Comparison against models with ≤100B parameters. The shaded(pink) region highlights the performance gain over our baseline. (Right) Comparison against models with ≥100B parameters, including leading open-source and proprietary models, where our model also demonstrates SOTA performance.
Performance comparison of Pelican-VL1.0. (Left) Comparison against models with ≤100B parameters. The shaded(pink) region highlights the performance gain over our baseline. (Right) Comparison against models with ≥100B parameters, including leading open-source and proprietary models, where our model also demonstrates SOTA performance.
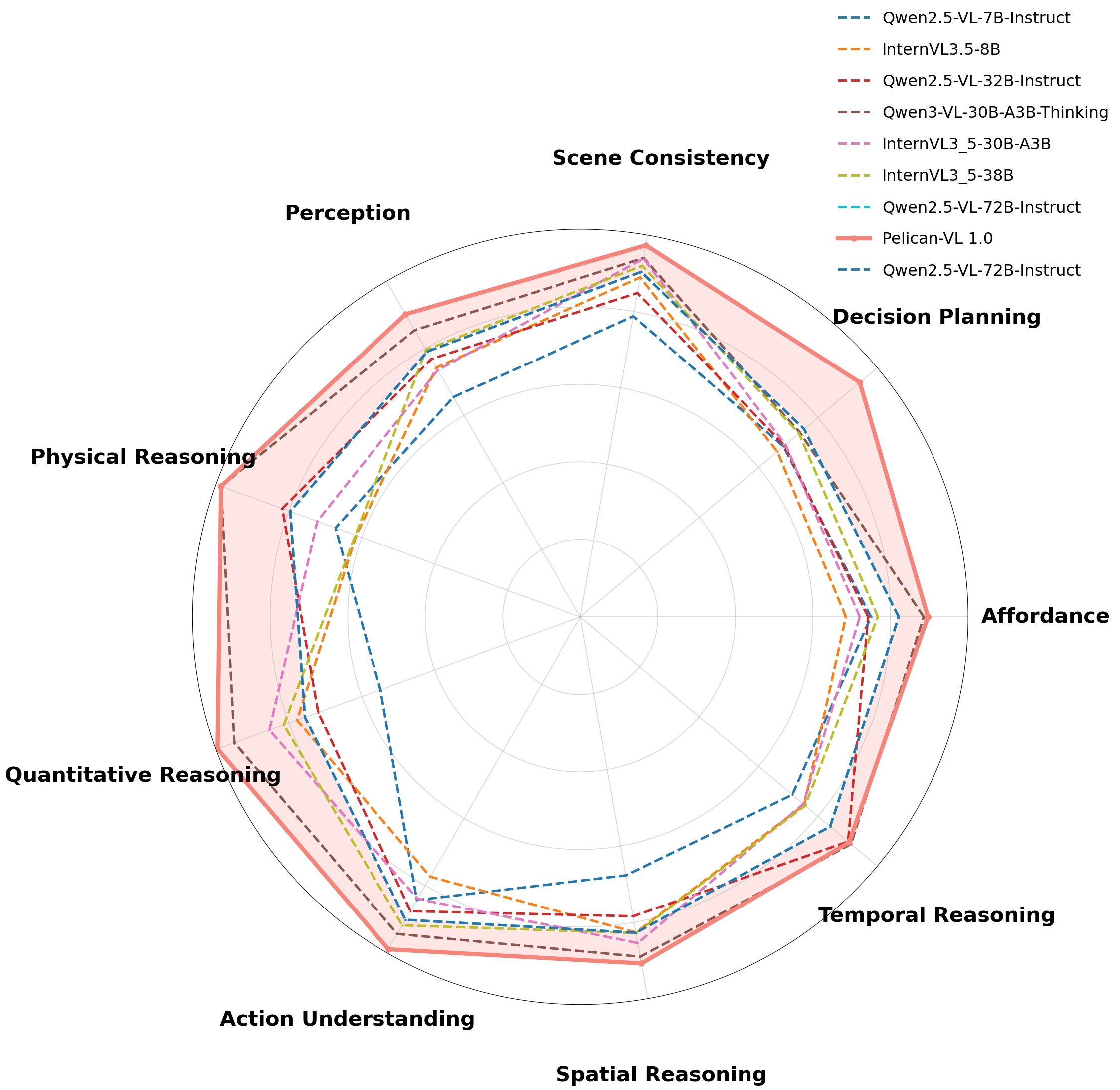
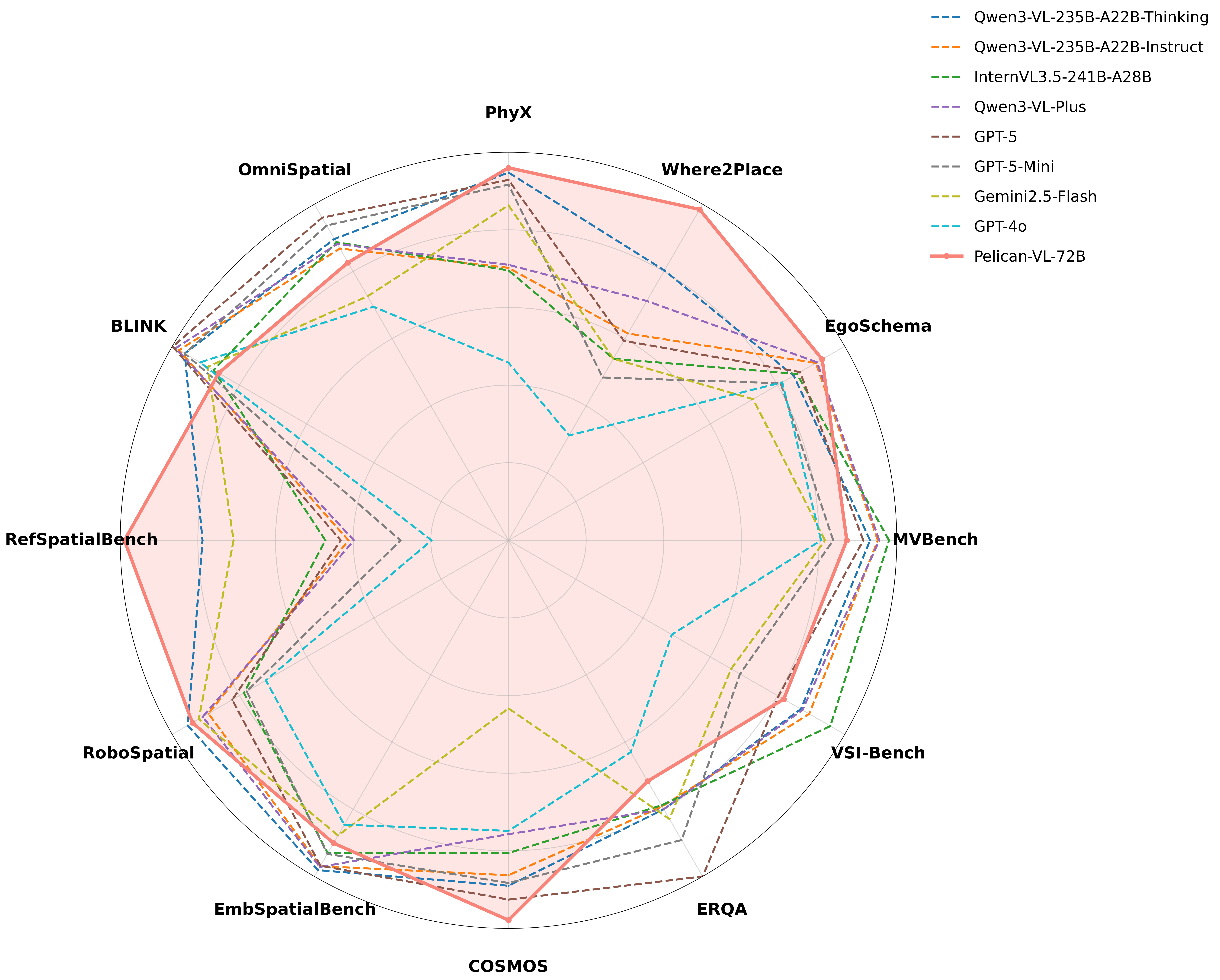
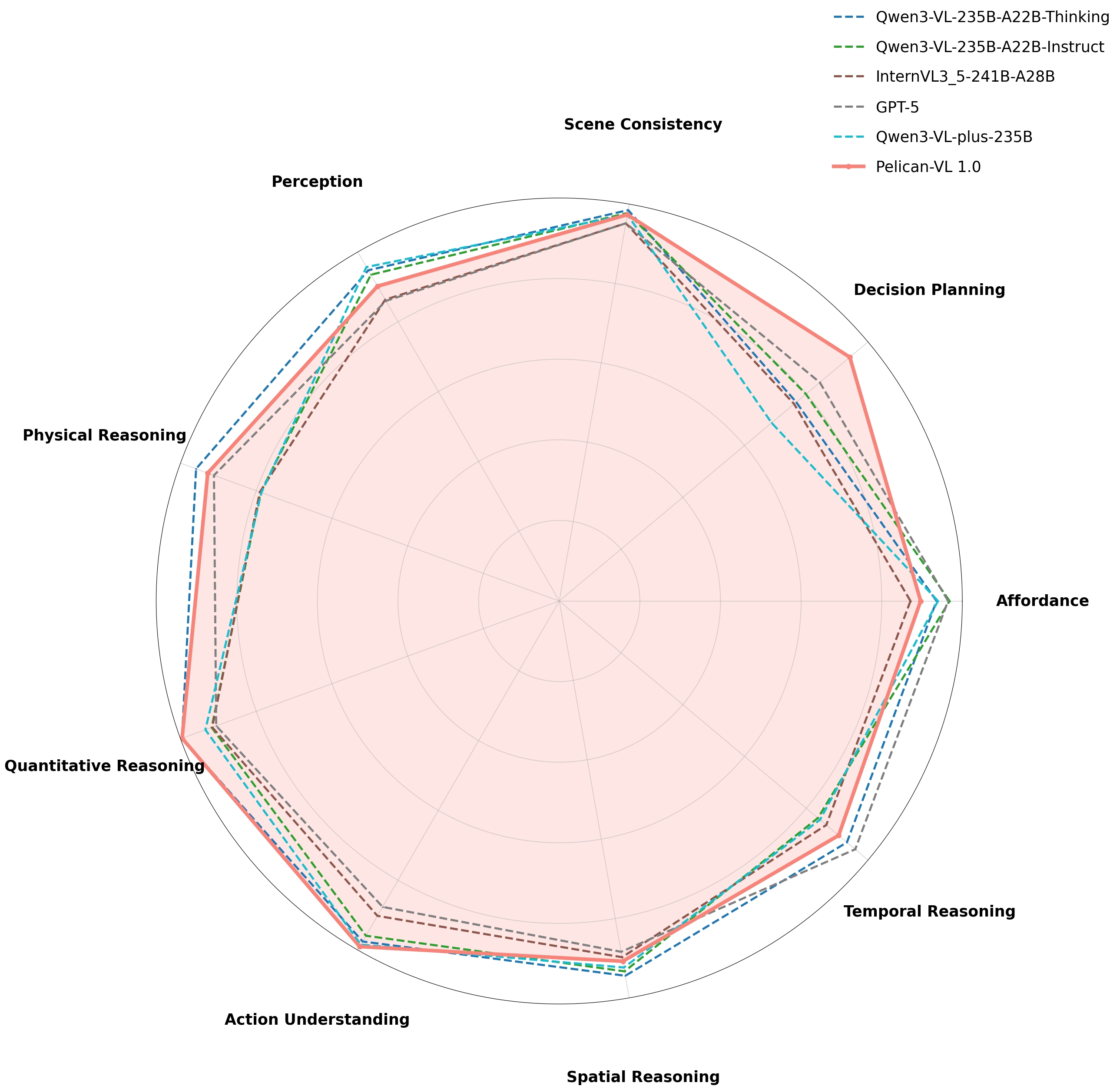 Benchmark performance radar comparison of Pelican-VL 1.0 (72B) against other models across nine dimensions.
Benchmark performance radar comparison of Pelican-VL 1.0 (72B) against other models across nine dimensions.
Please see our project website:🌐 pelican-vl.github.io
We will released our pelican models on 🤗 Hugging Face and 🤖 ModelScope:
| Model Name | Parameters | Checkpoint | Checkpoint |
|---|---|---|---|
| Pelican1.0-VL-7B | 7B | 🤗 Link | 🤖 Link |
| Pelican1.0-VL-72B | 72B | 🤗 Link | 🤖 Link |
Here, We provide you a simple script of LoRa fine-tuning and give you some embodied samples, allowing you to experience how to experiment with embodied data. Training is based on the LLM training and deployment framework Swift.
# pip installation
# pip install ms-swift -U
# Source code installation
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install qwen-vl-utils[decord]==0.0.11 # qwen-vl-utils 0.0.11, decord 0.6.0
pip install deepspeed==0.16.9 # distributed training
pip install wandb # wandb=0.21.0
pip install msgspec
pip install transformers==4.51.1
pip install flash-attn==2.6.1 --no-build-isolation # if GPU supports
Dataset Source
All embodied data used in this demo are JSON files and all derived from public datasets on Hugging Face:
| Dataset Name | Type | Link |
|---|---|---|
| Cosmos Reasoning SFT Data | Video | 🤗 Link |
| Robopoint GQA Data | Image | 🤗 Link |
| VSI-Bench ScanNetpp Data | Video | 🤗 Link |
Download the three datasets from the above links, Place the downloaded files in the local directory(e.g., /datasets/xxx) matching the paths in the JSON (or modify the JSON paths to your local storage path).
# Using an interactive command line for training.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift sft \
--model Qwen2.5-VL-7B-Instruct \
--dataset /datasets/robopoint_example_500.json \
/datasets/vsibench_example_500.json \
/datasets/cosmos_example_500.json \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 2 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 5e-5 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout 0.1 \
--freeze_vit true \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--split_dataset_ratio 0.1 \
--data_seed 42 \
--eval_steps 200 \
--save_strategy epoch \
--logging_steps 1 \
--max_length 8192 \
--output_dir /xxx/output \
--warmup_ratio 0.05 \
--dataloader_num_workers 16 \
--save_only_model True \
--attn_impl flash_attn
After training is complete, use the following command to infer with the trained weights:
--adapters should be replaced with the last checkpoint folder generated during training. Since the adapters folder contains the training parameter file args.json, there is no need to specify --model, --system separately; Swift will automatically read these parameters.# Using an interactive command line for inference.
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
swift infer \
--adapters /xxx/output/checkpoint-xxx \
--stream true \
--infer_backend pt \
--max_new_tokens 2048
For more detailed parameters, please refer to the official documents of Swift .
To facilitate faithful reproduction of our reported results, we summarize our official evaluation settings below.
Please refer to Evaluation.md.
If you find our Pelican-VL useful in your research, please cite:
@article{Pelican-VL-1.0,
title={Pelican-VL 1.0: A Foundation Brain Model for Embodied Intelligence},
author={Yi Zhang, Che Liu, Xiancong Ren, Hanchu Ni, Shuai Zhang, Zeyuan Ding, Jiayu Hu, Hanzhe Shan, Zhenwei Niu, Zhaoyang Liu, Yue Zhao, Junbo Qi, Qinfan Zhang, Dengjie Li, Yidong Wang, Jiachen Luo, Yong Dai, Jian Tang, Xiaozhu Ju},
journal={arXiv preprint arXiv:2511.00108},
year={2025}
}
🗨️ Discussions 🗨️
If you're interested in Pelican-VL, welcome to join our WeChat group for discussions.
