

NorMistral-11b-long is a length-extended version of NorMistral-11b-warm. It has been extended to 32,768 context length by continual training on additional 50 billion subword tokens – using a mix of Scandinavian, Sámi, English and code data (four repetitions of open Norwegian texts). The model follows our earlier paper Small Languages, Big Models: A Study of Continual Training on Languages of Norway by Samuel et al. 2025, and forms part of the NORA.LLM family developed by the Language Technology Group at the University of Oslo (LTG).
Disclaimer: This model is pretrained on raw (mostly web-based) textual data. It is not finetuned to follow instructions, and it can generate harmful completions after inappropriate user prompts. It is primarily intended for research purposes.
License
We release the model under Apache 2.0 license to indicate that we do not impose any additional constraints on the model weights. However, we do not own the data in the training collection.
Pretraining corpus
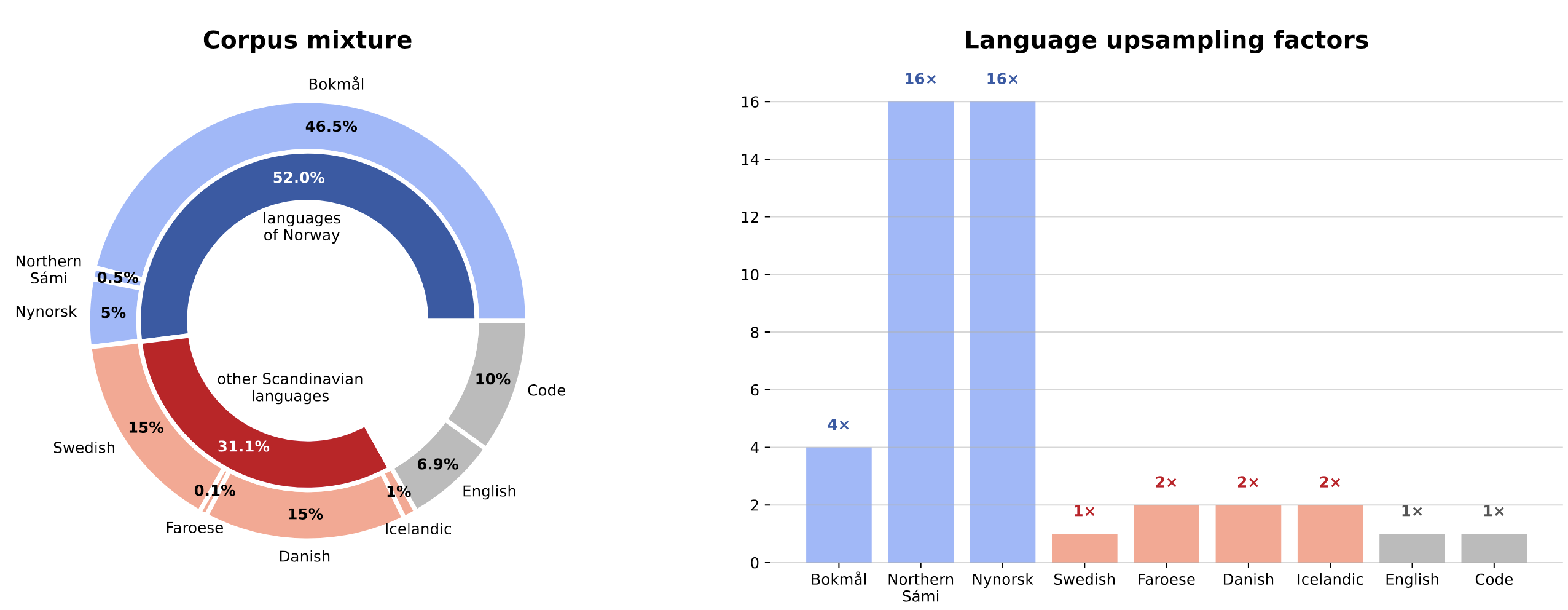
The model is pretrained on a combination of publicly available data and a custom web crawl for Sámi. The total training corpus consists of 250 billion tokens from the following sources:
Norwegian text (Bokmål and Nynorsk); this collection was created by the National Library of Norway and it's a prerelease of an update of NCC (codenamed "Mímir core"). It consists of: a) the public part of Norwegian Colossal Corpus (NCC) with permissible licenses (i.e. it doesn't include newspaper texts with the CC BY-NC 2.0 license); b) Bokmål and Nynorsk CulturaX, and c) Bokmål and Nynorsk HPLT corpus v1.2.
Northern Sámi texts are sourced from a) Glot500; b) the SIKOR North Saami free corpus; and c) a custom web crawl (seeded from Sámi Wikipedia external links) published separately as
ltg/saami-web.Additional languages for knowledge/language transfer: a) Danish, Swedish, Icelandic, and Faroese from CulturaX and Glot500; b) high-quality English from FineWeb-edu; and c) programming code from The Stack v2 (the high-quality subset).
The corpus is carefully balanced through strategic upsampling to handle the resource disparity between languages. Following data-constrained scaling laws, the corpus data for target languages is repeated multiple times (up to 16x for low-resource languages) to reach the optimal training budget while avoiding overfitting:
Tokenizer
This model uses a new tokenizer, specially trained on the target languages. Therefore it offers substantially faster inference than the original Mistral-Nemo-Base-2407 model. Here are the subword-to-word split ratios across different languages:
| Tokenizer | # tokens | Bokmål | Nynorsk | Sámi | Danish | Swedish |
|---|---|---|---|---|---|---|
| Mistral-Nemo-Base-2407 | 131072 | 1.79 | 1.87 | 2.63 | 1.82 | 2.00 |
| NorMistral-11b-long | 51200 | 1.22 | 1.28 | 1.82 | 1.33 | 1.39 |
Model details
Model Developers: Language Technology Group at the University of Oslo in collaboration with NORA.LLM.
Architecture: NorMistral-11B uses the Mistral architecture based on an improved Llama design, featuring:
- Pre-normalization with RMSNorm
- SwiGLU activation function
- Rotary positional embeddings
- Grouped-query attention
- 40 transformer layers
- Hidden dimension: 5,120
- Intermediate dimension: 14,336
- 32 query heads and 8 key & value heads (dimension 128)
- Vocabulary size: 51,200 tokens
- Total parameters: 11.4 billion
Training Details:
- Training tokens: 250 + 50 billion
- Batch size: 128 × 32,768 tokens (# sequences × sequence length)
- Training steps: 12,000
Base Model: Initialized from NorMistral-11b-warm
License: Apache-2.0
Example usage
Basic Causal Language Model Usage
Here's how to use NorMistral-11B as a standard causal language model for translation:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Import the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("norallm/normistral-11b-long")
model = AutoModelForCausalLM.from_pretrained("norallm/normistral-11b-long").cuda().eval()
# Define zero-shot translation prompt template
prompt = """Engelsk: {0}
Bokmål:"""
# Define tokens that should end the generation (any token with a newline)
eos_token_ids = [
token_id
for token_id in range(tokenizer.vocab_size)
if '\n' in tokenizer.decode([token_id])
]
# Generation function
@torch.no_grad()
def generate(text):
text = prompt.format(text)
input_ids = tokenizer(text, return_tensors='pt').input_ids.cuda()
prediction = model.generate(
input_ids,
max_new_tokens=64,
do_sample=False,
eos_token_id=eos_token_ids
)
return tokenizer.decode(prediction[0, input_ids.size(1):]).strip()
# Example usage
generate("I'm excited to try this new Norwegian language model!")
# > Expected output: 'Jeg er spent på å prøve denne nye norske språkmodellen!'
Memory-Efficient Loading
For systems with limited VRAM, you can load the model in 8-bit or 4-bit quantization:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("norallm/normistral-11b-long")
# Load in 8-bit mode (requires ~12GB VRAM)
model = AutoModelForCausalLM.from_pretrained(
"norallm/normistral-11b-long",
device_map='auto',
load_in_8bit=True,
torch_dtype=torch.bfloat16
)
# Or load in 4-bit mode (requires ~8GB VRAM)
model = AutoModelForCausalLM.from_pretrained(
"norallm/normistral-11b-long",
device_map='auto',
load_in_4bit=True,
torch_dtype=torch.bfloat16
)
Citation
@inproceedings{samuel-etal-2025-small,
title = "Small Languages, Big Models: {A} Study of Continual Training on Languages of {Norway}",
author = "Samuel, David and
Mikhailov, Vladislav and
Velldal, Erik and
{\O}vrelid, Lilja and
Charpentier, Lucas Georges Gabriel and
Kutuzov, Andrey and
Oepen, Stephan",
editor = "Johansson, Richard and
Stymne, Sara",
booktitle = "Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025)",
month = mar,
year = "2025",
address = "Tallinn, Estonia",
publisher = "University of Tartu Library",
url = "https://aclanthology.org/2025.nodalida-1.61/",
pages = "573--608",
ISBN = "978-9908-53-109-0",
}
Contact
Please write a community message or contact David Samuel ([email protected]) if you have any questions about this model.
- Downloads last month
- 472