
AI Detector LoRA (DeBERTa-v3-large)
LoRA adapter for binary AI-text vs Human-text detection, trained on ~2.3M English samples
(label: 1 = AI, 0 = Human) using microsoft/deberta-v3-large as the base model.
- Base model:
microsoft/deberta-v3-large - Task: Binary classification (AI vs Human)
- Head: Single-logit +
BCEWithLogitsLoss - Adapter type: LoRA (
peft) - Hardware: H100 SXM, bf16, multi-GPU
- Final decision threshold: 0.9284 (max-F1 on calibration set)
Files in this repo
adapter/– LoRA weights saved withpeft_model.save_pretrained(...)merged_model/– fully merged model (base + LoRA) for standalone usethreshold.json– chosen deployment threshold and validation F1calibration.json– temperature scaling parameters and calibration metricsresults.json– hyperparameters, validation threshold search, test metricstraining_log_history.csv– raw Trainer log historypredictions_calib.csv– calibration-set probabilities and labelspredictions_test.csv– test probabilities and labelsfigures/– training and evaluation plotsREADME.md– this file
Metrics (test set)
Using threshold 0.9284:
| Metric | Value |
|---|---|
| AUROC | 0.9979 |
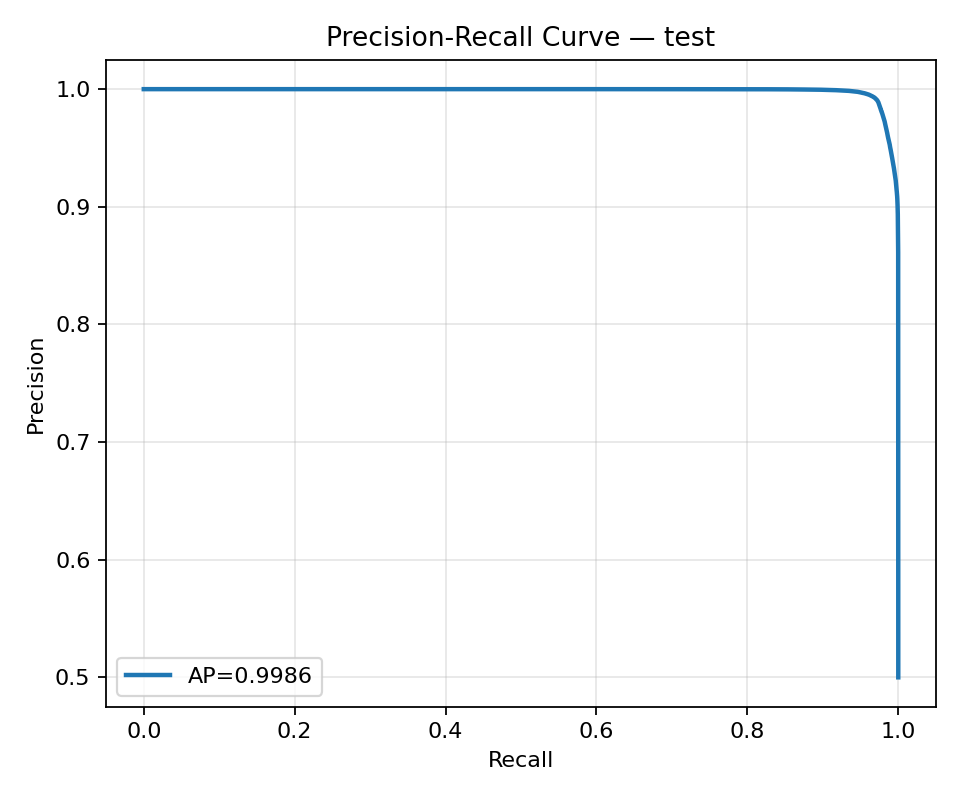
| Average Precision (AP) | 0.9977 |
| F1 | 0.9773 |
| Accuracy | 0.9797 |
| Precision | 0.9909 |
| Recall | 0.9640 |
| Specificity | 0.9927 |
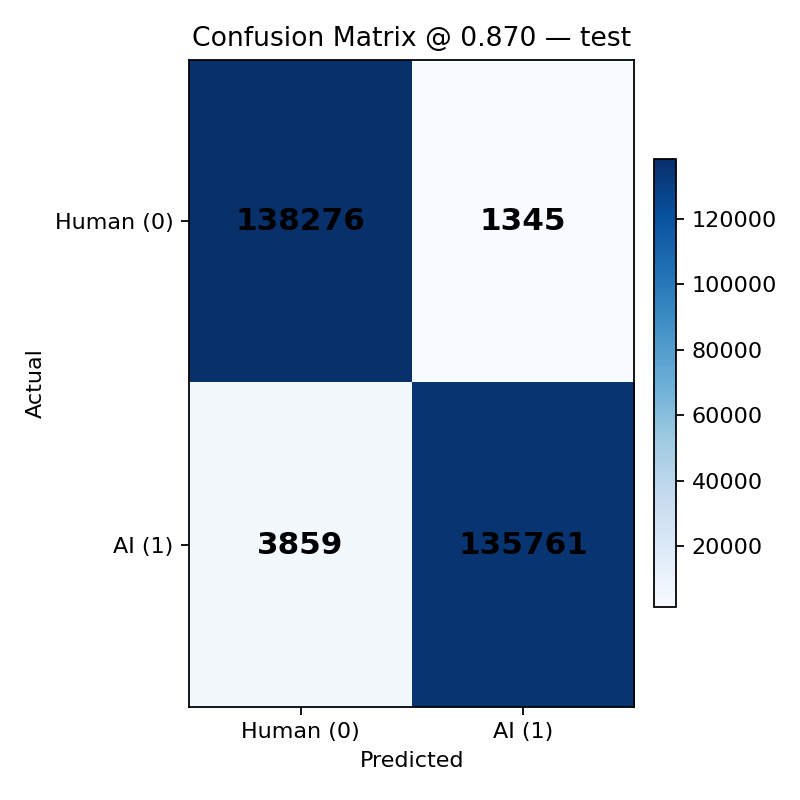
Confusion matrix (test):
- True Negatives (Human correctly): 123,936
- False Positives (Human → AI): 912
- False Negatives (AI → Human): 3,723
- True Positives (AI correctly): 99,816
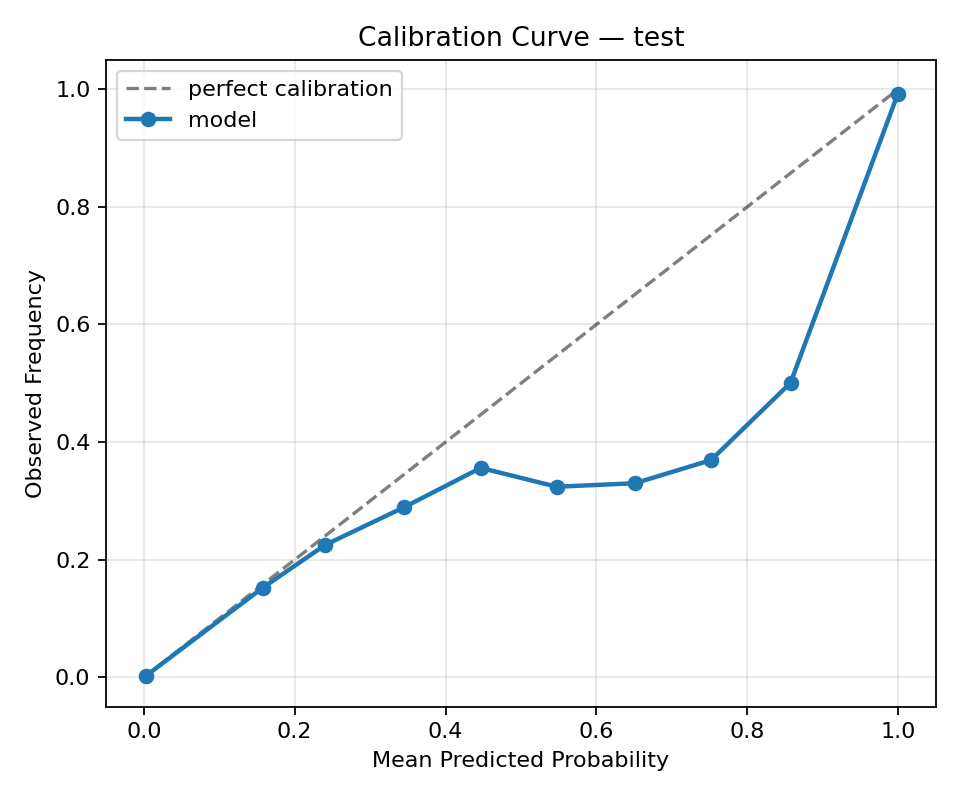
Calibration
- Method: temperature scaling
- Temperature (T): 1.2807
- Calibration set: calibration
- Test ECE: 0.0119 → 0.0159 (after calibration)
- Test Brier: 0.01812 → 0.01829 (after calibration)
Plots
Training & validation
Learning curves:

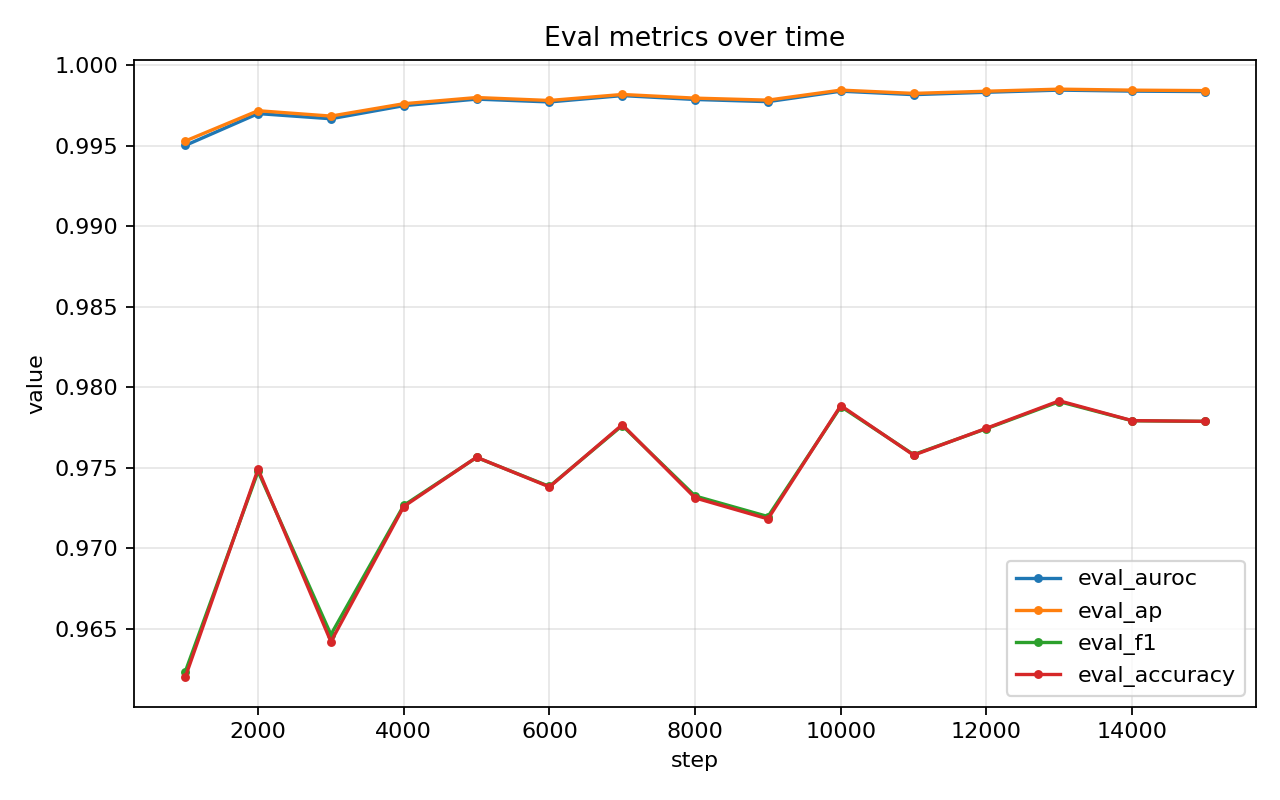
Eval metrics over time:


Validation set
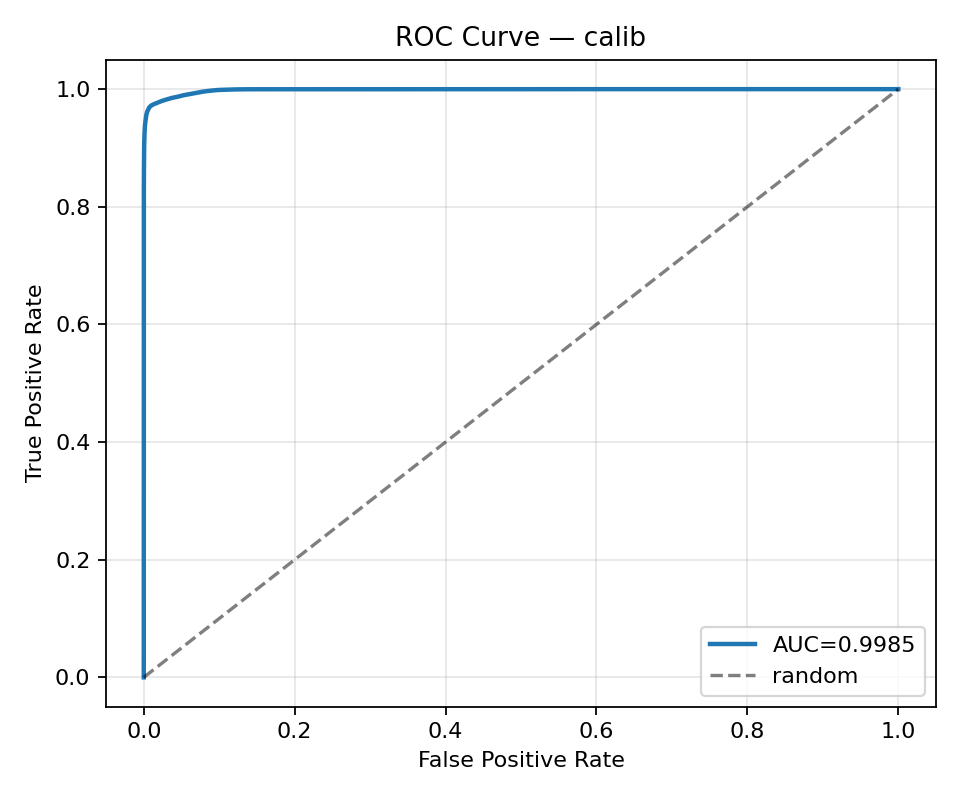
ROC:
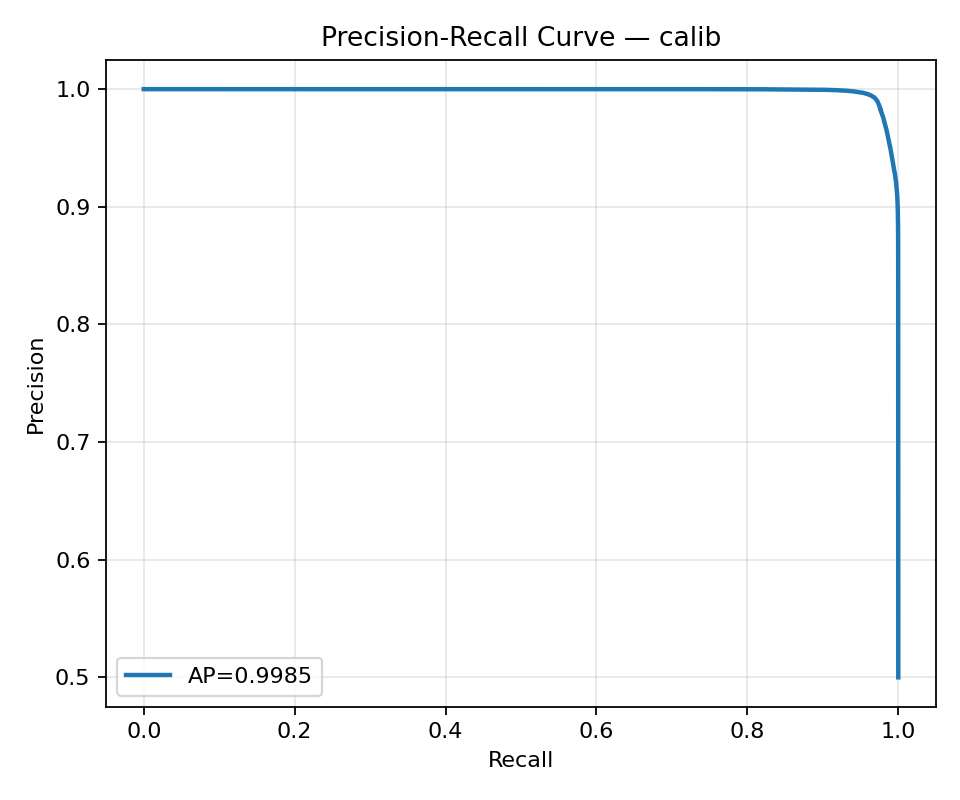
Precision–Recall:
Calibration curve:

F1 vs threshold:





Test set
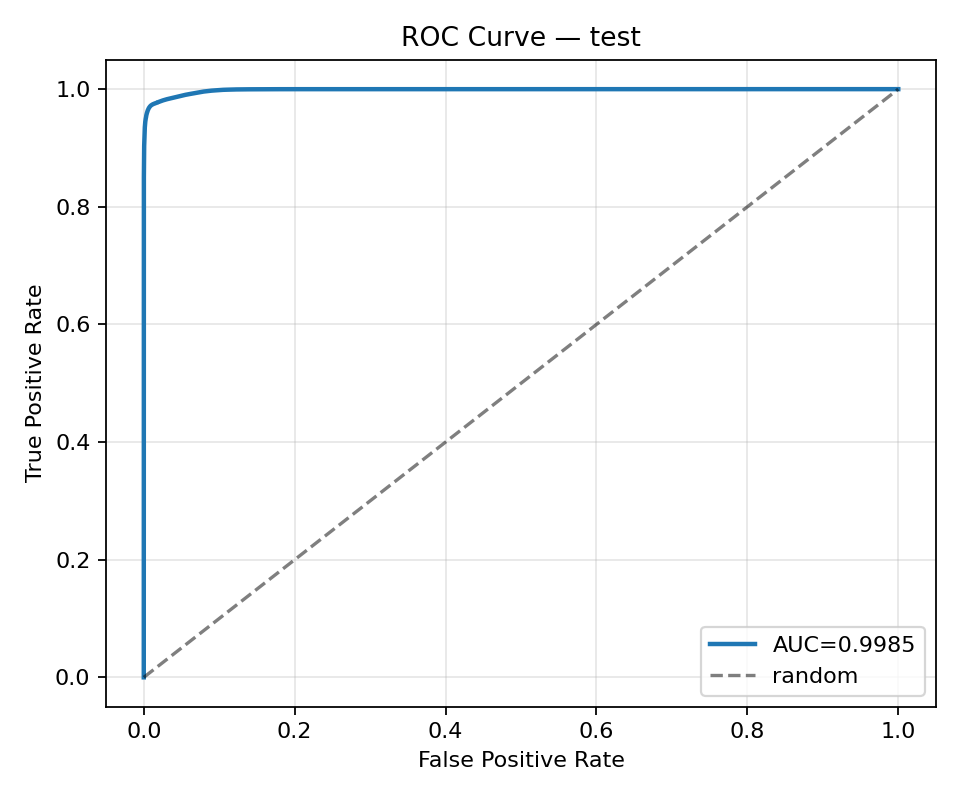
ROC:
Precision–Recall:
Calibration curve:
Confusion matrix:




Usage
Load base + LoRA adapter
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from peft import PeftModel
import torch
import json
base_model_id = "microsoft/deberta-v3-large"
adapter_id = "stealthcode/ai-detection" # or local: "./adapter"
tokenizer = AutoTokenizer.from_pretrained(base_model_id)
base_model = AutoModelForSequenceClassification.from_pretrained(
base_model_id,
num_labels=1, # single logit for BCEWithLogitsLoss
)
model = PeftModel.from_pretrained(base_model, adapter_id)
model.eval()
Inference with threshold
# load threshold
with open("threshold.json") as f:
thr = json.load(f)["threshold"] # 0.9284
def predict_proba(texts):
enc = tokenizer(
texts,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
with torch.no_grad():
logits = model(**enc).logits.squeeze(-1)
probs = torch.sigmoid(logits)
return probs.cpu().numpy()
def predict_label(texts, threshold=thr):
probs = predict_proba(texts)
return (probs >= threshold).astype(int)
# example
texts = ["Some example text to classify"]
probs = predict_proba(texts)
labels = predict_label(texts)
print(probs, labels) # label 1 = AI, 0 = Human
Load merged model (no PEFT required)
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch, json
model_dir = "./merged_model"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSequenceClassification.from_pretrained(model_dir)
model.eval()
with open("threshold.json") as f:
thr = json.load(f)["threshold"] # 0.9284
def predict_proba(texts):
enc = tokenizer(texts, padding=True, truncation=True, max_length=512, return_tensors="pt")
with torch.no_grad():
logits = model(**enc).logits.squeeze(-1)
probs = torch.sigmoid(logits)
return probs.cpu().numpy()
Optional: apply temperature scaling to logits
import json
with open("calibration.json") as f:
T = json.load(f)["temperature"] # e.g., 1.2807
def predict_proba_calibrated(texts):
enc = tokenizer(texts, padding=True, truncation=True, max_length=512, return_tensors="pt")
with torch.no_grad():
logits = model(**enc).logits.squeeze(-1)
probs = torch.sigmoid(logits / T)
return probs.cpu().numpy()
Notes
Classifier head is trainable together with LoRA layers (unfrozen after applying PEFT).
Training used:
bf16=Trueoptim="adamw_torch_fused"- cosine-with-restarts scheduler
- LR scaled down from HPO to account for full-dataset (~14k steps).
Threshold
0.9284was chosen as the max-F1 point on the calibration set. You can adjust it if you prefer fewer false positives or fewer false negatives.
- Downloads last month
- -
Model tree for stealthcode/ai-detection
Base model
microsoft/deberta-v3-large