
TowerVision
Collection
Extending Tower capabilities to the vision modality • 4 items • Updated • 2

TowerVision is a family of open-source multilingual vision-language models with strong capabilities optimized for a variety of vision-language use cases, including image captioning, visual understanding, summarization, question answering, and more. TowerVision excels particularly in multimodal multilingual translation benchmarks and culturally-aware tasks, demonstrating exceptional performance across 20 languages and dialects.
This model card covers the TowerVision family, including the 2B and 9B parameter versions, both in their instruct-tuned (it) and pretrained (pt) variants, with the latter not undergoing instruction tuning.
🌟 Try TowerVision: Project Page | Code Repository
| Model | Parameters | HF Link |
|---|---|---|
| TowerVision-2B | 2B | 🤗 utter-project/TowerVision-2B |
| TowerVision-9B | 9B | 🤗 utter-project/TowerVision-9B |
When using the model, make sure your prompt is formated correctly! Also, we recommend using bfloat16 rather than fp32/16
from transformers import (
LlavaNextProcessor,
LlavaNextForConditionalGeneration
)
import requests
from PIL import Image
model_id = "utter-project/TowerVision-2B" # or any other variant
def prepare_prompt(query):
conversation = [
{
"role": "user",
"content": f"<image>\n{query}"
}
]
# Format message with the towervision chat template
prompt = processor.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True
)
return prompt
# we recommend using "bfloat16" as torch_dtype
kwargs = {
"torch_dtype": "bfloat16",
"device_map": "auto",
}
processor = LlavaNextProcessor.from_pretrained(model_id)
model = LlavaNextForConditionalGeneration.from_pretrained(model_id, **kwargs)
# img url
img_url = "https://cms.mistral.ai/assets/a10b924e-56b3-4359-bf6c-571107811c8f"
image = Image.open(requests.get(img_url, stream=True).raw)
# Multilingual prompts - TowerVision supports 20+ languages!
prompt = prepare_prompt("Is this person really big, or is this building just super small?")
# Prepare inputs
inputs = processor(
text=prompt, images=image, return_tensors="pt"
).to(model.device)
# Generate response ids
gen_tokens = model.generate(**inputs, max_new_tokens=512)
# Decode response
print(processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True))
For processing multiple images and prompts simultaneously:
def prepare_prompts(queries):
prompts = []
for query in queries:
conversation = [
{
"role": "user",
"content": f"<image>\n{query}"
}
]
# Format message with the towervision chat template
prompt = processor.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True
)
prompts.append(prompt)
return prompts
# we recommend using "bfloat16" as torch_dtype
kwargs = {
"torch_dtype": "bfloat16",
"device_map": "auto",
}
processor = LlavaNextProcessor.from_pretrained(model_id)
model = LlavaNextForConditionalGeneration.from_pretrained(model_id, **kwargs)
# Sample images and queries for batch processing
img_urls = [
"https://cms.mistral.ai/assets/a10b924e-56b3-4359-bf6c-571107811c8f",
"https://cms.mistral.ai/assets/a10b924e-56b3-4359-bf6c-571107811c8f",
]
queries = [
"Is this person really big, or is this building just super small?",
"Where was this photo taken?"
]
# Load images
images = []
for url in img_urls[:batch_size]:
image = Image.open(requests.get(url, stream=True).raw)
images.append(image)
# Prepare prompts
prompts = prepare_prompts(queries[:batch_size])
# Prepare batch inputs
inputs = processor(
text=prompts,
images=images,
return_tensors="pt",
padding=True
).to(model.device)
# Generate response ids for batch
gen_tokens = model.generate(**inputs, max_new_tokens=512, do_sample=False)
# Decode responses
print(f"Batch processing {len(images)} images:")
print("-" * 50)
for i in range(len(images)):
input_length = inputs.input_ids[i].shape[0]
response = processor.tokenizer.decode(
gen_tokens[i][input_length:],
skip_special_tokens=True
)
print(f"Response: {response}")
print("-" * 50)
from transformers import pipeline
from PIL import Image
import requests
pipe = pipeline(
model="utter-project/TowerVision-9B",
task="image-text-to-text",
device_map="auto",
dtype="bfloat16"
)
def prepare_prompt(query):
conversation = [
{
"role": "user",
"content": f"<image>\n{query}"
}
]
# Format message with the towervision chat template
return pipe.processor.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True
)
img_url = "https://cms.mistral.ai/assets/a10b924e-56b3-4359-bf6c-571107811c8f"
image = Image.open(requests.get(img_url, stream=True).raw)
text = prepare_prompt("Is this person really big, or is this building just super small?")
outputs = pipe(text=text, images=image, max_new_tokens=300, return_full_text=False)
print(outputs)
Input: Model accepts input text and images.
Output: Model generates text in multiple languages.
Model Architecture: TowerVision uses a multilingual language model based on Tower-Plus (2B and 9B parameters), paired with SigLIP2-patch14-384 vision encoder through a multimodal adapter for vision-language understanding.
Recommended Precision: We recommend using bfloat16 precision for optimal performance and memory efficiency when running TowerVision models.
Languages Covered: The model has been trained on 20 languages and dialects:
Key Strengths:
TowerVision models are trained on VisionBlocks, a comprehensive multilingual vision-language dataset comprising 6.31M samples across diverse categories:
| Dataset | Samples | HF Link | |
|---|---|---|---|
| VisionBlocks | 6.31M | 🤗 utter-project/VisionBlocks | Coming Soon |
VisionBlocks contains samples across multiple categories with both English-only (63.1%) and multilingual (36.9%) data:
Collection Types: Human-annotated, synthetically generated, and professionally translated data ensuring high quality and cultural diversity across 20+ languages.
All evaluations were conducted using lmms_eval.
TowerVision demonstrates strong performance across diverse multimodal evaluation benchmarks:

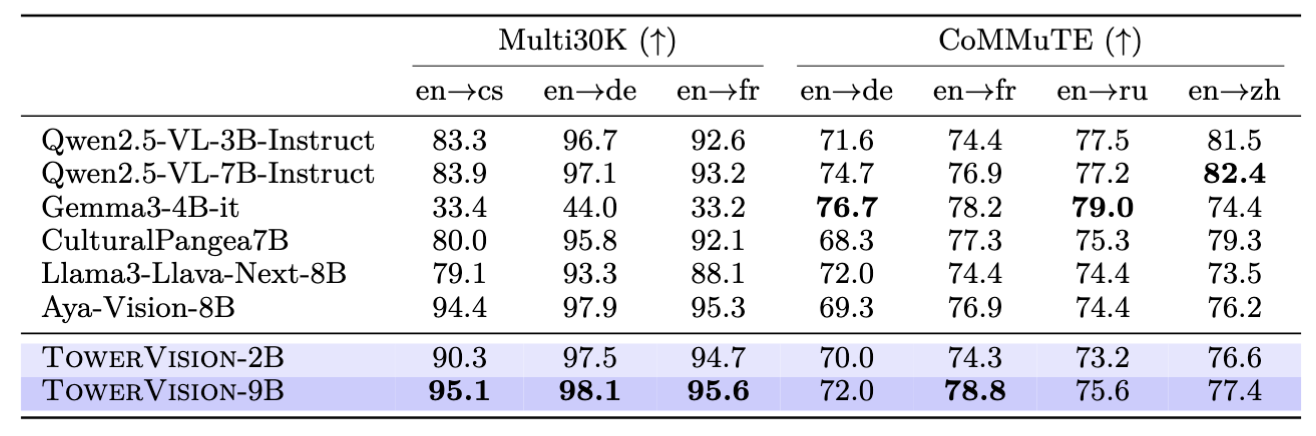
TowerVision excels particularly in multimodal multilingual translation benchmarks, demonstrating state-of-the-art cross-lingual visual communication capabilities:
✅ Fully Supported: English, German, Dutch, Spanish, French, Portuguese, Italian, Polish, Czech, Romanian, Norwegian, Chinese, Japanese, Korean, Hindi, Russian, Ukrainian
📊 Benchmark Coverage: Our models are evaluated across diverse multilingual vision-language tasks, demonstrating strong cross-lingual transfer capabilities and exceptional performance in culturally-aware benchmarks.
If you find TowerVision useful in your research, please consider citing the following paper:
@misc{viveiros2025towervisionundermstandingimprovingmultilinguality,
title={TowerVision: Understanding and Improving Multilinguality in Vision-Language Models},
author={André G. Viveiros and Patrick Fernandes and Saul Santos and Sonal Sannigrahi and Emmanouil Zaranis and Nuno M. Guerreiro and Amin Farajian and Pierre Colombo and Graham Neubig and André F. T. Martins},
year={2025},
eprint={2510.21849},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.21849},
}
For errors or additional questions about details in this model card, contact the research team.
TowerVision builds upon the excellent work of: